此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。
本文章纯野生,无任何借鉴他人文章及抄袭等。坚持原创!!
前言
你好。这里是Python爬虫从入门到放弃系列文章。我是SunriseCai。
本文章主要介绍利用爬虫程序下载 英雄联盟的 所有英雄的皮肤。
英雄联盟英雄库:https://lol.qq.com/data/info-heros.shtml
1. 文章思路
看看英雄联盟网站,如下多图所示:
- 首页(一级页面)
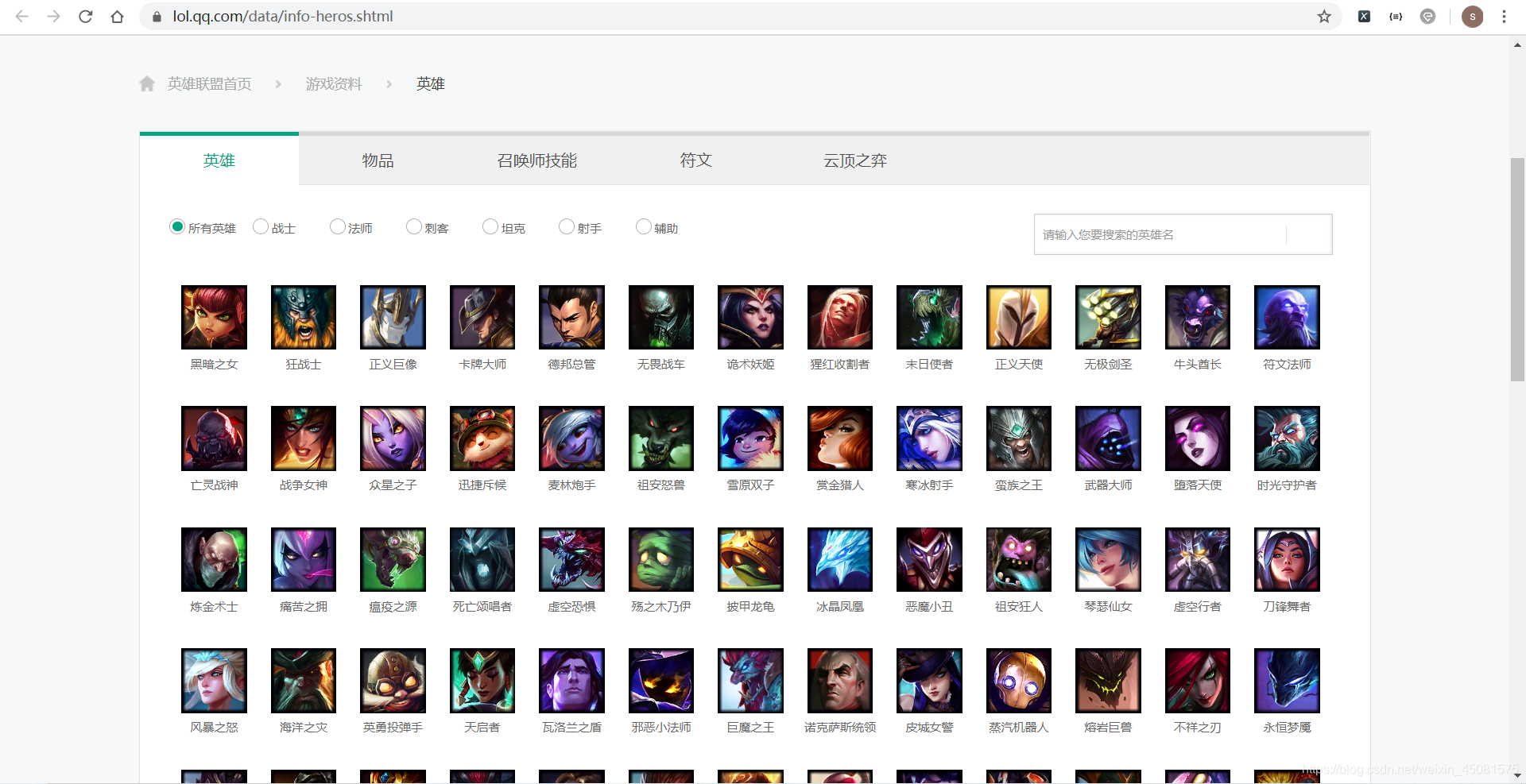
- 皮肤页面(二级页面)
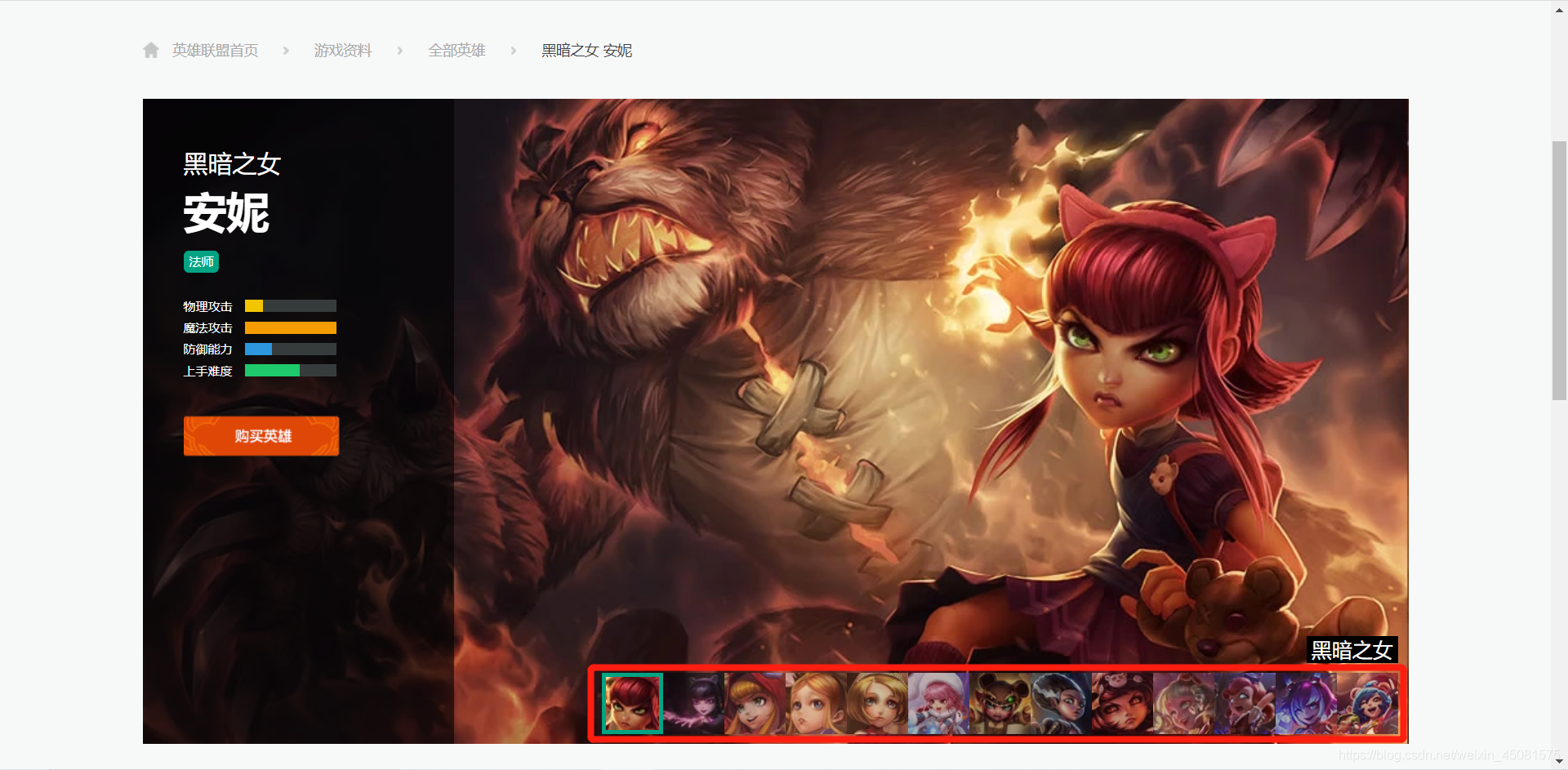
- 图片(三级页面)
通过上面几张图片可以看出,这一套下来依旧是个俄罗斯套娃!!!
