此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。
本文章纯野生,无任何借鉴他人文章及抄袭等。坚持原创!!
前言
你好。这里是Python爬虫从入门到放弃系列文章。我是SunriseCai。
本文章主要介绍利用爬虫程序下载 南派三叔的 盗墓笔记 小说全集。
盗墓笔记全集地址:http://www.daomubiji.com/
1. 文章思路
看看盗墓笔记小说网站,如下图所示:
- 首页(一级页面)


- 章节页面(二级页面)

- 正文页面(三级页面)

通过上面几张图片可以看出,这一套下来就是个俄罗斯套娃!!!
- 访问 首页(一级页面) 获取 二级页面
- 访问 章节页面(二级页面) 获取 正文页面(三级页面)
- 访问 正文页面(三级页面),提取正文数据。
- 保存正文 数据。

接下来看看如何实现请求这些网页。
2. 请求 + 分析 网页
通过上边可知道,盗墓笔记小说网站的首页为:http://www.daomubiji.com/
2.1 访问首页(一级页面)
浏览器打开 盗墓笔记 的首页,点击F12,进入开发者模式。看看页面结构,发现了二级页面的链接。perfect !!!那接下来就是 请求网页 以及 解析网页(提取数据)了。
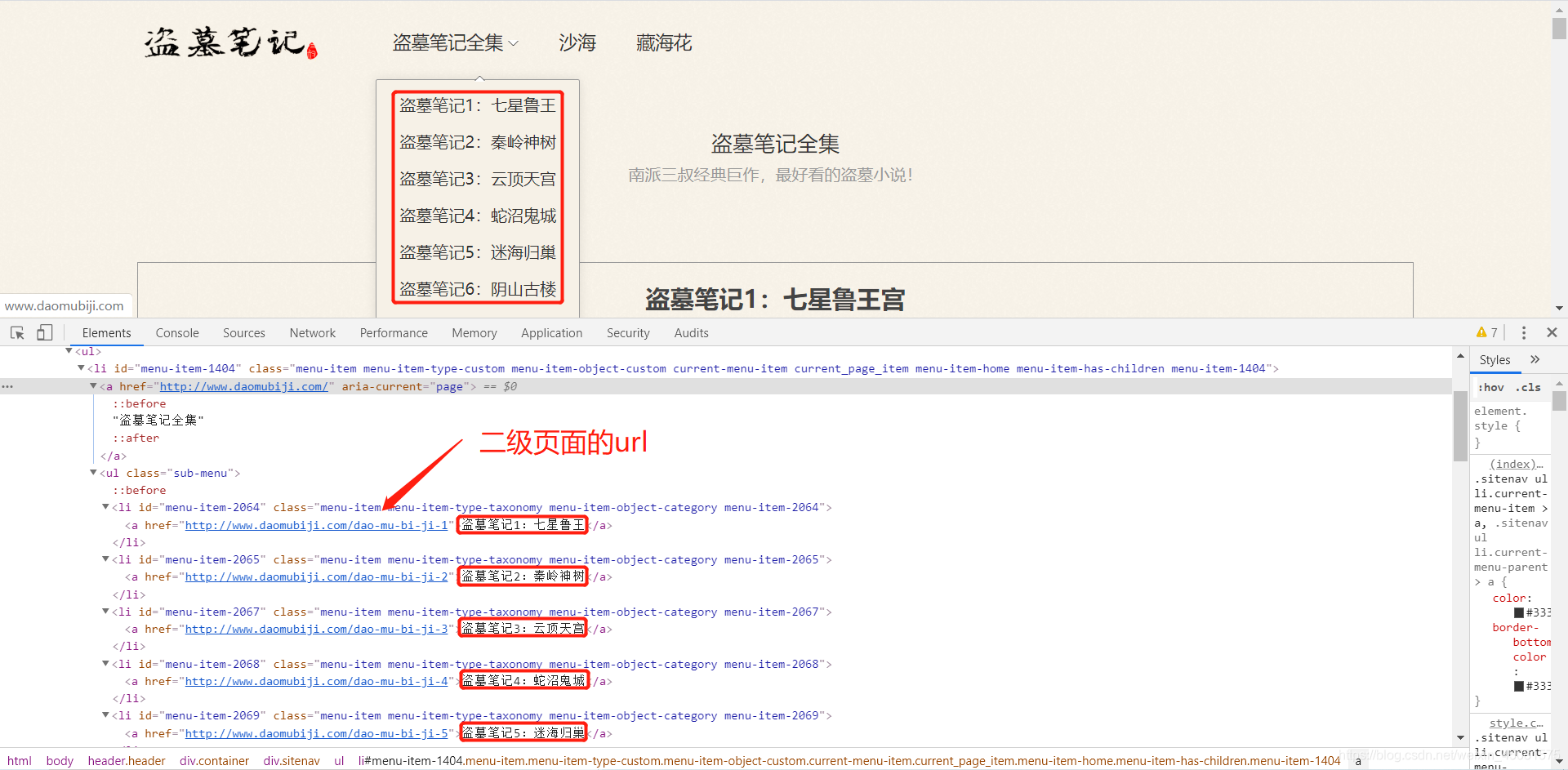
- 代码实现 访问首页 获取 二级页面 链接
- 这里使用前面文章介绍过的requests请求网页 及XPath模块去 解析网页
import requests
from lxml import etree
url = 'http://www.daomubiji.com'
def get_overview():
# 访问盗墓笔记首页
res = requests.get(url)
