Kaggle竞赛平台

文章目录
简介
- Kaggle是一个大型的国际数据科学平台,不仅有有趣的数据挖掘深度学习等比赛,还有社交、云服务等有趣的功能。(Kaggle的kernel相当于给了一个免费GPU服务器给用户,在国内不科学上网不能进入Colab等性价比高的云服务器的情况下,无疑是很好的替代选择,Kaggle国内可以访问。)
- Kaggle成立于2010年,是一个进行数据发掘和预测竞赛的在线平台。从公司的角度来讲,可以提供一些数据,进而提出一个实际需要解决的问题;从参赛者的角度来讲,他们将组队参与项目,通过真实的企业数据,针对其中一个问题提出解决方案,最终由公司选出的最佳方案可以获得5000-10000美金的奖金。而且,Kaggle官方每年还会举办一次大规模的竞赛,奖金高达一百万美金,吸引了广大的数据科学爱好者参与其中。(Kaggle目前已经被Google收购)
- Kaggle是世界上认可度最高的数据科学竞赛平台,其Grand Master头衔极大的代表了自身的能力。(类似的数据科学竞赛平台有阿里天池、Data Castle等,但其功能并没有Kaggle这么完善和丰富。)
网站模块
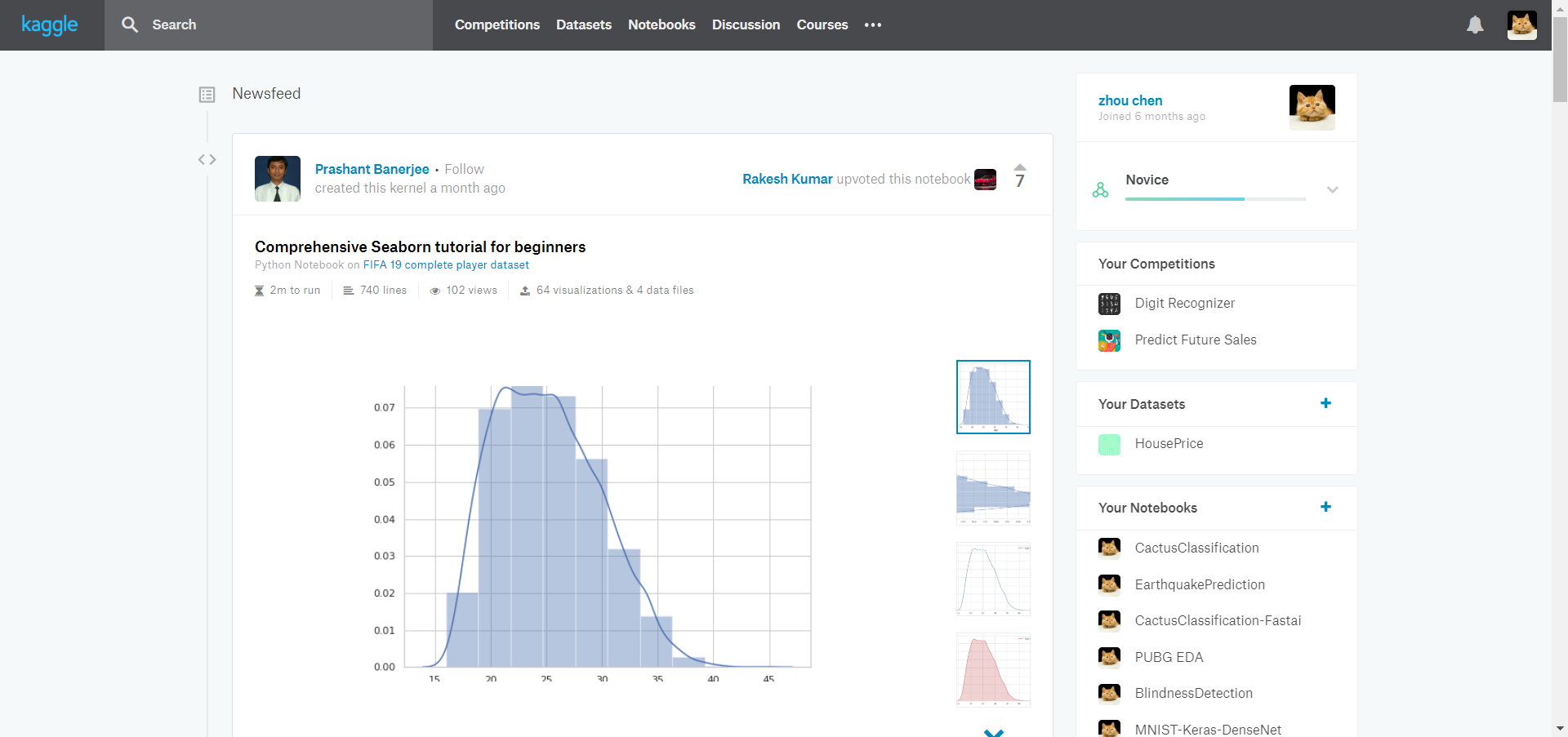
- 各模块
- Competitions(竞赛)
- 包含在办的各类比赛,后面细说其分类。
- Datasets(数据集)
- 包含所有Kaggle赛事的数据集以及世界上数据科学领域常用的数据集(一般是玩家上传的),建立环境无需自己上传或者麻烦地获取数据集。
- Notebooks(笔记本)
