前提
了解信息熵
简单提一下,学过物理化学的小伙伴都明白:
熵是无序分子运动紊乱程度的一种度量,熵值越大,内部的混乱程度越大。
因此,信息熵是对某个事件里面所包含的信息的混乱程度
在数学上:
当一件事是不太可能发生的时候,我们获取的信息量较大
当一件事是极有可能发生的时候,我们获取的信息量较小
例如:
1.特朗普其实是中国的卧底
2.特朗普是zz。
结论:
信息的量度应该依赖于概率分布,
所以说熵h(X)应该是概率P(X)的单调函数。
推导过程:
当x事件与y事件不相关时:(x事件与y事件独立)
我们获取x事件和y事件的信息量总和=x事件信息量+y事件信息量
即:h(X,Y) = h(X) + h(Y)————————————(1)
同理:由于x,y事件独立
x,y事件同时发生的概率 = x事件概率*y事件概率
即:P(XY) = P(X) * P(Y)
对其两边取对数
lgP(XY)=lg(P(X)*P(Y)) = lgP(X) + lgP(Y)——————(2)
由(1),(2)式得出结论
h(X)应该是概率P(X)的log函数
P(X)概率在0到1内log后为负数,(常理信息熵h(X)应为正数)
所以我们需要将在公式前添负号。
至于log以谁为底,计算机中一般以2(bit)为底,机器学习中一般以e为底。
所以:事件X单个随机变量xi的信息熵为
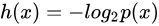
考虑事件X中随机变量xi的所有取值取平均(期望处理)
得到整个事件的信息熵为:
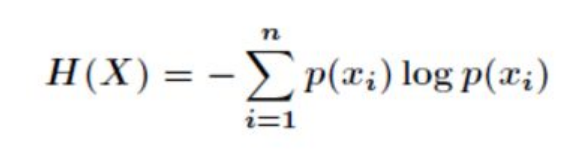
代码附上:
PS:
事件:为整个数据集
随机变量:为数据集中的类别
概率:为数据集中,某一类别数据出现的次数占总共数据集实例的概率
假设我们数据集是西瓜的属性值,最后一列是判断结果
寻找每组数据中最后一列的结果占整个数据集实例的概率
即好瓜的概率有多少,烂瓜的概率有多少
# 度量数据集的无序程度(计算香农熵)
def calcShannonEnt(dataSet): # calculate shannon entropy计算香农熵
numEntries = len(dataSet) # 得到数据集的长度,entries词典的条目的数量,就是词条的数量
labelCounts = {} # 新建空字典
for featVec in dataSet: # 遍历数组
currentLabel = featVec[-1] # currentLabel 存储dataSet最后一列的数值,最后一列是最终判断的结果
if currentLabel not in labelCounts.keys(): # 如果数值不在字典里
labelCounts[currentLabel] = 0 # 如果判断不在字典里,扩展字典,将currentLabel的键值设为0
labelCounts[currentLabel] += 1 # 将currentLabel的键值加1,记录当前,类别的判断在字典里出现的次数
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries # probablity 计算字典中的类别在数据集中出现的概率
shannonEnt += -prob * log(prob, 2) # 香农熵的计算公式,其实就是算所以信息的期望值
return shannonEnt
信息增益
当信息和数据混乱程度越高,也就代表我们对于处理理清这件事的难度也就越大,可是一般我们遇到一件事情,或者说上级领导给安排一个任务,往往里面包含的信息是极其混乱的,剪不断理还乱,所以我们大家都希望能够将信息熵降低,将信息纯度提高,有效信息有序且多,排除无效信息。
我们把改变信息熵或者说改变信息纯度的行为称为 信息增益
信息增益为
一般来说,信息熵我们都是希望将它降低,所以信息增益一般大于0
信息增益=分类前的信息熵 - 分类后的信息熵
第一步:划分数据集(将相同类别的数据归类)
# 按照特征划分数据集,它的方式是去除该value,并返回去除所有value的数据组合起来的数据集
def splitDataSet(dataSet, axis, value): # 输入带划分数据集,axis列的属性,value(划分数据集的特征),我们需要返回的特征的值
retDataSet = [] # 创建新的list对象,为了不修改原始数据集
for featVec in dataSet:
if featVec[axis] == value: # 找出每个数据组的axis轴的属性里的特征值,让它和value特征判断,相等去除掉value
# 下面这个操作其实就是找每个数据组的axis列上是value的,我就删掉
reducedFeatVec = featVec[:axis] # 0-axis-1
reducedFeatVec.extend(featVec[axis + 1:]) # axis+1到最后,两个合并起来
retDataSet.append(reducedFeatVec) # 变成[[reducedFeatVec1],[reducedFeatVec2],[reducedFeatVec3]]
return retDataSet # 这里面存着所有被删过value的数据组,没有value的数据组没有放进去
第二步 导入数据集并格式化
这一步我们导入data,并对其清理空格逗号等不必要字符,将其转换为列表。
def file2matrix(filename):
fr=open(filename)
lists=fr.readlines()
listnum=[]
for k in lists:
listnum.append(k.strip().split(','))
return listnum
第三步 选择最好的数据集划分方式
假设数据集中每组数据的类别有5种,即它的属性值有5种
即西瓜有颜色,大小,成色,软硬程度,条纹
我们将每种类别都作为一种划分数据集的方式,计算它的信息熵有没有减少,把减少的最厉害的划分方式,也就是信息增益最大的,作为第一个划分手段
# 选择最好的数据集划分方式
'''
dataSet = [[1,2,3],[4,2,6,7],[8,3,2,11]]
for fc in dataSet:
if fc[1] == 2:
print(fc[:1],fc[2:],"!")
for i in range(3):
featlist = [example[i] for example in dataSet]
print(featlist)
[1] [3] !
[4] [6, 7] !
[1, 4, 8]
[2, 2, 3]
[3, 6, 2]
'''
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet) # 计算数据集的香农熵
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
# 这个写法是遍历数据集中的每一行,把其中的第i个数据取出来组合成一个列表,每个i列表示一种属性
featList = [example[i] for example in dataSet] # 把属性i中相同类别的元素划在一个列表,再合起来组合成一个大列表
uniqueVals = set(featList) # set可以去掉重复元素
newEntropy = 0.0
# 找列表的第一个列表里遍历,在遍历列表里的第二个列表,以此类推
for value in uniqueVals: # 把所有类别的所有特征全部划分一次数据集
subDataSet = splitDataSet(dataSet, i, value) # 给出在属性i下不同的特征值获取每种不同划分方式的数据集
# 对应到决策树的情况就是每次选判断条件(特征值),通过这个判断条件之后剩下来的数据集的信息熵是否减少
prob = len(subDataSet) / float(len(dataSet)) # 计算i轴属性i下有value的数据组占整个数据组的概率
newEntropy += prob * calcShannonEnt(subDataSet) # 计算不同划分方式的信息熵
infoGain = baseEntropy - newEntropy # 计算所有的信息增益
if infoGain > bestInfoGain: # 选出最大的信息增益
bestInfoGain = infoGain
bestFeature = i # 找到最好的划分方式特征并返回
return bestFeature
