第六步: 绘制决策树的图像
我们通过得到决策树的深度和叶子结点的作用是:
1.完成对于图像整体比例的把握,叶子结点有n个,就把横坐标分成n份进行绘制结点的宽度,
2.同理深度有n层将纵坐标分成n份,完成结点的高度绘制。
3.并以此为基础,通过计算公式得到根结点和叶子结点的位置,还有父子结点之间的特征文本的位置。
4.并调用上几步函数完成结点绘制
# 所以结点的绘制过程是根左右深度遍历到最左边的叶子结点,确认是根直接绘制,。
# 然后把最左边最小的根节点的叶子结点绘制完往上递归绘制根节点,再绘制根节点的兄弟姐妹,再往上回退,再绘制。
def plotTree(myTree, parentPt, nodeTxt): # 输入当前的字典树,父节点,结点填充文本
numLeafs = getNumLeafs(myTree) # 得到当前的根节点树下的叶子结点个数
depth = getTreeDepth(myTree) # 得到当前根节点树下的最大深度
firstside = list(myTree.keys()) # 获取了当前树的所有键
firstStr = firstside[0] # 得到当前节点的键,键值如果是字典,那么键里存的就是根节点文本,
# 计算子节点的坐标,一开始最初始的树的子节点算出来和根节点的坐标是一样的,所以画不出指向根结点箭头
# 详细解释一下中点公式怎么算的,首先最开始是因为xOff定义在脱出画面的半个结点长度
# 因此需要给它加上(当前根的叶子节点数+1)/2个的长度为1/totalW的距离才能到达当前子节点中点的位置,所以下列公式即可算出
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) /2.0 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt) # 填充当前的父子结点之间的文本信息
plotNode(firstStr, cntrPt, parentPt, decisionNode) # 绘制当前根结点和指向根结点箭头
secondDict = myTree[firstStr] # 获取当前根节点下面的子树
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD # 纵坐标到下一层,将减少1/totalD的权重长度
for key in secondDict.keys(): # 遍历字典的值,找值类型是否是字典,即找根结点所有的分支,找叶子节点
if type(secondDict[key]) == dict:
# 这里有个很重要的结论是:如果当前键的键值是字典,说明有子树
# 而且键存着是子树的根节点文本
# 当前键的键值不是字典类型,那么说明键存着父子结点填充文本,键值为叶子结点文本
# 这里三个参数分别是当前字典的值(也就是分支树),下一层的根节点坐标,和下一层根节点要填充的文本
plotTree(secondDict[key], cntrPt, str(key)) # 是字典类型,继续递归绘制下一层的根节点
else:
# 不是字典类型,说明已经到了叶子结点,接下来绘制叶子结点
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW # 一旦发现叶子节点,从左往右不断绘制叶子结点,体现在每次给叶子节点横坐标加1/totalW的长度