- 原Kernel,可以自己开启私人(仅自己可见)或者公共(平台用户可见)的笔记本或者脚本文件(支持Python和R语言)。是一个运行环境在云端,无需自己安装常用包的GPU环境等。
- Discussion(讨论区)
- 包含一些讨论帖子,关于平台问题、代码问题、数据问题等都可以发布在这里,与其他人一起交流。
- Courses(课程区)
- 包含众多优质的入门到高阶的是视频或者文本教程,让你迅速了解Python语言、数据分析、数据科学竞赛。
- Other(其他)
- 此外,近期的Kaggle平台更新加入了Job(职业区)、Blog(博客区)、User Rankings(用户排名区)等模块。
- Competitions(竞赛)
竞赛类别
- 级别
- 简述
- Kaggle的每个竞赛都有类别等级,方便用户选择合适的比赛。
- 详述
- Getting Started(入门赛)
- 适合数据科学竞赛新手的比赛,没有太大难度,一般包含基本的回归、分类等类型,长期开放。
- Playground(娱乐赛)
- 一种“为了乐趣”的Kaggle比赛类型,难度比入门高出一些。这些比赛通常提供相对简单的机器学习任务,并且同样是针对新手设置的,适合那些对小项目有兴趣但是希望在时间投入较低的情况下可以练习新类型问题的玩家。
- In Class(课业赛)
- 是学校教授机器学习的老师留作业的地方,这里的竞赛有些会向public开放参赛,也有些仅仅是学校内部教学使用。
- Featured(精选赛)
- 对应商业问题的有奖金的公开竞赛。赢得比赛,不但可以获得奖金,模型也可能会被竞赛赞助商应用到商业活动中。
- Recruitment(人才招募赛)
- 赞助企业寻求数据科学家、算法设计人才的渠道,但是这类比赛只允许个人参赛,不接受团队报名。
