当Dom树构建完成时,浏览器开始构建另一棵树——渲染树。渲染树由元素显示序列中的可见元素组成,它是文档的可视化表示,构建这棵树是为了以正确的顺序绘制文档内容。
Firefox将渲染树中的元素称为frames,WebKit则用renderer或渲染对象来描述这些元素。
一个渲染对象知道怎么布局及绘制自己及它的children。
RenderObject是Webkit的渲染对象基类,它的定义如下:
class RenderObject{ virtual void layout(); virtual void paint(PaintInfo); virtual void rect repaintRect(); Node* node;//the DOM node RenderStyle* style;// the computed style RenderLayer* containgLayer; //the containing z-index layer}RenderObject* RenderObject::createObject(Node* node, RenderStyle* style){Document* doc = node->document();RenderArena* arena = doc->renderArena();...RenderObject* o = 0;switch (style->display()) {case NONE:break;case INLINE:o = new (arena) RenderInline(node);break;case BLOCK:o = new (arena) RenderBlock(node);break;case INLINE_BLOCK:o = new (arena) RenderBlock(node);break;case LIST_ITEM:o = new (arena) RenderListItem(node);break;...}return o;}元素的类型也需要考虑,例如,表单控件和表格带有特殊的框架。
在Webkit中,如果一个元素想创建一个特殊的渲染对象,它需要重写“createRenderer”方法,使渲染对象指向不包含几何信息的样式对象。
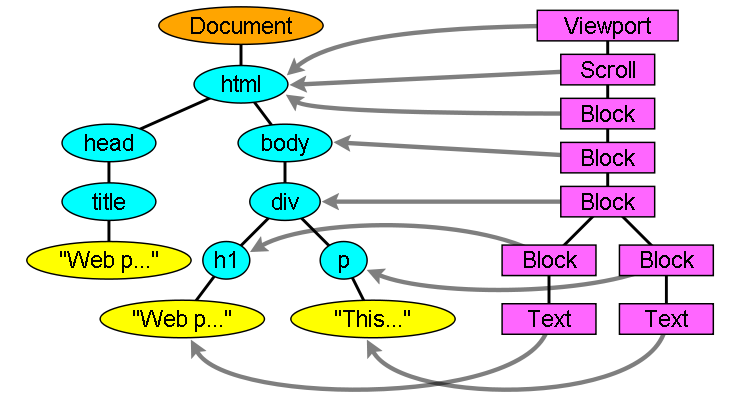
渲染树和Dom树的关系
渲染对象和Dom元素相对应,但这种对应关系不是一对一的,不可见的Dom元素不会被插入渲染树,例如head元素。另外,display属性为none的元素也不会在渲染树中出现(visibility属性为hidden的元素将出现在渲染树中)。
还有一些Dom元素对应几个可见对象,它们一般是一些具有复杂结构的元素,无法用一个矩形来描述。例如,select元素有三个渲染对象——一个显示区域、一个下拉列表及一个按钮。同样,当文本因为宽度不够而折行时,新行将作为额外的渲染元素被添加。另一个多个渲染对象的例子是不规范的html,根据css规范,一个行内元素只能仅包含行内元素或仅包含块状元素,在存在混合内容时,将会创建匿名的块状渲染对象包裹住行内元素。
一些渲染对象和所对应的Dom节点不在树上相同的位置,例如,浮动和绝对定位的元素在文本流之外,在两棵树上的位置不同,渲染树上标识出真实的结构,并用一个占位结构标识出它们原来的位置。
创建树的流程
Firefox中,表述为一个监听Dom更新的监听器,将frame的创建委派给Frame Constructor,这个构建器计算样式(参看样式计算)并创建一个frame。
Webkit中,计算样式并生成渲染对象的过程称为attachment,每个Dom节点有一个attach方法,attachment的过程是同步的,调用新节点的attach方法将节点插入到Dom树中。
处理html和body标签将构建渲染树的根,这个根渲染对象对应被css规范称为containing block的元素——包含了其他所有块元素的顶级块元素。它的大小就是viewport——浏览器窗口的显示区域,Firefox称它为viewPortFrame,webkit称为RenderView,这个就是文档所指向的渲染对象,树中其他的部分都将作为一个插入的Dom节点被创建。
样式计算
创建渲染树需要计算出每个渲染对象的可视属性,这可以通过计算每个元素的样式属性得到。
样式包括各种来源的样式表,行内样式元素及html中的可视化属性(例如bgcolor),可视化属性转化为css样式属性。
