本文主要介绍数据挖掘类比赛的流程,文章教程,大部分都是原理性总结,文章较长但干货满满。另附一句很喜欢的话,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
简介
数据挖掘的一般任务就是从已有数据中发现一些人类难以发现的规律,进而应用这些规律,如房价预测、用户标注等。数据挖掘比赛的流程,本文主要使用很简单的Boston数据集进行操作说明。常见的数据挖掘项目工作的流程大体上也与描述相差不大。其中最核心的步骤为特征工程,数据探索是为特征工程,特征工程是为了更好的建模。
数据获取
说明
数据是一切工作的开端,合理的数据源在数据挖掘中十分重要。
方式
- 官方提供
- 一般数据挖掘比赛会给出很合适的表格化数据(csv格式),以此为基础工作即可。
- 数据采集
- 采集的手段多种多样,其中为了数据的真实性一般有两种主要方式。
- 公开数据库
- 为了科研事业的发展,很多科研机构都公开了采集到的人工标注的数据集,如本文的Boston数据集。
- 爬虫采集
- 网络上充斥着各种格式不一的数据,利用爬虫可以采集并存储标注这些数据,从而供机器学习工作者使用。
探索性数据分析(EDA)
说明
EDA思路较多,但大多数是以图表方式发现数据的一些定性的特性,如离群点分析,相关性分析等,其核心目的是为特征工程提供一些思路。我曾经写过两篇关于简单EDA的文章,一篇是关于PUBG数据集的文章,另一篇是关于天池新人赛“挖掘幸福感”的文章。
pandas_profiling
关于利用pandas结合matplotlib进行EDA的教程谷歌可以搜索到很多,这里过多赘述确实篇幅过长,这里推荐一个工具pandas_profiling(使用pip安装即可),该工具可以针对DataFrame生成十分详细的EDA结果报表。
特征工程
说明
本文最核心要讲的部分,由于篇幅限制,这里只介绍一些概念和简单操作,特征工程是一门数据科学很重要的学科,想要深入了解建议阅读这本《特征工程入门与实践》。一般认为,特征工程主要分为三大步骤数据预处理、特征选择和数据降维。其中,数据预处理是三个步骤中最为繁琐复杂且最重要的步骤。这一阶段的绝大多数任务都可以通过scikit-learn包实现,上述三个任务分别对应sklearn.preprocessing、sklearn.feature_selection和sklearn.decomposition(具体可查看scikit-learn官方教程)。
数据预处理
缺失值处理
针对缺失值处理由多种方式,其中最为暴力也是最不可取的方式就是删除存在空值的记录(删除存在空值的行),这会导致大量数据的丢失。比较常见的做法是缺失值填充,可以使用该列的均值、众数等简单填充,也可以使用拉格朗日插值法等数学方法进行填充,只要填充的方式对该列属性来说合理即可。
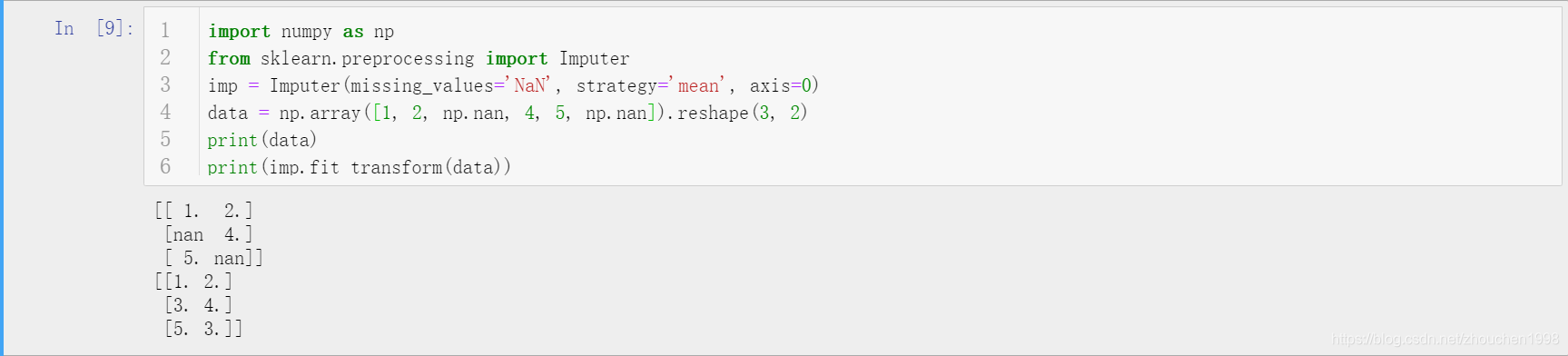
数据规范化
数据规范化又叫做无量纲化,最简单的理解是不同属性的数据范围可能差异巨大(如A属性在1000-8000之间,B属性在0-1之间,两者对模型的贡献在不加权时理当等同,而量纲的不同使该条件不能满足)。常见的规范化手段有下述三种,几种方式的取舍常常是个问题,建议如下。在需要使用距离来度量相似性的时候或者使用PCA或LDA这些需要使用协方差分析进行降维时,且数据分布近似为正态分布,标准化方法表现更好;在不涉及距离度量、协方差计算、数据不符合正太分布时,区间缩放和归则化效果较好。如图片像素从0-255归一到0-1之间就是典型的归一化方法。
