html文件在没有写入html标签之前和txt文本是一个性质的,不含任何样式。只是单纯的文本预览文件。一旦加入了html标签,表示内容有了语义!浏览器的渲染引擎才会根据标签的语义开始解析。
Webkit核心工作过程
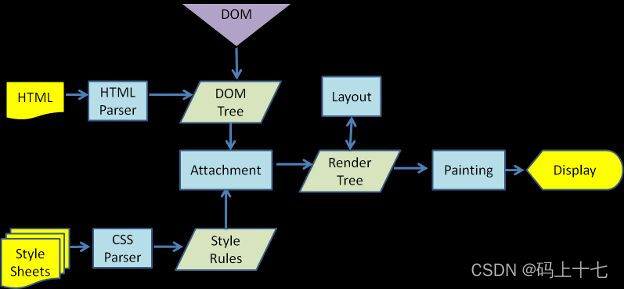
浏览器渲染引擎从上往下执行代码(包括HTML,CSS和JS),解析html生成DOM树,同时解析CSS代码生成css rule tree,同时把DOM tree和css rule tree合并生成render tree,同时还会去请求另一些资源,所以渲染引擎会同时干很多事,迫不及待地把内容渲染出来,如果后面的代码会改变之前的样式,会引起回流和重绘。
render tree生成之后,会进行计算图层布局,所有元素的相对位置和大小信息都在这一步计算,然后将页面图层转化为像素,最后,整合所有图层,得到页面
总结一下渲染引擎的基本工作流程:
- 解析HTML构建DOM树
- 渲染树构建
- 渲染树布局
- 绘制渲染树
渲染引擎会解析HTML文档并把标签转换成内容树中的DOM节点。它会解析style元素和外部文件中的样式数据。样式数据和HTML中的显示控制将共同用来创建另一棵树——渲染树。渲染引擎会尝试尽快的把内容显示出来。它不会等到所有HTML都被解析完才创建并布局渲染树。它会在处理后续内容的同时把处理过的局部内容先展示出来。
解析
解析一个文档意味着把它翻译成有意义的结构以供代码使用。解析的结果通常是一个表征文档的由节点组成的树,称为解析树或句法树。
解析器通常把工作分给两个组件——分词程序和解析程序。分词程序负责把输入切分成合法符号序列,解析程序负责按照句法规则分析文档结构和构建句法树。
- 词法分析器知道如何过滤像空格,换行之类的无关字符。
- 解析器输出的树是由DOM元素和属性节点组成的。DOM的全称为:Document Object Model。它是HTML文档的对象化描述,也是HTML元素与外界(如Javascript)的接口。
DOM与标签几乎有着一一对应的关系,如下面的标签:
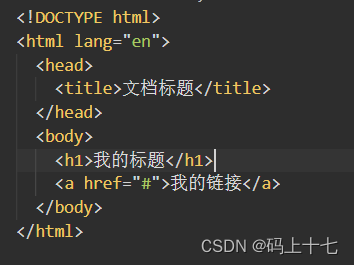
会被转换成如的DOM树:

解析算法
HTML 不能使用常见的自顶向下或自底向上方法来进行分析。主要原因有以下几点:
- 语言本身的“宽容”特性
- HTML 本身可能是残缺的,对于常见的残缺,浏览器需要有传统的容错机制来支持它们
- 解析过程需要反复。对于其他语言来说,源码不会在解析过程中发生变化,但是对于 HTML 来说,动态代码,例如脚本元素中包含的 document.write() 方法会在源码中添加内容,也就是说,解析过程实际上会改变输入的内容
由于不能使用常用的解析技术,浏览器创造了专门用于解析 HTML 的解析器。解析算法在 HTML5 标准规范中有详细介绍,算法主要包含了两个阶段:标记化(tokenization)和树的构建。
标记化把输入解析成符号序列。在HTML中符号就是开始标签,结束标签,属性名称和属生值。分词器识别这些符号并将其送入树构建者,然后继续分析处理下一个符号,直到输入结束。
解析阻断
在HTML文档解析的过程中,会遇到link标签外链的css文件这时候会请求并解析css文件,但并不会阻塞第一步解析HTML文件
但是在HTML解析时,遇到link标签外链的js文件或者script内的js代码时,HTML文件解析会停下来
解析JS文件的过程:
- 浏览器会请求js代码,并返回,这时候HTML文件的解析会停下来,
- 但是CSS文件的解析不会停止,所以会构造出CSSOM树,
- 在构建CSSOM树的时候,返回的js文件并不会执行,在CSSOM树构建完成,才会运行JS文件。
JS文件执行结束后,HTML继续解析并构建出DOM树。
外联JS的种类
外联JS可分为三种:普通型,自带defer属性和自带async属性
1、普通型
外联JS文件一般通过script标签引入,默认是同步加载,即执行完js文件才继续执行下面的HTML代码。当浏览器解析到<script>标签时,会交由js引擎执行,同时不会解析script标签包含的内容,遇到</script>标签结束。
<script src='abc'>console.log('1111')</script>
//不会输出1111他在页面中有两种放置位置,第一种是在head标签内,第二种是在body标签里的最下面,</body>前面。
head标签内:会先下载完所有head标签内的js代码,再去解析body标签内的HTML代码,当js文件过多过大时,浏览就会在短时间内显示空白,用户体验不好
body标签内:这样不会影响html代码的解析,但是对于一些依赖js的网页,就显得慢了。
所以最好的方法是一边解析,一边下载
2、自带defer属性
defer属性:一边解析HTML一边下载js文件,下载好之后放到一个序列里,等到DOM树创建完成之后在执行
如果有多个外联defer js文件,则肯定会按照书写顺序执行,且一定在DOMContentLoad事件前执行,因此引入注意顺序
3、自带async属性
async属性:一边解析HTML一边下载js文件,下载完成后立马执行,执行时仍然会阻塞html代码解析
如果有多个外联async js文件,则哪个先下载完先执行哪个,不一定按照书写顺序执行