# 绘制当前的叶子节点和指向叶节点的箭头,和父子结点之间的填充文本
# 起点是cntrPt,此时的cntrPt其实是父节点的坐标值,(plotTree.xOff, plotTree.yOff)点是子节点的坐标值
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD # 返回上层函数的时候要将y坐标恢复成上层的函数坐标值
createPlot作为主函数的作用:
1.定义了一些重要的变量
2.对图像整体背景,框架等做了处理
3.输入初始值,调用plotTree函数,函数再依次调用其他函数完成决策树的绘制
# 主函数入口
# 更新版的绘制字典树
def createPlot(inTree): # 这个参数是输入初始树
fig = plt.figure(1, facecolor='white') # facecolor背景颜色
fig.clf() # figure图像clf:clearfigure 清除当前图像
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) # frameon是否绘制图像边缘,绘制1*1网格的第一子图 ,**axprops定义为2维坐标轴
plotTree.totalW = float(getNumLeafs(inTree)) # 获取初始树的所有叶子节点个数
plotTree.totalD = float(getTreeDepth(inTree)) # 获取初始树的最大深度
# totalW是叶子结点个数,而整张图的横纵长度为1,所以1/totalW,1/totalD为一个结点的长度
plotTree.xOff = -0.5 / plotTree.totalW # 在图的零点再向左偏移半个结点长度,以此之后获取结点中点的位置
plotTree.yOff = 1.0
# 这里初始值之所以这样输入是因为,其实整棵树画出来,初始树的根节点上面还有一个虚拟的根节点
# 不过这个虚拟根节点的坐标和初始树的根节点坐标一致,结点文本为空,所以和初始树根节点重合,导致看不出来
plotTree(inTree, (0.5, 1.0), '') # 输入初始树,和根节点坐标,和空的字符串
plt.show()
import decisionTree
cars=decisionTree.file2matrix('E:/machinelearingdatas/machinelearninginaction-master/Ch03'
'/car.data')
# 6个属性指标分别为购买价格,维护,门,可容纳人数,汽车后备箱,满意度
'''
buying v-high, high, med, low
maint v-high, high, med, low
doors 2, 3, 4, 5-more
persons 2, 4, more
lug_boot small, med, big
safety low, med, high
'''
carsLabels = ['buying', 'maint', 'doors','persons','lug_boot','safety']
carsTree = decisionTree.createTree(cars,carsLabels)
print(createPlot(carsTree))
