“这篇博客主要分享一个数据分析初级项目,基本概括了一个完整项目的各个分析阶段,但是数据获取是直接在链家官网爬取的,这部分先不分享了。过程中还有很多不足的地方,希望各位大佬多多指点。”
1.数据预处理
首先导入科学计算包
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
from IPython.display import display
plt.style.use('fivethirtyeight')
sns.set_style({'font.sans-serif':['simhei','Arial']})
%matplotlib inline
读取数据,对数据进行初步观察,查看缺失值和异常值,并进行描述性统计
#导入数据,查看前三行
lianjia_df = pd.read_csv("C:\Jupyter_working_path\Projects\lianjia.csv")
display(lianjia_df.head(3))

初步观察到有11个特征变量,Price为目标变量
#检查缺失值情况
#检查缺失值情况
lianjia_df.info()
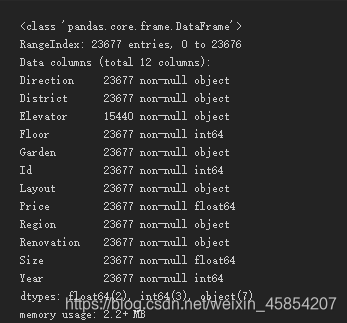
很明显Elevator特征有缺失值
#描述性统计
lianjia_df.describe()
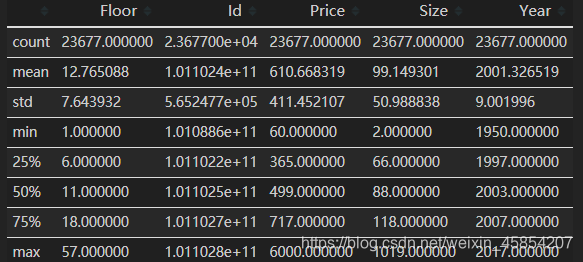
可见,size特征最大值1019平米,最小值2平米
#添加房屋特征均价
df = lianjia_df.copy()