样式表来源于浏览器默认样式表,及页面作者和用户提供的样式表——有些样式是浏览器用户提供的(浏览器允许用户定义喜欢的样式,例如,在Firefox中,可以通过在Firefox Profile目录下放置样式表实现)。
计算样式的一些困难:
1. 样式数据是非常大的结构,保存大量的样式属性会带来内存问题。
2. 如果不进行优化,找到每个元素匹配的规则会导致性能问题,为每个元素查找匹配的规则都需要遍历整个规则表,这个过程有很大的工作量。选择符可能有复杂的结构,匹配过程如果沿着一条开始看似正确,后来却被证明是无用的路径,则必须去尝试另一条路径。
例如,下面这个复杂选择符
div div div div{…}
这意味着规则应用到三个div的后代div元素,选择树上一条特定的路径去检查,这可能需要遍历节点树,最后却发现它只是两个div的后代,并不使用该规则,然后则需要沿着另一条路径去尝试
3. 应用规则涉及非常复杂的级联,它们定义了规则的层次
我们来看一下浏览器如何处理这些问题:
共享样式数据
WebkKit节点引用样式对象(渲染样式),某些情况下,这些对象可以被节点间共享,这些节点需要是兄弟或是表兄弟节点,并且:
1. 这些元素必须处于相同的鼠标状态(比如不能一个处于hover,而另一个不是)
2. 不能有元素具有id
3. 标签名必须匹配
4. class属性必须匹配
5. 对应的属性必须相同
6. 链接状态必须匹配
7. 焦点状态必须匹配
8. 不能有元素被属性选择器影响
9. 元素不能有行内样式属性
10. 不能有生效的兄弟选择器,webcore在任何兄弟选择器相遇时只是简单的抛出一个全局转换,并且在它们显示时使整个文档的样式共享失效,这些包括+选择器和类似:first-child和:last-child这样的选择器。
Firefox规则树
Firefox用两个树用来简化样式计算-规则树和样式上下文树,WebKit也有样式对象,但它们并没有存储在类似样式上下文树这样的树中,只是由Dom节点指向其相关的样式。
图14:Firefox样式上下文树
样式上下文包含最终值,这些值是通过以正确顺序应用所有匹配的规则,并将它们由逻辑值转换为具体的值,例如,如果逻辑值为屏幕的百分比,则通过计算将其转化为绝对单位。样式树的使用确实很巧妙,它使得在节点中共享的这些值不需要被多次计算,同时也节省了存储空间。
所有匹配的规则都存储在规则树中,一条路径中的底层节点拥有最高的优先级,这棵树包含了所找到的所有规则匹配的路径(译注:可以取巧理解为每条路径对应一个节点,路径上包含了该节点所匹配的所有规则)。规则树并不是一开始就为所有节点进行计算,而是在某个节点需要计算样式时,才进行相应的计算并将计算后的路径添加到树中。
我们将树上的路径看成辞典中的单词,假如已经计算出了如下的规则树:
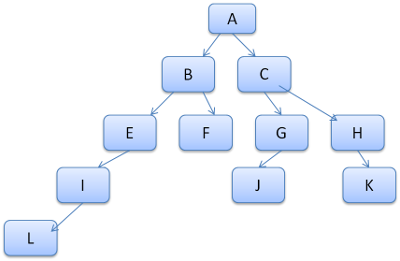
假如需要为内容树中的另一个节点匹配规则,现在知道匹配的规则(以正确的顺序)为B-E-I,因为我们已经计算出了路径A-B-E-I-L,所以树上已经存在了这条路径,剩下的工作就很少了。
现在来看一下树如何保存。
结构化样式上下文按结构划分,这些结构包括类似border或color这样的特定分类的样式信息。一个结构中的所有特性不是继承的就是非继承的,对继承的特性,除非元素自身有定义,否则就从它的parent继承。非继承的特性(称为reset特性)如果没有定义,则使用默认的值。
样式上下文树缓存完整的结构(包括计算后的值),这样,如果底层节点没有为一个结构提供定义,则使用上层节点缓存的结构。
使用规则树计算样式上下文当为一个特定的元素计算样式时,首先计算出规则树中的一条路径,或是使用已经存在的一条,然后使用路径中的规则去填充新的样式上下文,从样式的底层节点开始,它具有最高优先级(通常是最特定的选择器),遍历规则树,直到填满结构。如果在那个规则节点没有定义所需的结构规则,则沿着路径向上,直到找到该结构规则。
如果最终没有找到该结构的任何规则定义,那么如果这个结构是继承型的,则找到其在内容树中的parent的结构,这种情况下,我们也成功的共享了结构;如果这个结构是reset型的,则使用默认的值。
如果特定的节点添加了值,那么需要做一些额外的计算以将其转换为实际值,然后在树上的节点缓存该值,使它的children可以使用。
当一个元素和它的一个兄弟元素指向同一个树节点时,完整的样式上下文可以被它们共享。
来看一个例子:假设有下面这段html
