和《详细通俗的思路分析,多解法》解法相同,该文章已经写得很清晰了,就不再赘述,但是这个算法处理了很多不必要的位置。因为在最终匹配的解里面一定含有words[0],那么先用O(n)时间(可以用kmp)找到所有的可能位置,然后对该位置使用滑动窗口即可,耗时为链接中算法的1/4左右,尽管在leetcode测试中笔者耗时为他的三倍多,但是数据量大才能有效地说明算法的效率问题
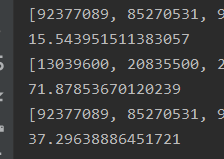
分别在1kw长度,20个words,words[0]长度1000,字符种类50
和1e长度,20个words,words[0]长度10000,字符种类50
下测的的结果,第一个为笔者的运行时间,单位s

代码写的比较乱,能知道增加部分的含义就行
1 class Solution(object): 2 def findSubstring(self, s, words): 3 if not words: 4 return [] 5 if not words[0]: 6 return [i for i in range(len(s) + 1)] 7 if len(s) < len(words) * len(words[0]): 8 return [] 9 10 set_word = {} 11 for i in words: 12 if i in set_word: 13 set_word[i] += 1 14 else: 15 set_word.update({i: 1}) 16 len_word = len(words[0]) 17 len_s = len(s) 18 words_num = len(words) 19 20 arry = [] 21 index = s.find(words[0]) 22 while index != -1: 23 arry.append(index) 24 index = s.find(words[0], index + 1) 25 # print(arry) 26 27 ans = set() 28 next_start = -1 29 for num in arry: 30 start = num - len_word * (words_num - 1) 31 if num >= next_start - 1: 32 ans_temp, next_start = self.is_match(s, set_word, len_word, len_s, words_num, start, num) 33 ans |= ans_temp 34 35 # print(list(ans)) 36 return list(ans) 37 38 def is_match(self, s, set_word, len_word, len_s, words_num, start, end): 39 ans = set() 40 offset = 0 41 cache = set_word.copy() 42 word_list = [] 43 next_start = -1 44 while start + (words_num - len(word_list)) * len_word <= len_s and start <= end + len(word_list) * len_word: 45 if start >= 0: 46 same = 0 47 for i in range(words_num - len(word_list)): 48 this_word = "" 49 for j in range(len_word): 50 this_word += s[start + i * len_word + j] 51 if this_word in cache: 52 if cache[this_word] > 0: 53 word_list.append(this_word) 54 cache[this_word] -= 1 55 elif this_word == word_list[0]: 56 same = 1 57 start += len_word * len(word_list) 58 offset = len_word * (len(word_list) - 1) 59 word_list.pop(0) 60 cache[this_word] += 1 61 break 62 else: 63 break 64 else: 65 break 66 67 if not same: 68 flag = 0 69 for i in cache: 70 if cache[i] > 0: 71 flag = 1 72 break 73 if flag: 74 if word_list: 75 for i in range(len(word_list)): 76 start += len_word 77 this_word = word_list.pop(0) 78 cache[this_word] += 1 79 else: 80 start += len_word 81 cache = set_word.copy() 82 offset = 0 83 else: 84 ans.add(start - offset) 85 start += len_word * words_num 86 offset = len_word * (words_num - 1) 87 this_word = word_list.pop(0) 88 cache[this_word] += 1 89 next_start = start - offset 90 else: 91 start += len_word 92 return ans, next_start