- 访问 首页(一级页面) 获取 所有英雄链接(二级页面)
- 访问 英雄链接(二级页面) 获取 图片链接(三级页面)
- 访问 图片链接(三级页面),保存图片。

那么,接下来的就是用代码实现下载图片了。
2. 请求 + 分析 网页
上面又说到,本文章的需请求的首页为https://lol.qq.com/data/info-heros.shtml。
2.1 请求首页
浏览器打开 网站首页,点击F12,进入开发者模式。看看页面结构,发现了二级页面的链接就在<li>标签里面。perfect !!!那接下来就是去 请求网页 。
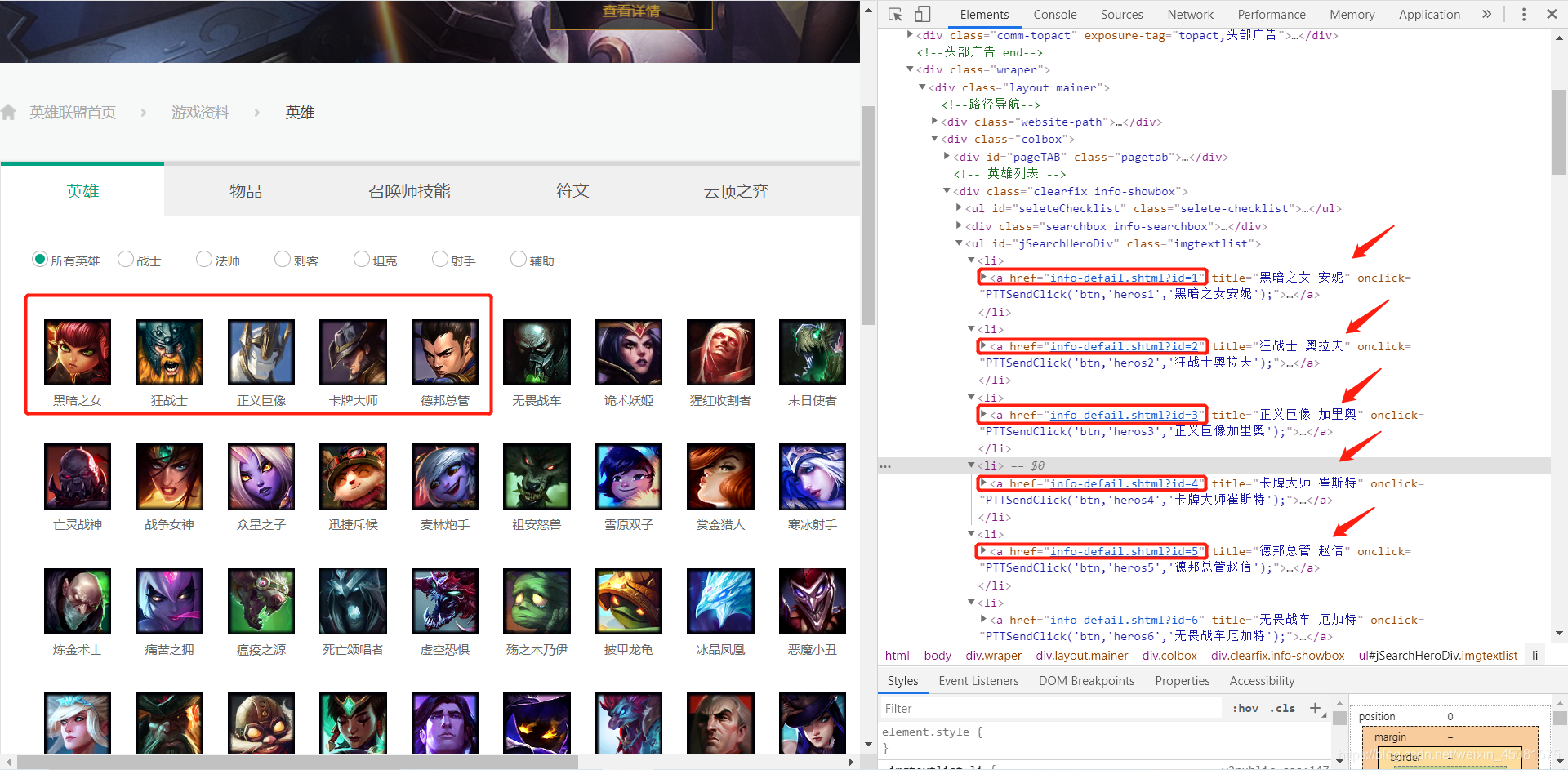
首页请求代码:
import requests
url = 'https://lol.qq.com/data/info-heros.shtml'
headers = {
'User-Agent': 'Mozilla/5.0'
}
res = requests.get(url, headers=headers)
if res.status_code == 200:
print(res.text)
else:
print('your code is fail')
执行上述代码之后,发现并没有上图中的<li>标签的内容,这是怎么回事呢?<li>标签的内容极有可能是通过xhr异步加载出来的的文件,咱们来抓包看看!!
