首先需要理解基于最小二乘法求解参数。
矩阵表达,几何意义,从概率角度看最小二乘法等价于noise为高斯分布的MLE(极大似然概率)。
正则化,L1Lasso
L2 Ridage岭回归。
其中涉及到了 损失函数,最大似然估计等内容,
损失函数为
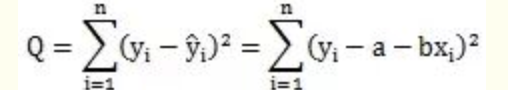
需要做的便是求出该值得最小值,对该损失函数求导,求出倒数为零时即为损失函数最小值,经过一系列计算后得到的结果就是(需要注意的是,由于下面的计算方法需要X为可逆的,这边需要自变量间不能存在多重共线性)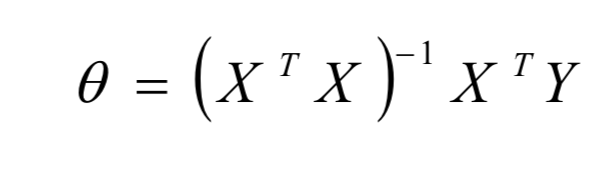
所以用python实现最小二乘法估计的方法如下所示
# 引入所需要的全部包
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from pandas import DataFrame
### 设置字符集,防止中文乱码
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
#导入数据集,看看数据的形式
path1='datas/household_power_consumption_1000.txt'
df = pd.read_csv(path1, sep=';', low_memory=False)#没有混合类型的时候可以通过low_memory=F调用更多内存,加快效率)
print(df.head())
print(df.columns)
#看一下数据的列名结果为Index(['Date', 'Time', 'Global_active_power', 'Global_reactive_power',
'Voltage', 'Global_intensity', 'Sub_metering_1', 'Sub_metering_2',
'Sub_metering_3'],
dtype='object'),在这里我们选取'Global_active_power', 'Global_reactive_power',作为自变量,'Voltage',作为因变量
X_data = df.iloc[:, 2:4]
Y_data = df.iloc[:,5]
#将数据区分为训练集和测试集,在这里采用的train_test_split函数,它的输入参数有测试集占比test_size,以及随机分类种子数random_STATE,方便之后完全重复此划分工作.类似的功能也可以自己通过shuffle函数将变量随机排序,然后选取前80%作为训练,后20%作为测试
X_train,X_test,Y_train,Y_test = train_test_split(X_data, Y_data, test_size=0.2, random_state=0)
#由于后续的转化都是用numpy的矩阵形式,所以需要用np.mat转化为矩阵
X = np.mat(X_train)
Y = np.mat(Y_train).reshape(-1,1)#这里的x是两列会自动转化为n行两列,只有1列的y会变成n列1行,需要人工的reshape一下,变成1列
#求出最小二乘法的最优theta
theta = (X.T*X).I*X.T*Y
#y的预测值为
y_hat = np.mat(X_test) * theta
#通过plt可视化观察预测值与实际值得差距
t=np.arange(len(X_test))
plt.figure(facecolor='w')
plt.plot(t, Y_test, 'r-', linewidth=2, label=u'真实值')
plt.plot(t, y_hat, 'g-', linewidth=2, label=u'预测值')
plt.legend(loc = 'lower right')
plt.title(u"线性回归预测功率与电流之间的关系", fontsize=20)
plt.grid(b=True)
plt.show()
当然也可以利用现有的sklearn框架进行用最小二乘法进行线性回归
# 引入所需要的全部包
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from pandas import DataFrame
import time
## 设置字符集,防止中文乱码
mpl.rcParams['font.sans-serif']=[u'Arial Unicode MS']
mpl.rcParams['axes.unicode_minus']=False
#加载数据
path1='datas/household_power_consumption_1000.txt'
df = pd.read_csv(path1, sep=';', low_memory=False)
# 查看格式信息,对不符合格式的数据进行修改,如下将某列修改为float格式
df.info()
#df['列名'] = df['列名'].astype(np.float64)
# 异常数据处理(异常数据过滤),去除掉异常数据,包括错误格式或者极大值极小值
new_df = df.replace('?', np.nan)#替换非法字符为np.nan
datas = new_df.dropna(axis=0,how = 'any')
# 再次查看格式信息
df.info()
## 创建一个时间函数格式化字符串
def date_format(dt):
import time
t = time.strptime(' '.join(dt), '%d/%m/%Y %H:%M:%S')
return (t.tm_year, t.tm_mon, t.tm_mday, t.tm_hour, t.tm_min, t.tm_sec)
# 获取x和y变量, 并将时间转换为数值型连续变量
X = datas.iloc[:,0:2]#前两行分别是日期和时间
X = X.apply(lambda x: pd.Series(date_format(x)), axis=1)
Y = datas['Global_active_power']
#进行测试集和训练集的划分
X_train,X_test,Y_train,Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
#数据的标准化
ss = StandardScaler()
X_train = ss.fit_transform(X_train) # 训练并转换
X_test = ss.transform(X_test) ## 直接使用在模型构建数据上进行一个数据标准化操作
## 模型训练
lr = LinearRegression()
lr.fit(X_train, Y_train) ## 训练模型
## 模型校验
y_predict = lr.predict(X_test) ## 预测结果
#这里的score就是决定系数
print("训练R2:",lr.score(X_train, Y_train))
print("测试R2:",lr.score(X_test, Y_test))
mse = np.average((y_predict-Y_test)**2)
rmse = np.sqrt(mse)
print("rmse:",rmse)
# 使用加载的模型进行预测
data1 = [[2006, 12, 17, 12, 25, 0]]
data1 = ss.transform(data1)
print(data1)
lr.predict(data1)
## 预测值和实际值画图比较
t=np.arange(len(X_test))
plt.figure(facecolor='w')#建一个画布,facecolor是背景色
plt.plot(t, Y_test, 'r-', linewidth=2, label='真实值')
plt.plot(t, y_predict, 'g-', linewidth=2, label='预测值')
plt.legend(loc = 'upper left')#显示图例,设置图例的位置
plt.title("线性回归预测时间和功率之间的关系", fontsize=20)
plt.grid(b=True)#加网格
plt.show()
Loss FUNCTION
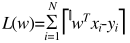
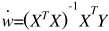
显示XTX可能是不可逆,假如样本数量少等原因,可能不可逆,就是过拟合,解决方式,
1加数据
2降维,特征选择,特征提取
3正则化,对w的一个约束
正则化的框架L(W)+λP(w)加入一个惩罚项
L1 Lasso P(w)=||w||
L2 Ridge p(w)=||w||^2=wTw
岭回归的解析解
W=(XTx+λI)^-1XTY
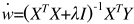
这个一定是可逆的,达到抑制过拟合的效果