- Research(研究赛)
- 竞赛通常是机器学习前沿技术或者公益性质的题目。竞赛奖励可能是现金,也有一部分以会议邀请、发表论文的形式奖励。
- Getting Started(入门赛)
- 简述
- 方向
- 简述
- 一般认为,Kaggle的比赛分为两个走向,ML(传统机器学习)和DL(深度学习)Kaggle玩家一般认为,这是“Kaggle的两个世界”。其中,最关键的区别在于是否很消耗GPU算力。这两类比赛没有上下之分,只是不同领域的交集不多罢了。当然也有很强的人两类比赛都游刃有余,但是大多数人还是倾向于一类比赛的。大体上,按照内容可以分为下面三大类。
- 详述
- 数据挖掘

- 这类比赛适合使用传统的机器学习算法,不同于神经网络,这类算法的特点是需要花费大部分时间在feature engineering(特征工程)和ensemble(集成学习)上。
- 这类比赛的典型代表就是房价预测、时序数据处理等。
- 可以看到tag里一般数据类型为tabular data(表格数据)。
- 图像处理

- 这类比赛主要是深度学习领域的比赛,主要手段是深度神经网络。由于端到端的学习特性,不需要花费很多时间在数据预处理上,需要做的只是给神经网络“喂”更多的数据。这类比赛很需要GPU算力,因为绝大多数时间花在了模型的构建和调整上。
- 这类比赛的典型代表是图片分类等。
- 可以看到tag里一般数据类型为image data(图像数据)。
- 自然语言处理

- 同上,现在NLP的比赛基本上也是使用深度模型进行处理。
- 这类比赛的典型代表是文本分类等。