-
再次请求首页时候发现,在xhr这里,有一个hero_list.js文件,翻译过来就是英雄列表。
-
看到hero_list.js的url为 :https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js
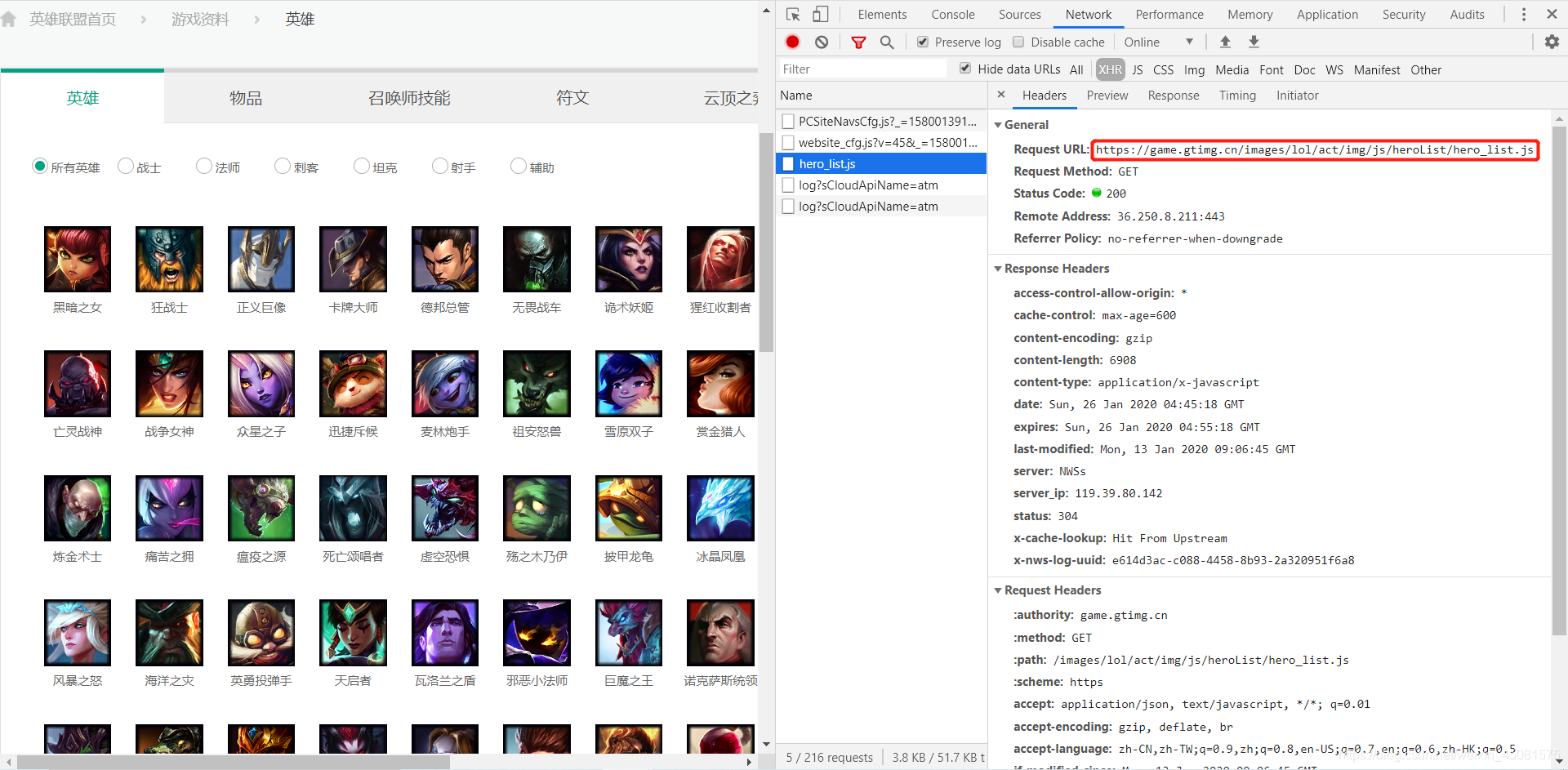
-
点击之后,发现这正是我们需要的内容!!!