自此我们就可以获得图像
这次我们从UCI上下了一个汽车评价的数据集,里面存放了大量的数据,我们将其导入我们主函数中,获取图像
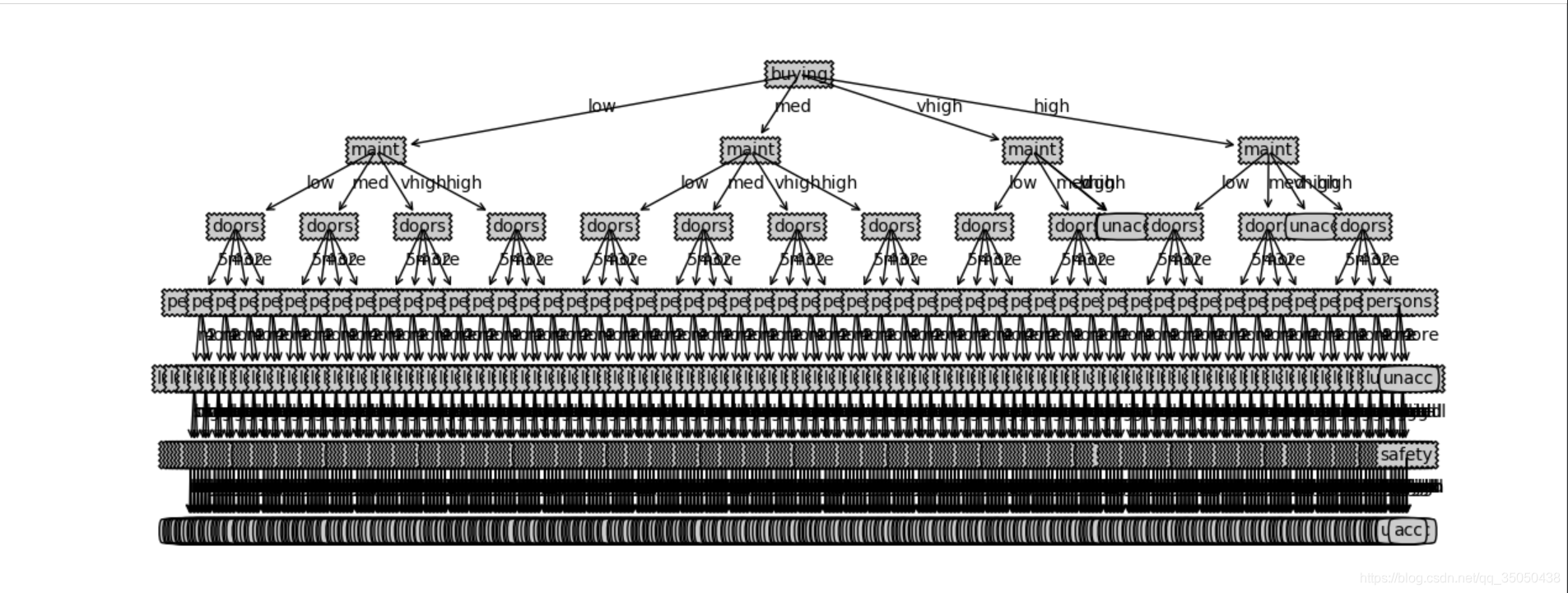
感觉好像哪里出现了点问题,由于我电脑屏幕太小,数据太大,做出来的决策树,不能完全展示出来
我尝试了一下将fontsize调整大小改成5
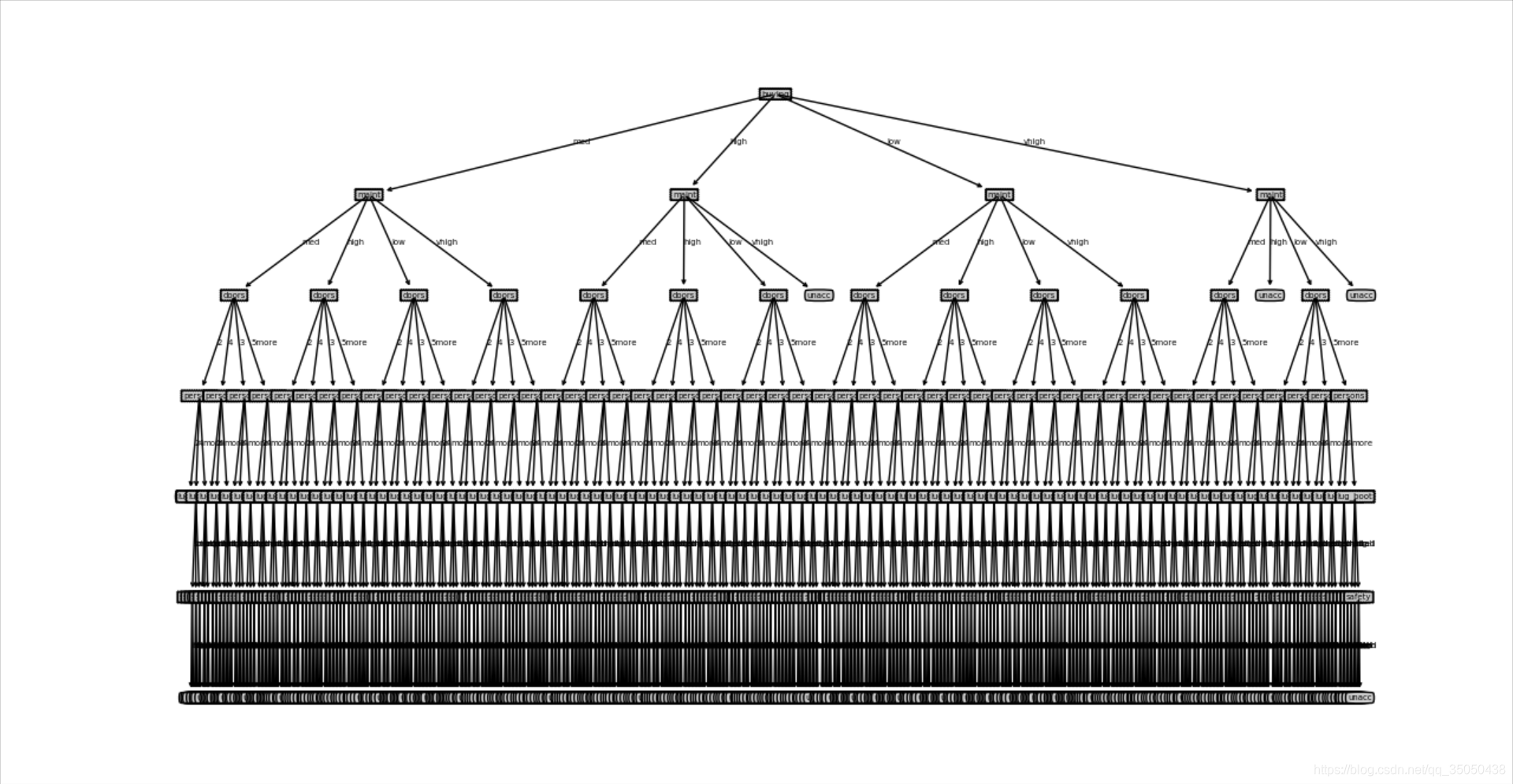
md还是太多了,但是我们决策树是画出来了,所以已经成功了
第七步 创建分类器进行数据测试
当我们学会了如何去创建决策树后,说明我们已经以正确的方法让机器通过大量的数据学习成功
并将机器判断的依据————决策树,给获取了
之后我们要创建分类器,将这个判断路径——决策树和我们需要测试的数据导入分类器里,让分类器推演预算出未来的结果。
#测试分类器
def classify(inputtree,featlabels,testvec):
classlabel=''
firststr=list(inputtree.keys())[0]
seconddict=inputtree[firststr]
featindex=featlabels.index(firststr)
for key in seconddict.keys():
if testvec[featindex]==key:
if type(seconddict[key]).__name__=='dict':
classlabel=classify(seconddict[key],featlabels,testvec)
else:classlabel=seconddict[key]
return classlabel
此时我们自己根据要求创建一组数据,并将其导入分类器
'''
buying v-high, high, med, low
maint v-high, high, med, low
doors 2, 3, 4, 5-more
persons 2, 4, more
lug_boot small, med, big
safety low, med, high
'''
labels = ['buying', 'maint', 'doors','persons','lug_boot','safety']
inputtree = decisionTree.createTree(decisionTree.file2matrix('E:/machinelearingdatas/machinelearninginaction-master/Ch03'
'/car.data'),labels)
labels = ['buying', 'maint', 'doors','persons','lug_boot','safety']
testvec = ['low','high','3','4','big','high']
print(classify(inputtree,labels,testvec))
这是官方给出的数据集,里面不接受的比例占的很高,说明用户对汽车的要求还是挺高的

我们这时依据6个判断属性进行创建几组自己的数据
购买价格 保养价格 门的数量 可容纳人数 后备箱大小 安全性
high high 4 4 med high
high high 4 4 med med
