浏览器解析HTML文档生成DOM树的过程
以下是一段HTML代码,以此为例来分析解析HTML文档的原理
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <script src="script.js"></script> <link rel="stylesheet" type="text/css" href="style.css"> <title></title> </head> <body> <h1>HelloWorld</h1> <div> <div> <p>picture:</p> <img src="example.png"/> </div> <div> <p>A paragraph of explanatory text...</p> </div> </div> </body> </html>
浏览器解析HTML文档,在<head>中发现了<script>和<link>引入文件,于是向服务器请求文件,在请求和下载文件过程中将继续向下解析HTML,当引入文件下载完成后会通知浏览器回头来解析css和script文件。
如果浏览器在代码中发现一个<img>标签引用了一张图片,向服务器发出请求。此时浏览器同样不会等到图片下载完,而是继续渲染后面的代码;
现在进入正题,讲讲自己对解析HTML文档构建DOM树的理解:
此过程可分为两个主要模块构成,即
- 标签解析
- DOM树构建
1. 标签解析
这部分完成从HTML字符串中解析出标签的功能。主要使用标记化算法。
标记化算法的输入结果是HTML标记,使用状态机表示。状态机一共有4个状态:数据状态(Data)、标记打开状态(Tag open)、标记名称状态(Tag name)、关闭标记打开状态(Close tag open state)。
初始状态是数据状态。
当标记是处于数据状态时,
1)遇到字符<时,状态更改为“标记打开状态”:
a. 接收一个a-z字符会创建“起始标记”,状态更改为“标记名称状态”,并保持到接收>字符。此期间的字符串会形成一个新的标记名称。接收到>标记后,将当前的新标记发送给树构造器,状态改回“数据状态”
b. 接收下一个输入字符/时,会创建关闭标记打开状态,并更改为“标记名称状态”。直到接收>字符,将当前的新标记发送给树构造器,并改回“数据状态”。
2)遇到a-z字符时,会将每个字符创建成字符标记,并发送给树构造器。
2. DOM树构建
当标签解析器解析出标签后会发送到DOM树构建器,我们可以认为DOM树构建器主要有以下两部分组成:
- DOM树
- 一个存放标签名的栈
用如下代码演示生成DOM树的过程:
<html>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>picture:</p>
<img src="example.png"/>
</div>
<div>
<p>A paragraph of explanatory text...</p>
</div>
</div>
</body>
</html>
首先树构建器接收到标签解析器发来的起始标签名后,会加入到栈中,图1是解析到<h1>标签的栈中压入的内容,共有<html><body><h1>三个标签,此时还未向DOM树中添加任何结点(图中黑色实线框代表开始标签,红色虚线框代表结束标签,结束标签不会入栈)。
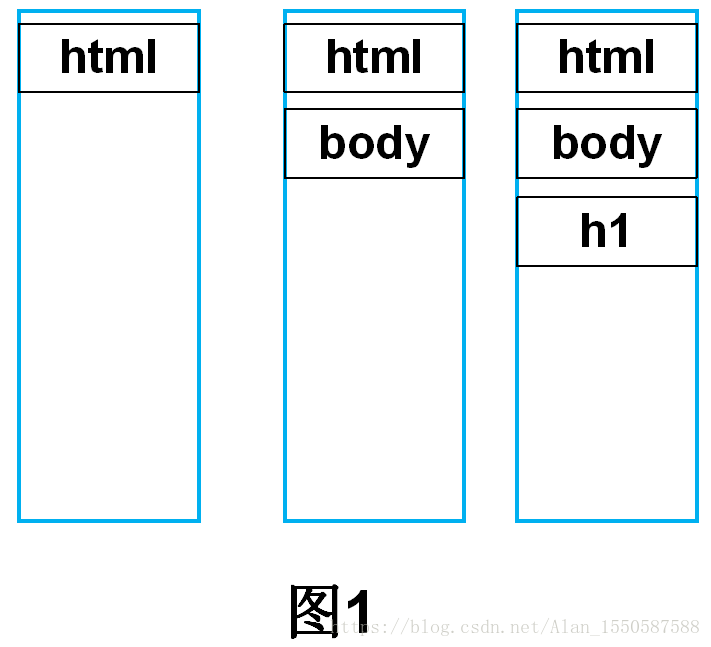
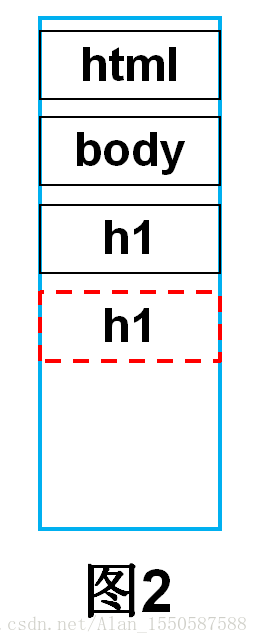
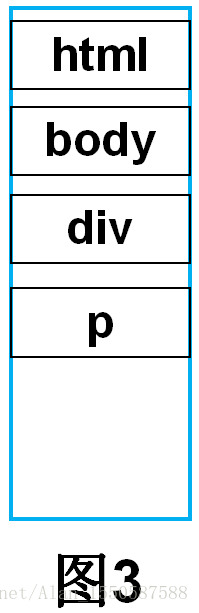
继续向下解析,接收到一个</h1>结束标签,此时查询栈顶元素,如果和传入的结束标签属于同种类型的p标签(如图2),则将栈顶元素弹出,向DOM树中加入此节点,然后继续向下解析(如图3)。
如果遇到的是没有封闭标签的元素如<img/>,则直接加入DOM树中即可,无需入栈。
依次向下解析,当栈为空,即<html>根节点也加入到DOM树中,DOM树构建完毕。
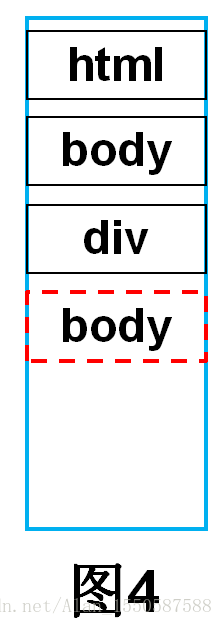
这里需要指出的是,当某个元素缺失结束标签时,假如上述代码中第一个<div>标签缺失了</div>结束标签,即:
<html>
<body>
<h1>HelloWorld</h1>
<div>
<div>
<p>picture:</p>
<img src="example.png"/>
</div>
<div>
<p>A paragraph of explanatory text...</p>
</div>
</body>
</html>
那么,此时的栈如图4所示。即此时传来的结束标签是</body>,而栈顶元素是<div>,两者不是同一种标签,说明div缺少了结束标签,这种情况也将栈顶<div>元素弹出,加入到DOM树中。相当于给<div>补了一个</div>结束标签。