df['PerPrice'] = lianjia_df['Price']/lianjia_df['Size']
#重新摆放列位置
columns = ['Region','District','Garden','Layout','Floor','Year','Size','Elevator','Direction','Renovation','PerPrice','Price']
df = pd.DataFrame(df, columns = columns)
#重新审视数据集
display(df.head(3))

2.特征分析
接下来对特征变量进行逐一分析
(1)Region特征分析
#对二手房区域分组对比二手房数量和每平方米房价
df_house_count = df.groupby('Region')['Price'].count().sort_values(ascending=False).to_frame().reset_index()
df_house_mean = df.groupby('Region')['PerPrice'].mean().sort_values(ascending=False).to_frame().reset_index()
f,[ax1,ax2,ax3] = plt.subplots(3,1,figsize=(20,15))
sns.barplot(x = 'Region', y = 'PerPrice', palette = "Blues_d", data=df_house_mean, ax=ax1)
ax1.set_title('北京各区二手房每平米单价对比',fontsize=15)
ax1.set_xlabel('区域')
ax1.set_ylabel('每平米价格')
sns.barplot(x='Region', y='Price',palette = "Greens_d", data= df_house_count, ax = ax2)
ax2.set_title('北京各区二手房每平米数量对比',fontsize=15)
ax2.set_xlabel('区域')
ax2.set_ylabel('数量')
sns.boxplot(x='Region', y='Price', data= df, ax = ax3)
ax2.set_title('北京各区二手房房屋总价',fontsize=15)
ax2.set_xlabel('区域')
ax2.set_ylabel('房屋总价')
plt.savefig("C:\Jupyter_working_path\Projects\picture")
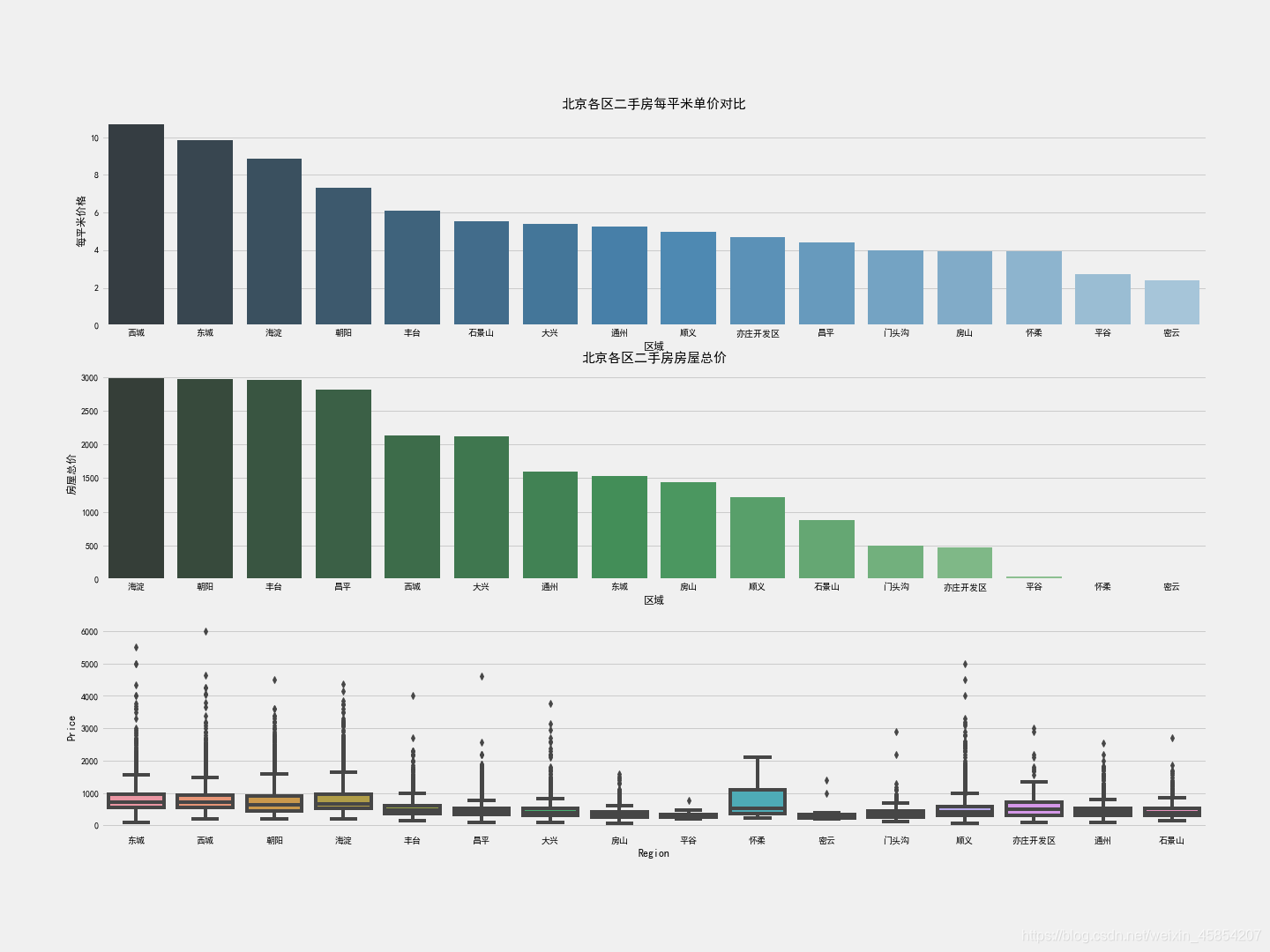
区域特征可视化过程直接采用seaborn来完成,颜色使用调色板palette参数,渐变,越浅表示越少。
可见: 1)二手房均价:西城区房价最贵大约11万/平,其次是东城大约10万/平,然后海淀区8.5万/平,其他地方均低于8万/平;
2)二手房数量:海淀区和朝阳区二手房数量最多,需求量也大。
3)二手房总价:各大区域总价中位数都在1000万以下,西城达到6000万。
(2)Size特征分析
f, [ax1,ax2] = plt.subplots(1,2,figsize=(15,5))