- 可以看到tag里一般数据类型为text data(文本数据)。
- 数据挖掘
- 简述
排名机制
- 比赛过程中
- Kaggle将参赛者每次提交的结果取出一部分(25%-33%),并依照准确率进行临时排名。
- 比赛结束前
- 参赛者每天最多可以提交5次测试集的预测结果。每一次提交结果都会更新实时排名成绩,直至比赛结束获得最终排名。
- 在比赛结束时
- 参赛者可以指定几个已经提交的结果,Kaggle从中去除之前用于临时排名的部分,用剩余数据的准确率综合得到最终排名。
Kernel使用说明
- 简述
- 这里的Kernel说白了就类似于一个可以在浏览器上间接(本质上是在Kaggle的GPU服务器上)运行的一个Python或者R的环境,这个环境里包含了我们基本需要的各种软件,当然我们也可以自己去安装一些软件,然后去运行我们的训练程序。
- 类似于Google Colab,但是国内可以访问。而且提供免费GPU,确实很良心了。
- 注意:使用GPU需要开启GPU,下载网络数据或者安装其他包(一般不需要)需要开启网络权限,第一次开启要验证手机号(国内860加手机号)。
- 使用
- 使用Kernel之前要创建一个环境,如下。
- 进入Notebooks板块,点击新建notebook。
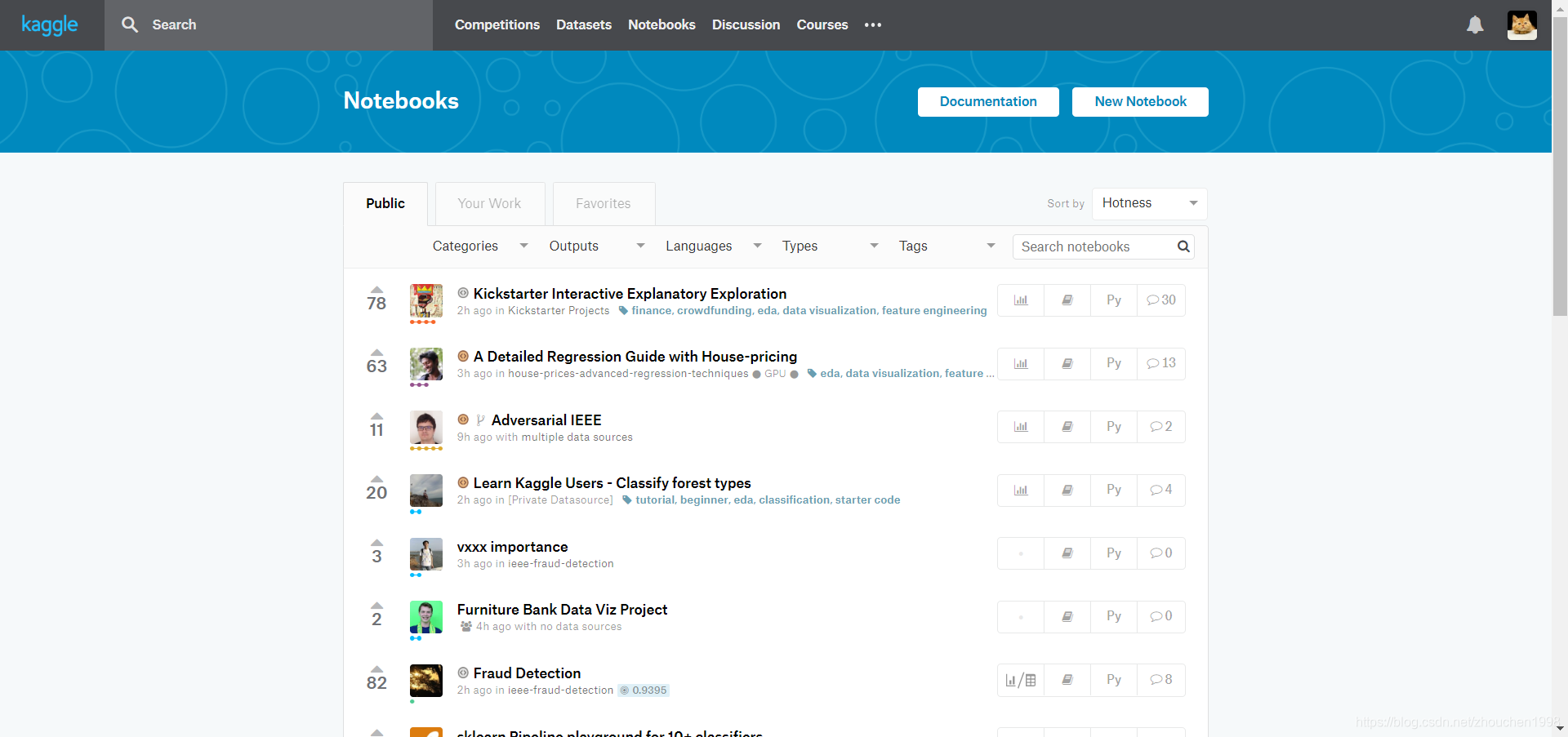
- 选择使用的语言(Python或R)及环境形式(notebook或script)。
- 进入Notebooks板块,点击新建notebook。
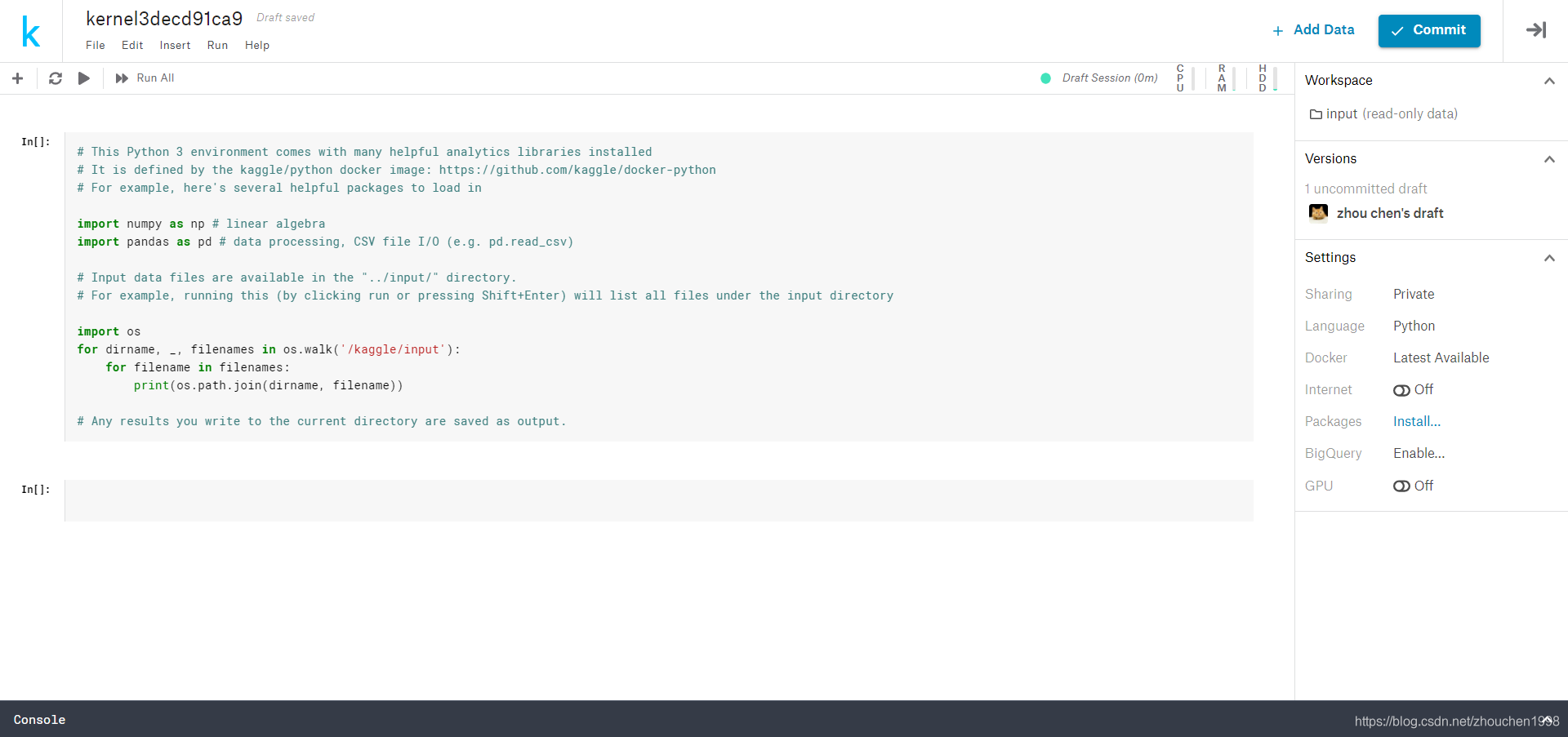
- Kaggle还是对Jupyter Notebook进行了封装,使用的大部分方法一致。顶部命名文件,右侧有环境的状态。