vhigh high 4 4 med high
high high 2 4 med high
high high 4 2 med high
low high 4 4 med high
high high 4 4 small high
这6种情况最后算出来的结果分别为:
accept
accept
unaccept
unaccept
unaccept
verygood
accept
对此我们可以预测结果得出一点结论:买家对门和可容纳人数比较在意,对于价格也是很敏感,但是安全性能和后备箱大小要求不高。
但是决策树我们在创建时当6个判断属性仍然分不出结果的问题,我们的优化是选取多数,说明仍然有人不满足我们的预测情况,我们的预测结果不一定是正确的,因此我们需要对通过这个数据集训练出来的分类器做一个正确性测试:
testdata = [['high','high','4','4','small','high','acc'],
['high','high','2','4','small','high','acc'],
['low','high','4','4','small','high','acc'],
['high','high','4','2','small','high','acc'],
['vhigh','high','4','4','med','high','acc'],
['high','high','4','more','med','med','acc'],
['vhigh','high','4','4','big','low','acc'],
['low','vhigh','more','4','small','low','acc'],
['high','vhigh','4','4','small','high','unacc'],
['vhigh','high','2','4','small','high','unacc']]
自己瞎几把填了10个数据,这些数据仅代表个人观点而且数据集太小了,所以,算出来的分类器的正确率也是不科学的,只是为了测试一下函数。
#测试决策树分类性能'the calculte result is%s,the true result is %s'%(result,testdata[i][-1])
def testefficiency(inputtree,labels,testdata):
flag=0
for i in range(len(testdata)):
result=classify(inputtree,labels,testdata[i][:6])
if(result==testdata[i][-1]): flag +=1
print('the calculte result is%s,the true result is %s'%(result,testdata[i][-1]))
print('the data number is %d,but the right number is %d'%(len(testdata),flag))

得出来的结果部分截图,看出分类器的性能并没有完全的预测正确,但是成功率还是可以的
最后,机器学习想要得到的预测结果尽可能的正确:
1.我们需要选择好的分类算法
2.我们需要大量的有用的数据集
3.我们需要掌握好的数据测试方法,测试方式错误,得出来的正确率也不可信