#建房时间分布情况
sns.distplot(df['Size'], bins = 20, ax=ax1, color='r')
sns.kdeplot(df['Size'], shade=True, ax =ax1)
#建房时间和出售价格的关系
sns.regplot(x ='Size', y='Price',data=df, ax=ax2)
plt.savefig("C:\Jupyter_working_path\Projects\pictures")
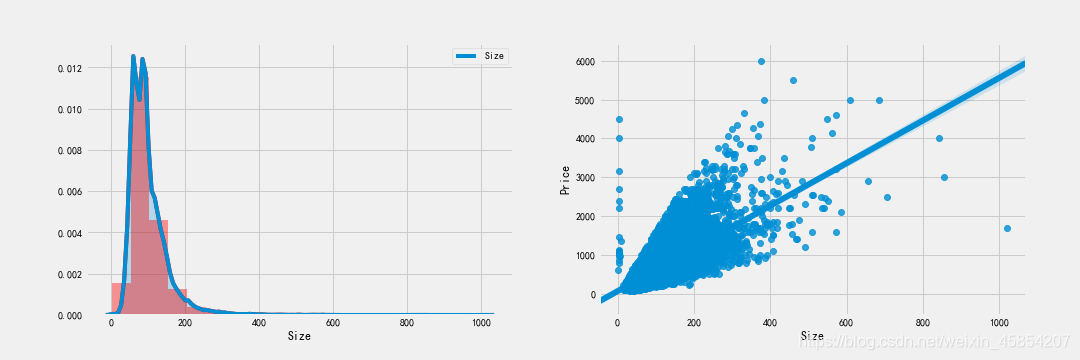
#探索Size和price的关系
通过regplot绘制size和price之间的散点图,发现size特征基本和price特征程线性关系,即房屋越大价格越贵。但有明显的异常点需要进一步观察:
df.loc[df['Size']<10]
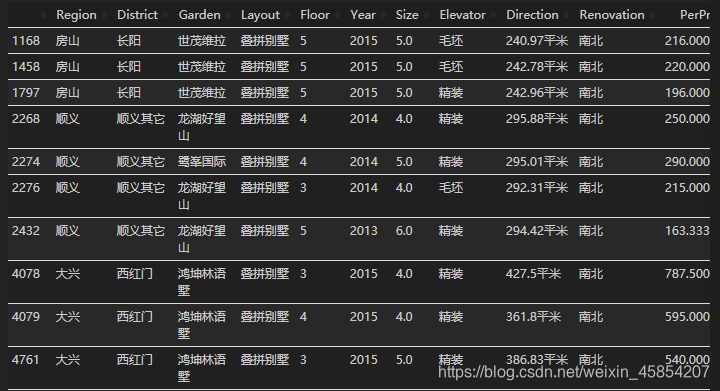
df.loc[df['Size']>1000]

df=df[(df['Layout']!='叠拼别墅') & (df['Size']<1000)]
(3)Layout特征分析
f, ax1 = plt.subplots(figsize=(20,20))
sns.countplot(y='Layout', data = df, ax=ax1)
ax1.set_title('房屋户型',fontsize=15)
ax1.set_xlabel('数量')
ax1.set_ylabel('户型')
plt.savefig("C:\Jupyter_working_path\Projects\picture1")
