机器学习基本概念
有监督学习/无监督学习
从兜哥书上的概念来理解,有监督学习与无监督学习最大的判断依据就是训练样本是否有标记。其实看到这里的时候,我产生了几个疑问,下面逐个和大家分享一下。
- 有监督和无监督学习究竟用来干什么,谁会更有优势?
举两个例子,第一个,天上飞过一个动物,我定睛一看,有翅膀,有两个爪子,嘴巴尖尖的,体型也符合,所以我判断飞过的是一只鸟。如果把我换成一个机器,我们给他输入这样一组我眼睛看到的数据,电脑如何作出判断呢?如果电脑已经经过大量的数据进行了有监督学习,他知道翅膀,爪子,嘴巴尖尖,可以飞行,判断为鸟这种动物,那么他就能当我输入数据的时候,告诉我这是鸟。整个过程完全类似小时候老师教导我们的过程。
无监督学习,比如说一个养殖场,有鸡和猪两种动物,我给机器输入一组关于这个养殖场动物脚的个数的数据,通过无监督学习,自然而然的进行分类为2只脚的动物与4只脚的动物,但不会分类为鸡和猪,因为我没有给输入的数据打上标签。
最典型的有监督与无监督学习的例子就是分类问题和聚类问题,如果是分类,有一个分类标准,然后按这个标准去建立学习模型,对后来输入的数据做分类操作,判断属于什么类别。但是如果是聚类,没有这个标准,没有这个类别,算法自己去挖掘数据集合里的内在规律。
补充一个知乎错误高赞回答,这个答案差点让我怀疑人生了就
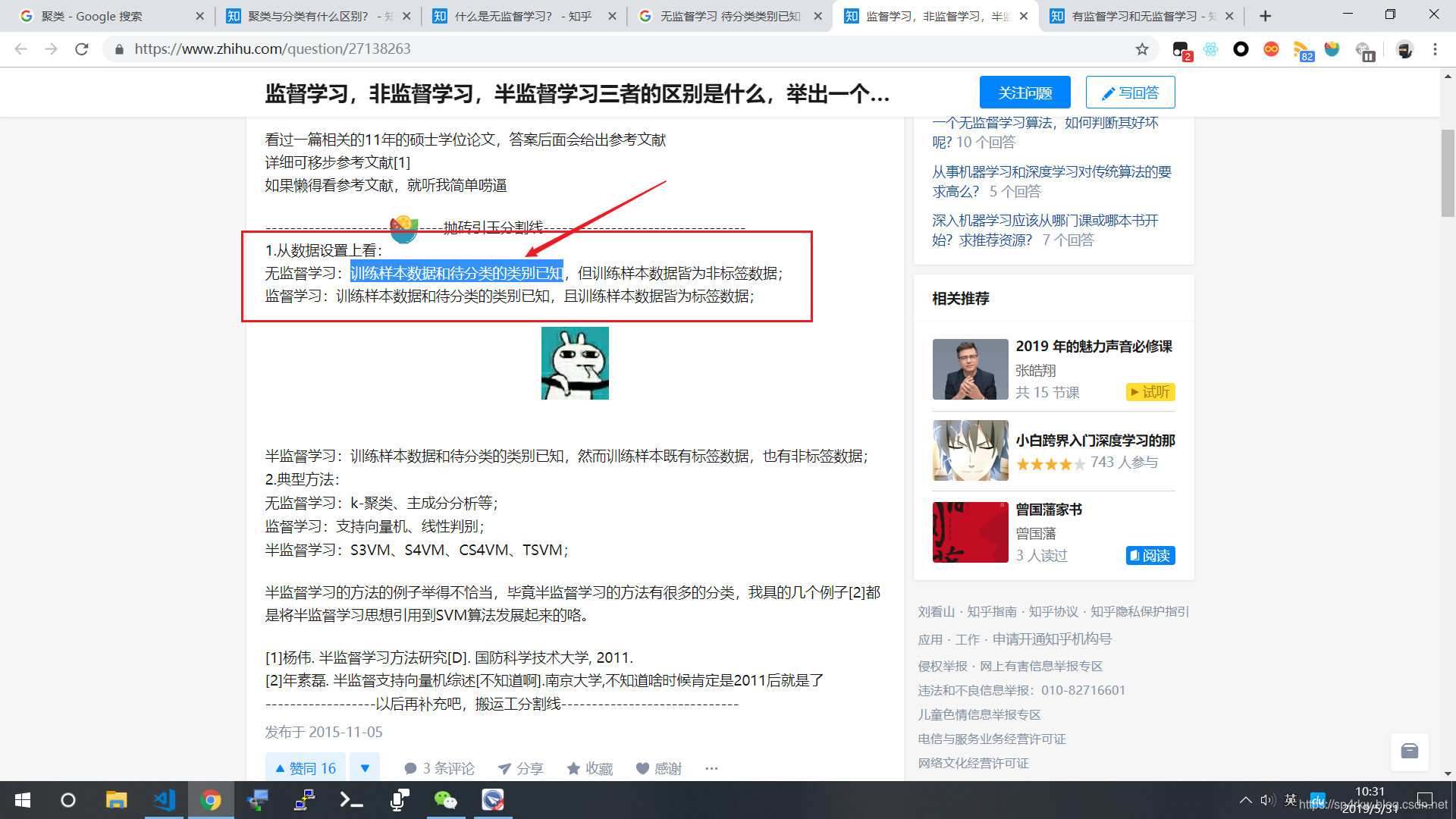
因为无监督学习没有一个标准,所以最终结果可能并不是我们所期望的,一般来说,有监督学习会更具备优势。
- 既然有监督学习比无监督学习具有更多的优势,那为啥不把数据都标记上,全都做有监督学习训练呢?
事实上是,机器学习的第一步,给数据做标记需要花费超长的时间,在这种情况下,有时候被迫就只能选择无监督学习;当然,不排除用于机器学习的数据一部分被标记,一部分没有被标记,这也就是半监督学习的概念。
补,知乎答主已改回答
准确率/召回率
书上提到的TP/FP/FN/TN,在概率论中就是第几类错误的问题。举个例子,警方抓获了一个嫌疑人:
TP: 他是真正的罪犯,法院判他有罪
FP:他是真正的罪犯,法院判他无罪(法院犯了第一类错误)
FN:他不是真正的罪犯,法院判他无罪
TN:他不是真正的罪犯,法院判处他有罪(法院犯了第二类错误)
实际情况中,如果FP,TN两者必须要发生一种,需要根据实际情况选择。比如说法律上的疑罪从无,就是宁愿犯第一类错误也不愿意犯第二类错误的情况。
书上的准确率和召回率,计算感觉不是很好理解,从知乎上找到了一种更好理解的说法:
正确率 = 提取出的正确信息条数 / 提取出的信息条数
召回率 = 提取出的正确信息条数 / 样本中的正确信息条数
当然希望检索结果正确率越高越好,同时召回率也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么正确率就是100%,但是召回率就很低;而如果我们把所有结果都返回,那么比如召回率是100%,但是正确率就会很低。因此在不同的场合中需要自己判断希望正确率比较高或是召回率比较高。
书上关于数据集的部分,我直接粗略翻阅就跳过了
特征提取
这部分内容,我还是觉得因为没有进入具体场景,还是不知道为什么可以这样来进行特征提取,等之后遇到了这类特征提取的时候,再回过头来仔细阅读