标准化
又叫做Z-score标准化,数学原理为 。将服从正态分布的特征值转换为标准正态分布。
区间缩放
区间缩放的思路其实很多,但是最容易理解的就是根据最值进行缩放,数学原理为 。上式缩放结果为[0-1],通过上式添加倍数或者偏移,可以调整缩放范围。
归一化(针对行向量)
上述两种方法均是针对列向量的规范化处理,归一化则是针对列向量的处理。其目的在于样本向量在点乘运算或者其他核函数计算相似性时,拥有统一的标准,也就是都转化为单位向量,L2规一化数学原理为 。

注意,标准化和归一化(规则化)容易混淆,只需要明确标准化是使同一特征下(同一列)的数值在一定范围浮动,如将特征变为0-1之间或者变为均值为0、方差为1的数据;规则化是指将同一样本下(同一行)的不同特征进行规范化,这样一个数据的不同特征具有相同的量纲及表现力,如身高为1.2而体重为120,两种相差很大,前者根本无法起到决定作用。
定量特征二值化
定量特征二值化是因为有些特征不需要过于复杂,间断值即具有不错的效果了。定量特征二值化的手段一般是设置阈值进行处理。

定性特征onehot编码
有些特征是无法用数值表达的,用字符串进行标记,但是不同字符之间是没有大小距离之别的,但是数字有,为了保留这种无区别,onehot编码应运而生,它是一种向量表示。

数据变换
常见的数据变换有基于多项式的、基于指数函数的、基于对数函数的等。4个特征,度为2的多项式变换公式为 ,这在scikit-learn中是封装的。同时,基于单变元函数的数据变换可以使用同一接口完成,即可以使用FunctionTransformer定制。

特征选择
- Filter
- 过滤法,不考虑后续学习器,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- 方差选择法
- 计算各个特征的方差,根据阈值,选择方差大于阈值的特征。
- 单变量特征选择
- 单变量特征选择能够对每一个特征进行测试,衡量该特征与目标变量之间的关系,根据得分丢弃不好的特征。对于有监督学习如分类和回归问题,可以采用卡方检验等方式对特征进行测试。其中卡方检验适合y离散的分类问题,pearson系数适合y连续的回归问题。
- 互信息和最大信息系数
- 距离相关系数
- Wrapper
- 包装法,需考虑后续学习器,根据目标函数(通常为预测效果得分),每次选择或者排除若干特征。其主要思想为,根据目标函数,每次选择或者排除若干特征。也可以将特征子集的选择看做一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看做是一个优化问题,这里有很多的优化算法可以选择,尤其是一些启发式的算法,如GA(遗传算法),PSO(粒子群算法)和ABC(人工蜂群算法)算法。
- 递归特征消除法
- Embedded
- 嵌入法,是Filter和Wrapper方法的结合,先使用某些机器学习模型训练,得到各个特征的权值系数,根据系数从大到小选择特征。其主要思想理解来就是在确定模型的过程中,挑选出那些对模型的训练意义重大的特征。