- 使用Kernel之前要创建一个环境,如下。
- 几个注意
- 没有开启GPU时可以使用的总内存是16GB,开启后就变为14GB,磁盘容量是固定的,但是这个磁盘是交换数据时需要的,我们从Kaggle加载数据集使用右侧顶部的ADD DataSet,Kaggle的数据集并不会放到这个Disk里头。
- 安装了Keras、TensorFlow、Fastai、PyTorch等主流框架。
- 数据集也可以自己上传,比较简单。但是很多比赛限制为Kernel比赛,不可以本地跑。
- 代码运行类似Jupyter,但是需要注意,kernels运行代码有一个很大的限制,那就是运行代码不能超过9个小时,我们可以通过右上角的使用时间看到我们还剩多少时间可用了。而且,每次开启内核需要排队,右侧状态为Queue,等待空闲资源。
- 很重要的一点,如果离开Kernel界面时间超过一个小时,这个Kernel就会重启(丢失运行数据,用户Disconnect),这是为了资源的合理利用,分配给在线的用户。如果有一个代码需要运行1个小时以上,不可能总在界面上等着,解决办法是允许无误后点击右上角Commit按钮。也就是当我们在调试好Kernel中的代码之后,发现这些代码按顺序可以正常运行,我们只需要点击这个按钮,将这批代码提交,那么这些代码就会在这个服务器的后端执行,当执行完毕后页面就会加载。(此时用户会Disconnect)这样的运行最多也是9小时。
补充说明
- 本文介绍了一下Kaggle的平台及其使用方式。
- 博客已经同步至我的个人博客网站,欢迎访问查看最新文章。
- 如有错误或者疏漏之处,欢迎指正。