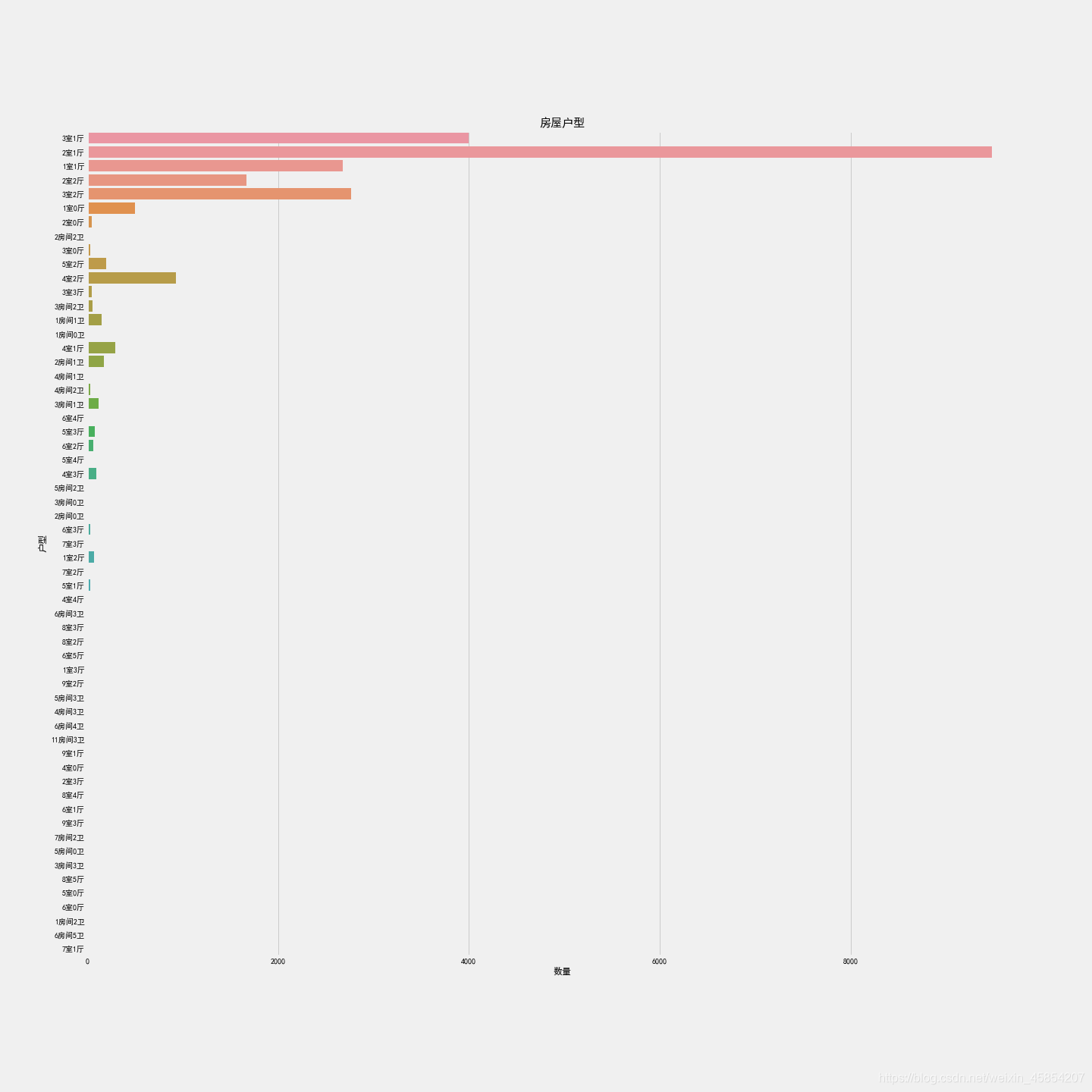
可见2室1厅占绝大部分,其次是3室1厅,2室2厅,3室2厅。
(4)Renovation特征分析
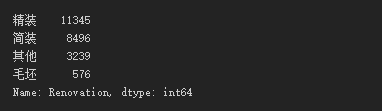
df['Renovation'].value_counts()
#画幅设置
f,[ax1,ax2,ax3] = plt.subplots(1,3,figsize=(20,5))
sns.countplot(df['Renovation'],ax=ax1)
sns.barplot(x='Renovation',y='Price', data=df, ax=ax2)
sns.boxplot(x='Renovation',y='Price', data=df, ax=ax3)
plt.savefig("C:\Jupyter_working_path\Projects\picture3")
``
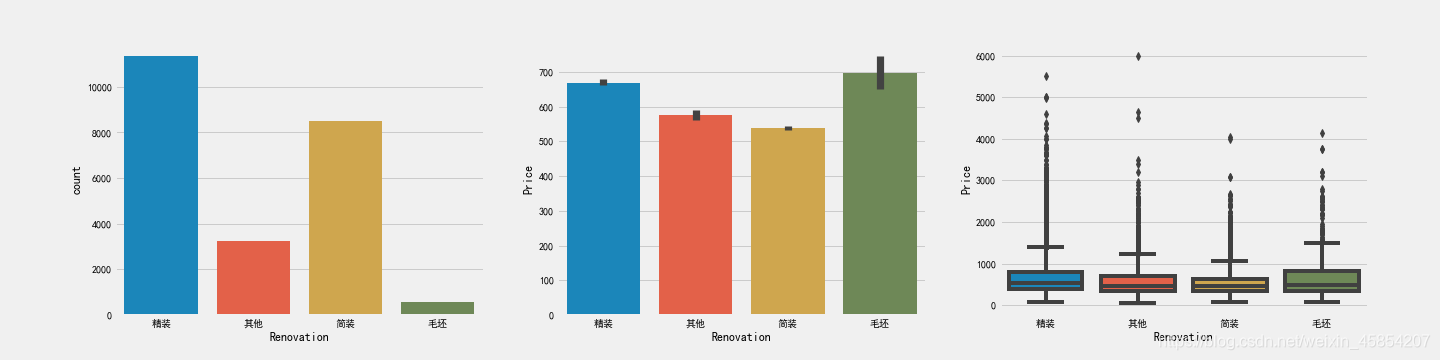
观察到,精装修的二手房数量最多,简装其次。毛坯类的价格最高,其次是精装。
(5)Elevator特征分析
查看缺失值
misn = len(df.loc[(df['Elevator'].isnull()),'Elevator'])
print('Elevator缺失值数量为:'+ str(misn))

这么多缺失值肯定不能直接移除,这里考虑填补法。
根据楼层来判断是否有电梯,一般楼层大于6的都有电梯,小于6就无电梯。
