注:小蚊子团队KEN主讲,共分6章。第一章,python与数据分析概况;第二章,python安装和使用;第三章,数据准备; 第四章 数据处理;第五章 数据分析;第六章,数据可视化
一、几个概念
1、定义:按照python规定的格式,将数据的数据类型告知python
2、赋值:将定义好的数据,传递给变量的过程
3、变量:数据赋值的对象,通过变量去操作数据
变量命名规则
由a-z、A-Z、数字、下划线组成,首字母不能为数字和下划线
大小写敏感
变量名不能为python中的保留字
4、三种常用的数据类型
1)、逻辑型logical
布尔型:True、False
运算规则
与:&
都为真,结果真
True & True
都为假,结果假
False & False
一个为假,结果为假
True & False
False & True
或:|
都为真,结果真
True | True
都为假,结果假
False | False
一个为真,结果为真
Ture | False
False | Ture
非:not
非真为假
not Ture
非假为真
not False
2)、数值型numeric
即实数,包含负数、0和正数
运算规则
加
减
乘
除
取整:7 // 4,1
求余:10 % 4,2
乘方:2 ** 3,8
越界
浮点数运算需要注意的地方:from decimal import Decimal,用Decimal封装浮点数
3)、字符型character
代表所有可定义的字符
使用单引号'或者双引号''或者三引号'''将其包含起来
'我是一个字符串'
''我也是一个字符串''
'''我还是一个字符串'''
运算规则
+ 连接字符串
* 重复几次字符串
转义字符
转义
'yes,he doesn\'t' ---> yes,he doesn't
'c:\\some\\name' ----> c:\some\name
/续行
s='abc/
def' ---> s='abcdef'
不转义
r'c:\some\name' ---> c:\some\name
换行
'''
"""
s = """
I am fine.
""" ----> s="i am fine."
二、数据结构
1、定义:相互之间存在一种或者多种特定关系的数据类型的集合,如单行、单列、多行多列
2、学习数据结构的方法
概念,这种数据结构是什么?
定义,如何定义这种数据结构?
限制,使用这种数据结构有什么限制?
访问方式,如何对这种数据结果进行访问?
修改,如何对这种数据结构增、删、查、改?
3、Pandas中的数据结构
1)、Series(系列)
用于存储一行或者一列的数据,以及与之相关的索引的集合
索引号从0开始,可自定义index=[' ',' ',...]
定义一个系列:
from pandas import Series
x = Series()
如:x = Series(
['a',True,1],
index = ['first','second','third']
)
限制:
不能越界访问,否则报错IndexError: index out of bounds
不能追加单个元素,如x.append('2'),只能追加序列:
如:n=Series(['2'])
x.append(n)
TypeError: cannot concatenate a non-NDFrame object
访问:
访问系列
x
访问系列中的元素
按序号访问:x[1]
按索引访问:x['second']
修改:
增加一个序列:
增加后只产生新序列,要改变原序列,需要使用一个变量来承载变化
如:x = x.append(n)
判断值是否在系列中:如‘2 ’ in x.values
序列切片x[1:3]
随机抽取数值,如索引为0,2,1的数值,为 x[[0,2,1]]
值的删除
根据index删除,如:x.drop(0)、x.drop('first')
根据位置删除,如:x.drop(x.index[3])
根据值删除,如:x['2'!=x.values]
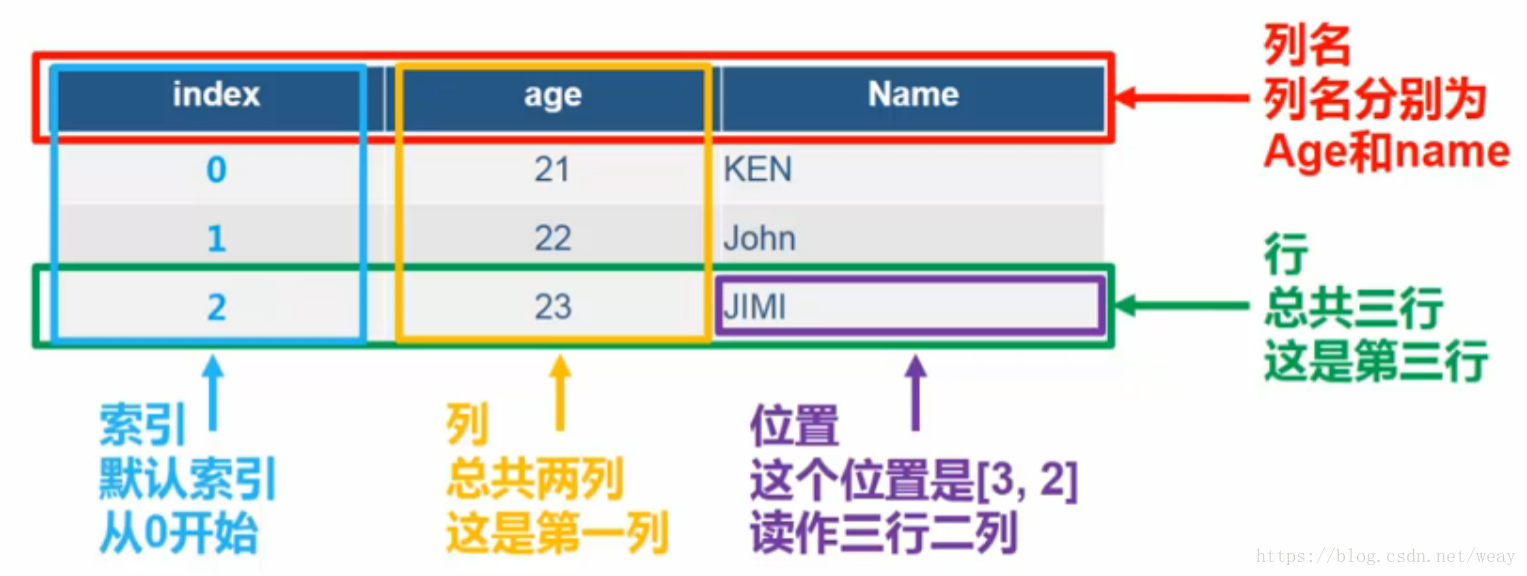
2)、DataFrame(数据框)
定义:用于存储多行和多列的数据集合。