<html><body><div class="err" id="div1"><p>this is a<span class="big"> big error </span>this is also a<span class="big"> verybigerror</span>error</p></div><div class="err" id="div2">another error</div></body></html>1.div {margin:5px;color:black}2..err {color:red}3..big {margin-top:3px}4.div span {margin-bottom:4px}5.#div1 {color:blue}6.#div2 {color:green}简化下问题,我们只填充两个结构——color和margin,color结构只包含一个成员-颜色,margin结构包含四边。
生成的规则树如下(节点名:指向的规则)

上下文树如下(节点名:指向的规则节点)
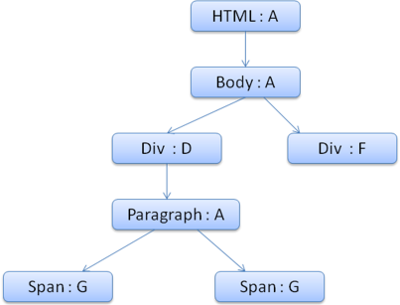
假设我们解析html,遇到第二个div标签,我们需要为这个节点创建样式上下文,并填充它的样式结构。
我们进行规则匹配,找到这个div匹配的规则为1、2、6,我们发现规则树上已经存在了一条我们可以使用的路径1、2,我们只需为规则6新增一个节点添加到下面(就是规则树中的F)。
然后创建一个样式上下文并将其放到上下文树中,新的样式上下文将指向规则树中的节点F。
现在我们需要填充这个样式上下文,先从填充margin结构开始,既然最后一个规则节点没有添加margin结构,沿着路径向上,直到找到缓存的前面插入节点计算出的结构,我们发现B是最近的指定margin值的节点。因为已经有了color结构的定义,所以不能使用缓存的结构,既然color只有一个属性,也就不需要沿着路径向上填充其他属性。计算出最终值(将字符串转换为RGB等),并缓存计算后的结构。
第二个span元素更简单,进行规则匹配后发现它指向规则G,和前一个span一样,既然有兄弟节点指向同一个节点,就可以共享完整的样式上下文,只需指向前一个span的上下文。
因为结构中包含继承自parent的规则,上下文树做了缓存(color特性是继承来的,但Firefox将其视为reset并在规则树中缓存)。
例如,如果我们为一个paragraph的文字添加规则:
p {font-family:Verdana;font size:10px;font-weight:bold}
那么这个p在内容树中的子节点div,会共享和它parent一样的font结构,这种情况发生在没有为这个div指定font规则时。
Webkit中,并没有规则树,匹配的声明会被遍历四次,先是应用非important的高优先级属性(之所以先应用这些属性,是因为其他的依赖于它们-比如display),其次是高优先级important的,接着是一般优先级非important的,最后是一般优先级important的规则。这样,出现多次的属性将被按照正确的级联顺序进行处理,最后一个生效。
总结一下,共享样式对象(结构中完整或部分内容)解决了问题1和3,Firefox的规则树帮助以正确的顺序应用规则。
对规则进行处理以简化匹配过程
样式规则有几个来源:
- 外部样式表或style标签内的css规则
- 行内样式属性
- html可视化属性(映射为相应的样式规则)
后面两个很容易匹配到元素,因为它们所拥有的样式属性和html属性可以将元素作为key进行映射。
就像前面问题2所提到的,css的规则匹配可能很狡猾,为了解决这个问题,可以先对规则进行处理,以使其更容易被访问。
解析完样式表之后,规则会根据选择符添加一些hash映射,映射可以是根据id、class、标签名或是任何不属于这些分类的综合映射。如果选择符为id,规则将被添加到id映射,如果是class,则被添加到class映射,等等。
这个处理是匹配规则更容易,不需要查看每个声明,我们能从映射中找到一个元素的相关规则,这个优化使在进行规则匹配时减少了95+%的工作量。
来看下面的样式规则:
p.error {color:red}#messageDiv {height:50px}div {margin:5px}第一条规则将被插入class映射,第二条插入id映射,第三条是标签映射。
下面这个html片段:
<p class="error">an error occurred </p><div id=" messageDiv">this is a message</div>我们首先找到p元素对应的规则,class映射将包含一个“error”的key,找到p.error的规则,div在id映射和标签映射中都有相关的规则,剩下的工作就是找出这些由key对应的规则中哪些确实是正确匹配的。