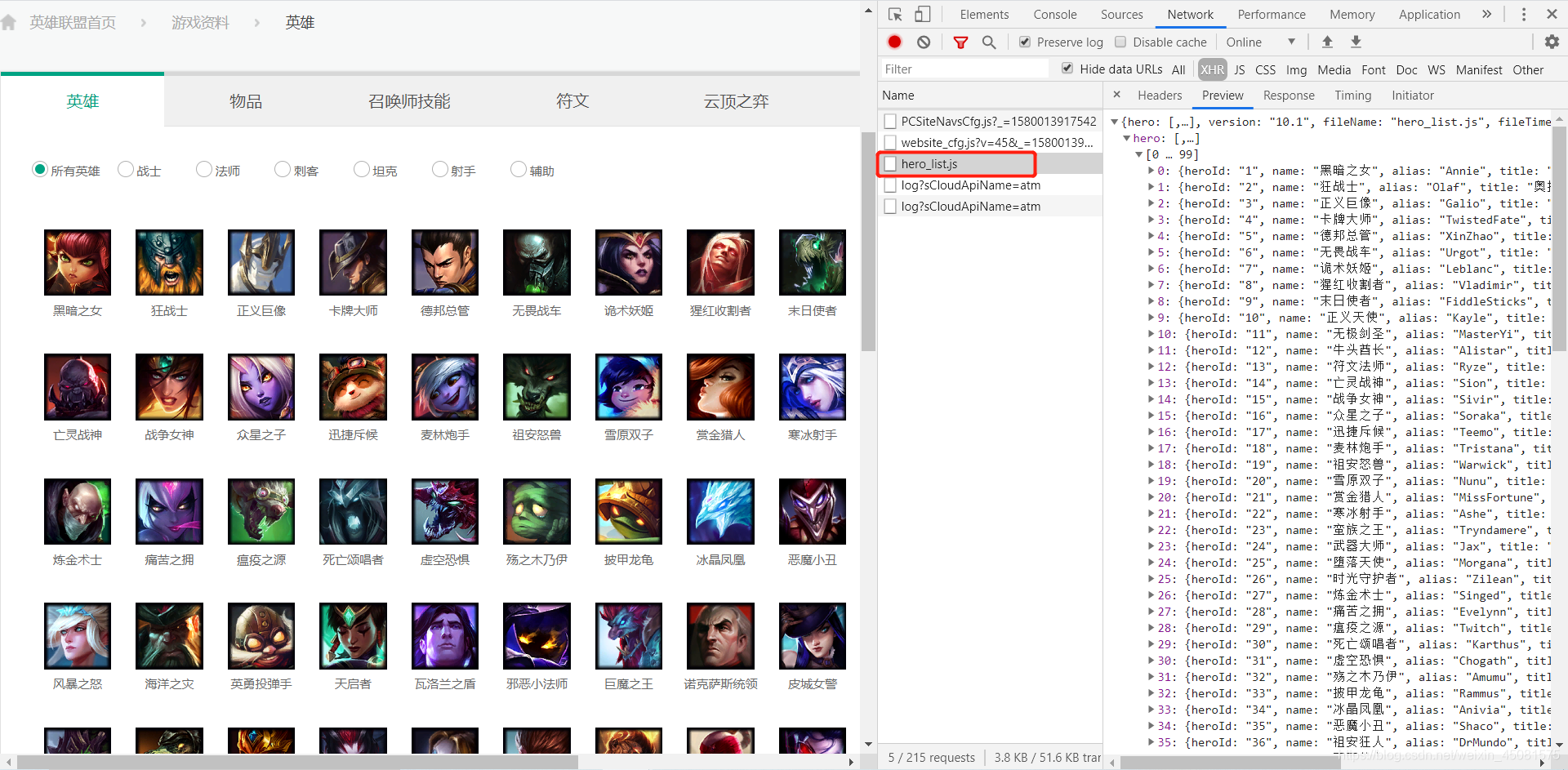
下面请求hero_list.js。
请求的代码很简单,只需要将上面的代码的url更改为 https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js 即可。
未完待续。。。
不可否认,本篇文章写的还过得去,建议各位通过复制黏贴代码去执行一番,重温南派三叔的魅力。
最后来总结一下本章的内容:
- 介绍了盗墓笔记网站的爬虫思路
- 详细讲解了如何利用爬虫程序下载全网小说
- 已经很详细了,有任何疑问欢迎在下方留言。

- 感谢你的耐心观看,点关注,不迷路。
- 为方便菜鸡互啄,欢迎加入QQ群组织:648696280
下一篇文章,名为 《Python爬虫从入门到放弃 09 | Python爬虫实战–下载某图片网–待定》。
