在客户端发起请求,从服务器拿到html文档后,要做的就是对该文档的解析。因为拿到的html文档是字符流,所以首先要对其进行标签解析,对于html的解析,通过状态机,将字符流转换成几种种类的节点,大概有标签开始,属性,标签结束,注释,CDATA节点几种。
标签解析
对文档流的解析,我们先使用简单的只有四个状态的标签来分析,标签开始状态,标签名称状态,标签闭合状态,文本状态。
取下面这段html代码来分析
<p>text</p>
首先,默认开始的状态为文本状态
- 遇到<,进入标签开始状态
- 遇到p,进入标签名称状态
- 遇到>,将当前的标签发给构造器,转而进入文本状态
- 遇到t,维持文本状态
- 遇到e,维持文本状态
- 遇到x,…
- 遇到t,…
- 遇到<,将文本发送到构造器,进入标签开始状态
- 遇到/,进入标签闭合状态
- 遇到p,进入标签名称状态
- 遇到>,将当前的闭合标签发到构造器
这里可以看到,解析字符流时,是一个一个字符解析的,通过这种标记化算法,来将字符流解析成标签发给构造器。当然,实际上的状态不只四个,要考虑的情况还有很多。比如注释,标签中的属性,CDATA节点等…
上面的标签,解析后就会变成<p>,text,</p>三个“词”,在构造DOM树时就使用这些词来构造。
实际上,我们每读入一个字符,就要进行一次决策,而且这个决策的结果与当前的状态有关。
DOM树的构造
DOM树的构造是通过使用栈这种结构来实现的,尝试构造下面这段简单的结构
(以下为我自己的理解,如有什么错误请各位在评论中指出)
<html>
<body>
<h1></h1>
<div>
<p></p>
<p></p>
</div>
</body>
</html>

将每列看成一次栈的操作,红色的即为出栈,对应下面的树图
黑色背景的为当前指针指向的位置,如果有新的开始标签,则在当前指针下插入该节点,如果为闭合标签,则将指针指到父标签,最后构造成一颗完整的树
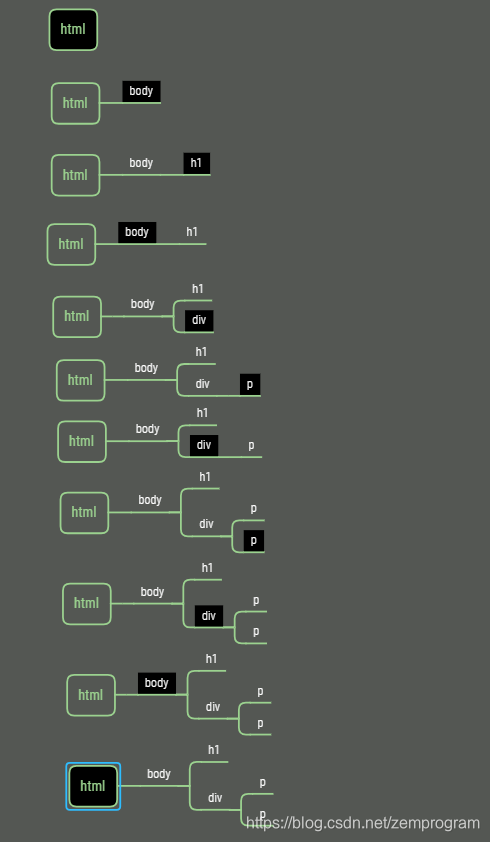
这里因为做图太麻烦。。。,我没有把文本内容添加进去,但实际上处理方式也是一样的。
非单纯的HTML文档树
上面说的是单纯的HTML文档树,如果在解析html时遇到了JavaScript或者html,就会去解析相应的代码
遇到JavaScript代码
在解析DOM树时,如果遇到JavaScript代码,就会停下来解析相应的JavaScript代码,此时HTML文档树会被阻塞,这是因为JavaScript可能会对HTML造成一定的影响。
像下面这段代码
<h1 id="before">我是script标签前的标签</h1>
<script>
console.log(document.getElementById('before').innerHTML)
console.log(document.getElementById('after').innerHTML)
</script>
<h1 id="after">我是script标签后的标签</h1>
因为在执行到JavaScript代码时被阻塞,后面的h1标签还没被解析,所以获取不到这个DOM节点,document.getElementById('after')也就变成null了,所以控制台会报下面的错

这也是我们平时说要将JavaScript代码写在</body>之前的原因之一,当然,如果要做异步处理,使其不造成阻塞的话,可以加上async或defer。