例如,如果div的规则是
table div {margin:5px}这也是标签映射产生的,因为key是最右边的选择符,但它并不匹配这里的div元素,因为这里的div没有table祖先。
Webkit和Firefox都会做这个处理。
以正确的级联顺序应用规则
样式对象拥有对应所有可见属性的属性,如果特性没有被任何匹配的规则所定义,那么一些特性可以从parent的样式对象中继承,另外一些使用默认值。
这个问题的产生是因为存在不止一处的定义,这里用级联顺序解决这个问题。
样式表的级联顺序
一个样式属性的声明可能在几个样式表中出现,或是在一个样式表中出现多次,因此,应用规则的顺序至关重要,这个顺序就是级联顺序。根据css2的规范,级联顺序为(从低到高):
1. 浏览器声明
2. 用户声明
3. 作者的一般声明
4. 作者的important声明
5. 用户important声明
浏览器声明是最不重要的,用户只有在声明被标记为important时才会覆盖作者的声明。具有同等级别的声明将根据specifity以及它们被定义时的顺序进行排序。Html可视化属性将被转换为匹配的css声明,它们被视为最低优先级的作者规则。
Specifity
Css2规范中定义的选择符specifity如下:
- 如果声明来自style属性,而不是一个选择器的规则,则计1,否则计0(=a)
- 计算选择器中id属性的数量(=b)
- 计算选择器中class及伪类的数量(=c)
- 计算选择器中元素名及伪元素的数量(=d)
连接a-b-c-d四个数量(用一个大基数的计算系统)将得到specifity。这里使用的基数由分类中最高的基数定义。例如,如果a为14,可以使用16进制。不同情况下,a为17时,则需要使用阿拉伯数字17作为基数,这种情况可能在这个选择符时发生html body div div …(选择符中有17个标签,一般不太可能)。
一些例子:
*{}/* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */li{}/* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */li:first-line {}/* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */ul li{}/* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */ul ol+li{}/* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */h1 + *[rel=up]{}/* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */ul ol li.red{}/* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */li.red.level{}/* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */#x34y{}/* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 *//* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */规则排序
规则匹配后,需要根据级联顺序对规则进行排序,WebKit先将小列表用冒泡排序,再将它们合并为一个大列表,WebKit通过为规则复写“>”操作来执行排序:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2){ int spec1 = r1.selector()->specificity(); int spec2 = r2.selector()->specificity(); return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;}逐步处理Gradual process
webkit使用一个标志位标识所有顶层样式表都已加载,如果在attch时样式没有完全加载,则放置占位符,并在文档中标记,一旦样式表完成加载就重新进行计算。