- 基于惩罚项的特征选择法
- 基于树模型的特征选择法
降维
经过前面的步骤,得到训练数据的维度是相当高的,一方面高维特征导致矩阵运算量大,训练时间长;另一方面,过于冗余的特征对模型的效果是会产生一定程度的负面影响,干扰模型的拟合。因此,降维大多数时候是必要的手段,常用的降维方法有PCA(主成分分析)和LDA(线性判别分析),前者无监督,后者有监督,后者的本质是一个分类模型。上述两种方法都是将原本的样本空间映射到低维的样本空间内,但是两者目标不同:PCA是为了让映射后的样本具有最大的发散性;LDA是为了让映射后的样本具有最好的分类性能。
特征构造
往往,筛选更有价值的特征有利于模型的拟合,但是很多时候输入模型的数据其特征对于模型来说是远远不够的,体现在比赛中最常见的手段则是特征构造,这和数据变换操作上是类似的,但是实际目的是不同的,往往,特征构造是利用多个已有特征进行组合(如加权高次组合,注意不能线性组合),产生新的特征。在实际比赛中,利用傅里叶变换,高次组合等进行特征构造是常见提高score的手段,但是若想构造非常合理有效的特征则需要对赛题背景及每个特征的含义有充分的理解。
模型构建
说明
一般到这个阶段,已经得到了较为完美的可用于模型训练和预测的数据,根据任务选择合适的模型就是这一步的关键了。一般,比赛中比较常见的是两类问题即分类和回归,其余的一些非监督问题不方便量化衡量好坏,出现不多。
基础模型
常用的机器学习基础模型有KNN(K近邻)、DT(决策树)、NB(朴素贝叶斯)、SVM(支持向量机)、LR(线性回归)等。不同的基础模型的使用场合见我这篇详细分析的文章。为了追求较好的结果,单纯的某个机器学习模型的应用领域已经越来越窄,现在的一般思路都是将这些模型作为基模型,利用集成方法进行模型集成,继而得到较为合适的强模型。
集成模型
为了追求更强的模型效果,通常会将多个模型集成,集成的思路很多,简单的有多模型投票法、加权平均法等,随着集成学习的研究深入,大题上形成了三种主流集成方法Bagging(随机森林)、Boosting(AdaBoosting)、Stacking(Blending长被认为与Stacking类似)。
XGBoost和Lightgbm都是在树模型基础上基于Boosting策略形成的算法,该两者的代码实现库被称为Kaggle利器。
当然,也可以自己进行模型的集成,设计集成思路,方便的mlxtend和ML-ensemble库都提供了很方便的集成模型接口,兼容scikit-learn。关于Stacking和mlxtend的使用可以参考我的博客,这里不多赘述。
模型应用
比赛刷分固然是很有成就感的事情,但是各类企业发布真实数据提供巨额奖金给参赛者,目的当然是找到合适的可落地应用的模型,这就要求模型的优化达到一定程度,再准确率的前提下不可太过冗余。
一般,模型的部署是个生产环境比较常见的操作,只要研究人员提供较为完美的训练后的模型文件即可,有兴趣可以查阅相关资料,这里不多说明了。
补充说明
本文较为简略的说明了数据挖掘类比赛的主要流程及方法,由于篇幅限制没有过细展开,具体的相关问题可以查看我的其他博客。博客同步至我的个人博客网站,欢迎查看。如有错误,欢迎指正。