#由于存在个别类型错误,故需要移除
df['Elevator']=df.loc[(df['Elevator'] =='有电梯')|(df['Elevator'] =='无电梯'),'Elevator']
#填补缺失值
df.loc[(df['Floor']>6)&(df['Elevator'].isnull()), 'Elevator'] ='有电梯'
df.loc[(df['Floor']<=6)&(df['Elevator'].isnull()), 'Elevator'] ='无电梯'
f, [ax1,ax2] = plt.subplots(1,2,figsize=(20,10))
sns.countplot(df['Elevator'], ax=ax1)
ax1.set_title('有无电梯数量对比',fontsize=15)
ax1.set_xlabel('是否有电梯')
ax1.set_ylabel('数量')
sns.barplot(x='Elevator',y='Price', data=df, ax=ax2)
ax2.set_title('有无电梯房价对比',fontsize=15)
ax2.set_xlabel('是否有电梯')
ax2.set_ylabel('总价')
plt.show()
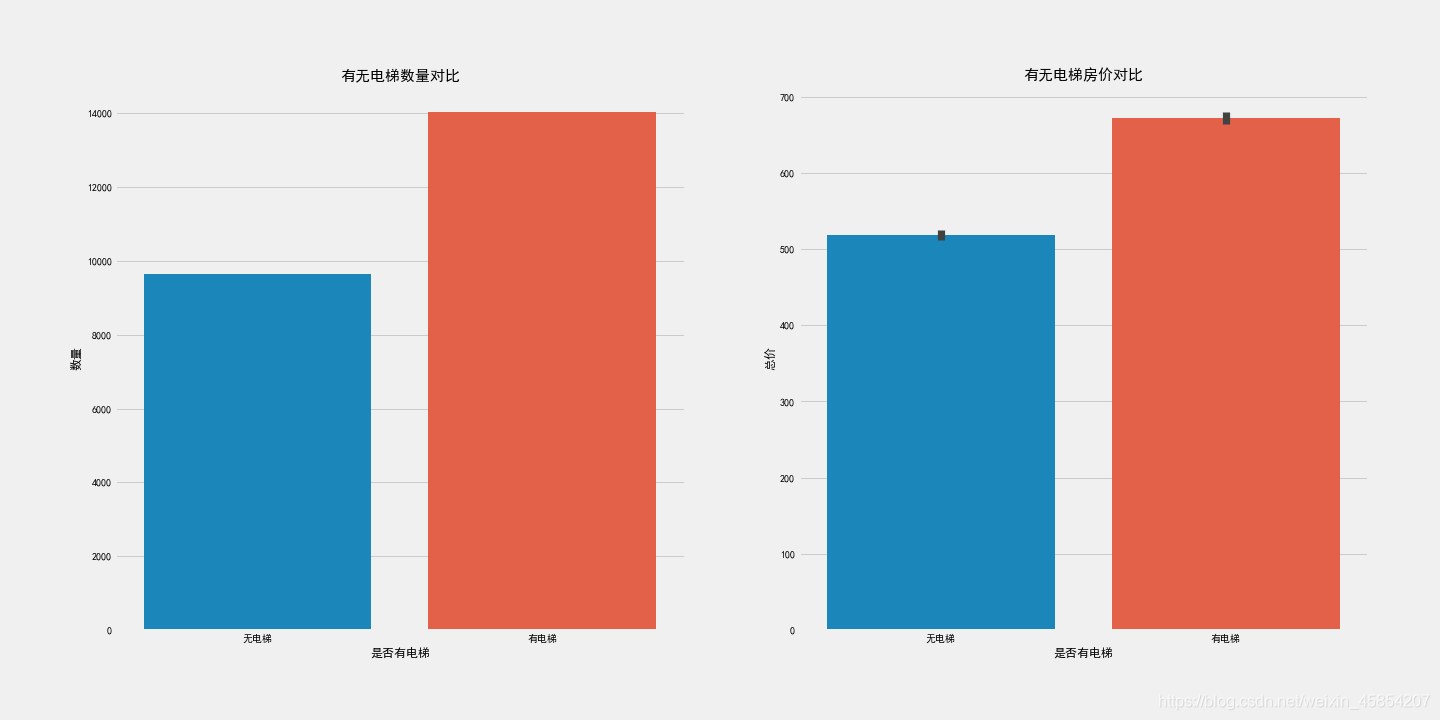
可见,有电梯的二手房更多,但是有电梯的二手房价格也高,这个很容易理解。
(5)Year特征分析
grid = sns.FacetGrid(df, row='Elevator', col='Renovation', palette='seismic', size=4)