行、列、列名、第几列(不含索引列)、第几行(不含列名行)、索引(从0开始)、位置(几行几列)
定义一个数据框:
from pandas import DataFrame
df = DataFrame(
data = {
'age':[21,22,23],
'name':['KEN','JOHN','JIMI']
}, index = ['first','second','third']
)
访问:
按列访问:df['列名‘],如:df['age'],df[['age','name']]
按行访问:如:df[1:2]访问第2行,df[0:1]访问第一行
按行索引访问:df.loc[['索引名称1','索引名称2']],如:df.loc[['first','second']]
按行、列号访问元素:df.ioc[第几行,第几列],如df.iloc[0:1,0:1],表示第一行第一列
按行索引,列名访问元素:df.at['索引号’,'列名'],如:df.at['first','name']
修改:
修改列名:df.columns=['age2','name2'],没有等号后面的代码表示查看当前列名
修改行索引:df.index=range(1,4),没有等号后面代码表示查看当前索引情况
删除:
根据行索引删除:df.drop('first',axis=0),axis=0表示行
根据列名进行删除:df.drop('age2',axis=1),axis=1表示列
增加:
增加行,注意这种方法效率非常低,不应该用于遍历中
df.loc[len(df)+1] = [24,"KENKEN"]
增加列
df['newCloumn'] = [2,4,6,8]
三、向量化运算
1、定义:是一种特殊的并行运算方式,可以在同一时间执行多次操作,通常是对不同的数据执行同样的一个或者一批指令,或者说把指令应用于一个数组/向量。
2、生成等差数列:numpy.arange(start,end,step)
3、四则运算:
相同位置的数据进行运算,结果保留在相同的位置
语法:S1 op S2
4、函数计算
相同位置的数据进行函数计算,函数返回结果保留在相同的位置
语法:fun(x)
5、向量化计算的原则
代码中尽可能避免显式的for循环
过早的优化是魔鬼
6、生成数列:import numpy
r=numpy.arange(0.1,0.5,0.01)
7、四则运算
r+r
r-r
r*r
r/r
函数式的向量化运算,如:r的5次方,numpy.power(r,5)
比较运算,如:r>0.3,返回的是判断结果True or False
结合过滤进行使用,如过滤r大于0.3的值,即r[r>0.3]
8、矩阵运算
numpy.dot(r,r.T)、sum(r*r)
1)、创建随机数数据框:
from pandas import DataFrame
df = DataFrame({
'column1':numpy.random.randn(5),
'column2':numpy.random.randn(5)
})
2)、每列最小数(apply方法):df.apply(min)
3)、 每行最小数(apply方法)df.apply(min,axis=1)
apply(func [, args [, kwargs ]]) 函数用于当函数参数已经存在于一个元组或字典中时,间接地调用函数。args是一个包含将要提供给函数的按位置传递的参数的元组。如果省略了args,任何参数都不会被传递,kwargs是一个包含关键字参数的字典。
4)、判断每个列的值是否大于0:
df.apply(
lambda x: numpy.all(x>0),
axis=1
)
lambda函数也叫匿名函数,即,函数没有具体的名称。
lambda [arg1[,arg2,arg3....argN]]:expression
例子:
def f(x):
return x**2
print f(4)
Python中使用lambda的话,写成这样:
>>> g = lambda x : x**2
>>> print g(4)
16
>>> (lambda x: x * 2)(3)
6
5)、结合过滤:
df[df.apply(
lambda x: numpy.all(x>0),
axis=1
)]