grid.map(plt.scatter, 'Year', 'Price')
grid.add_legend()
plt.savefig("C:\Jupyter_working_path\Projects\picture6")
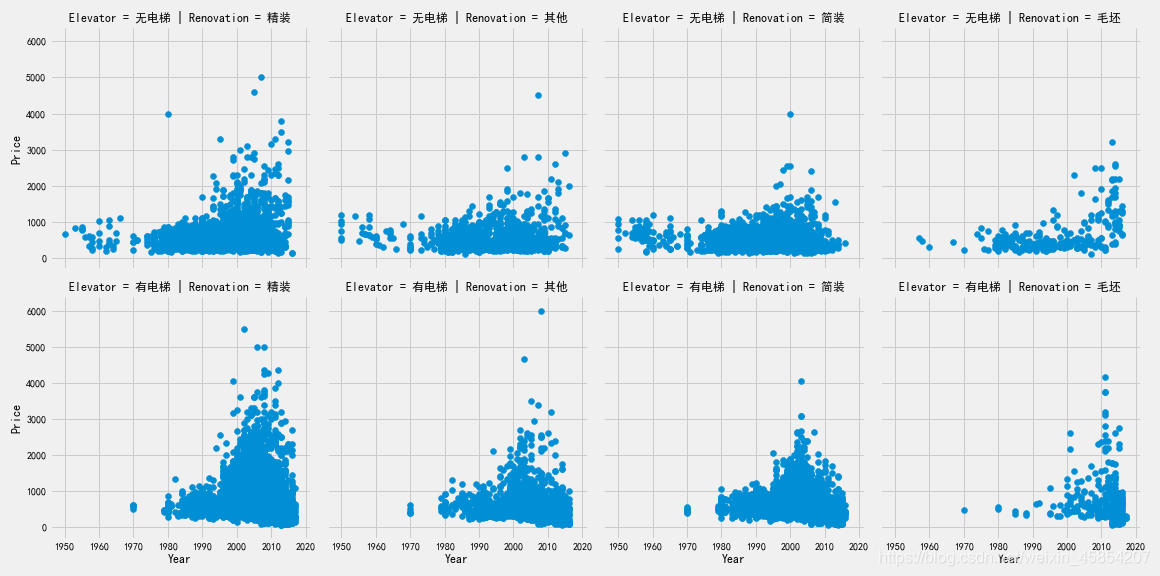
在Renovation和Elevator的分类条件下,使用FaceGrid分析Year特征,结果显示:
整个二手房房价趋势随着时间增长而增长;
2000年后建造的二手房价格比之前的明显上涨;
1980年前几乎没有电梯房数据,说明那个年代还没有普遍安装电梯
(6)Floor特征分析
f, ax1=plt.subplots(figsize=(20,5))
sns.countplot(x='Floor',data=df, ax=ax1)
ax1.set_title('房屋户型',fontsize=15)
ax1.set_xlabel('数量')
ax1.set_ylabel('户型')
plt.savefig("C:\Jupyter_working_path\Projects\picture8")
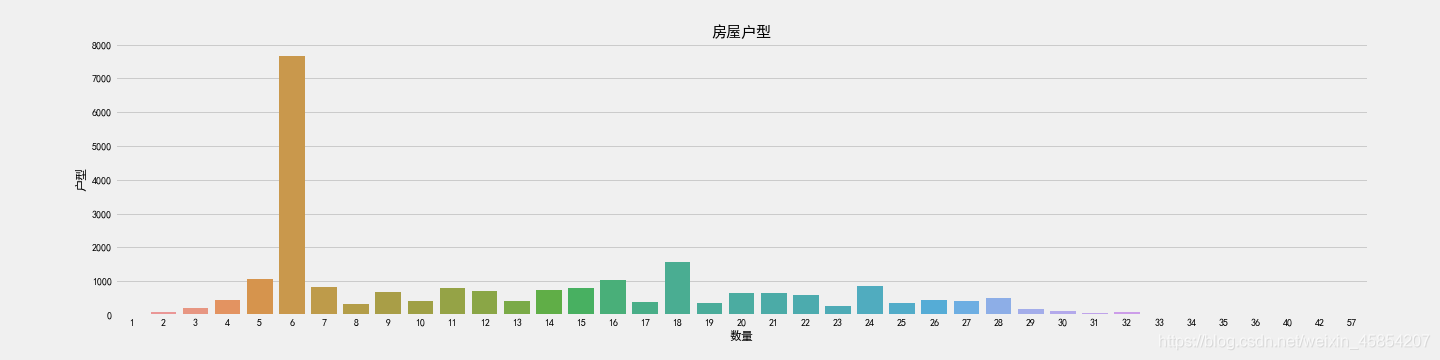
可见:6层二手房数量最多。根据中国的习俗,七上八下,所以显然7层比8层受欢迎;而且4层和18层一般不受欢迎。楼层特征影响因素众多故不一一分析。
本次先分享到这里,其实还可以深入对一些特征进行分析,通过这次学习更加锻炼了我的数据分析思维。特征工程是一件复杂的事情,后续还应努力学习。