# 如果访问状态码为200(即成功)就继续
if res.status_code == 200:
# 构造XPath解析对象
parse_html = etree.HTML(res.text)
link = parse_html.xpath('//*[@id="menu-item-1404"]/ul/li/a/@href') # 二级页面链接
name = parse_html.xpath('//*[@id="menu-item-1404"]/ul/li/a/text()') # 二级页面名称
return link, name
else:
print('your code is fail')
link,name = get_overview()
print(link, name)
# ['http://www.daomubiji.com/dao-mu-bi-ji-1', 'http://www.daomubiji.com/dao-mu-bi-ji-2',
'http://www.daomubiji.com/dao-mu-bi-ji-3', 'http://www.daomubiji.com/dao-mu-bi-ji-4',
'http://www.daomubiji.com/dao-mu-bi-ji-5', 'http://www.daomubiji.com/dao-mu-bi-ji-6',
'http://www.daomubiji.com/dao-mu-bi-ji-7', 'http://www.daomubiji.com/dao-mu-bi-ji-8',
'http://www.daomubiji.com/dao-mu-bi-ji-2015']
# ['盗墓笔记1:七星鲁王', '盗墓笔记2:秦岭神树', '盗墓笔记3:云顶天宫', '盗墓笔记4:蛇沼鬼城',
'盗墓笔记5:迷海归巢', '盗墓笔记6:阴山古楼', '盗墓笔记7:邛笼石影', '盗墓笔记8:大结局',
'盗墓笔记2015年更新']
这里已经获取到了二级页面的链接,接下来就是去访问 章节页面(二级页面) 获取 **正文页面(三级页面)**了。
2.2 访问章节页面(二级页面)
看到二级页面链接的章节目录,发现了 正文页面(三级页面),这正是我们想要的,下面用代码去实现访问 章节页面(二级页面) 获取 正文页面(三级页面)。
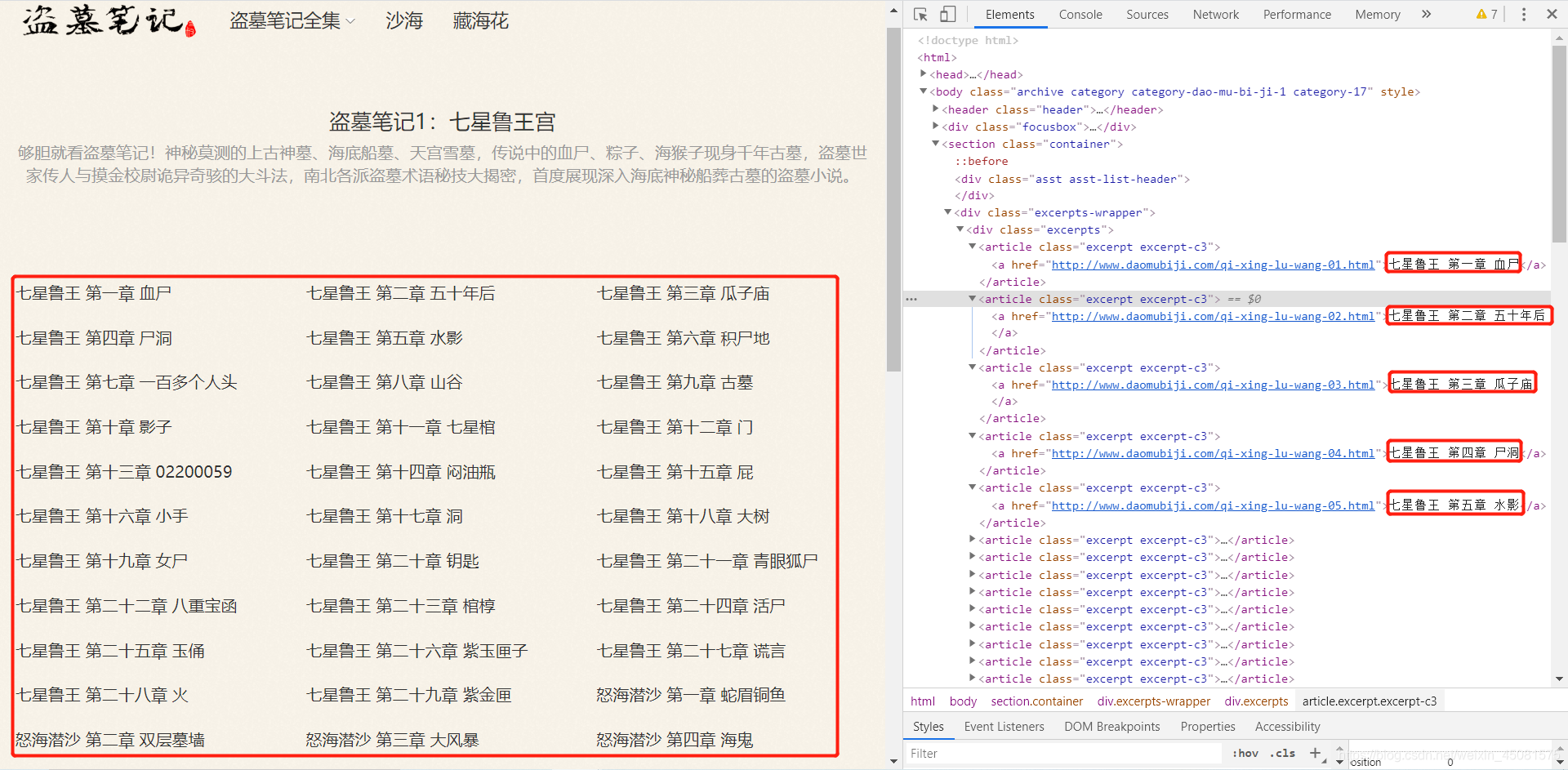
def get_catalogs(url):
"""
:param url: 传入二级页面的链接
:return: 返回所有章节目录于标题
"""
res = requests.get(url=url)
if res.status_code == 200:
parse_html = etree.HTML(res.text)
link = parse_html.xpath('/html/body/section/div[2]/div/article/a/@href') # 正文链接
title = parse_html.xpath('/html/body/section/div[2]/div/article/a/text()') # 正文标题
return link, title
else:
print('your code is fail')
这里获取到正文(三级页面)的链接和标题后,接下来就是请求正文了。
2.3 访问 正文页面(三级页面),提取 + 保存正文
通过下图可以发现,正文的内容都藏在article标签下面,那接下来尝试去请求该页面。
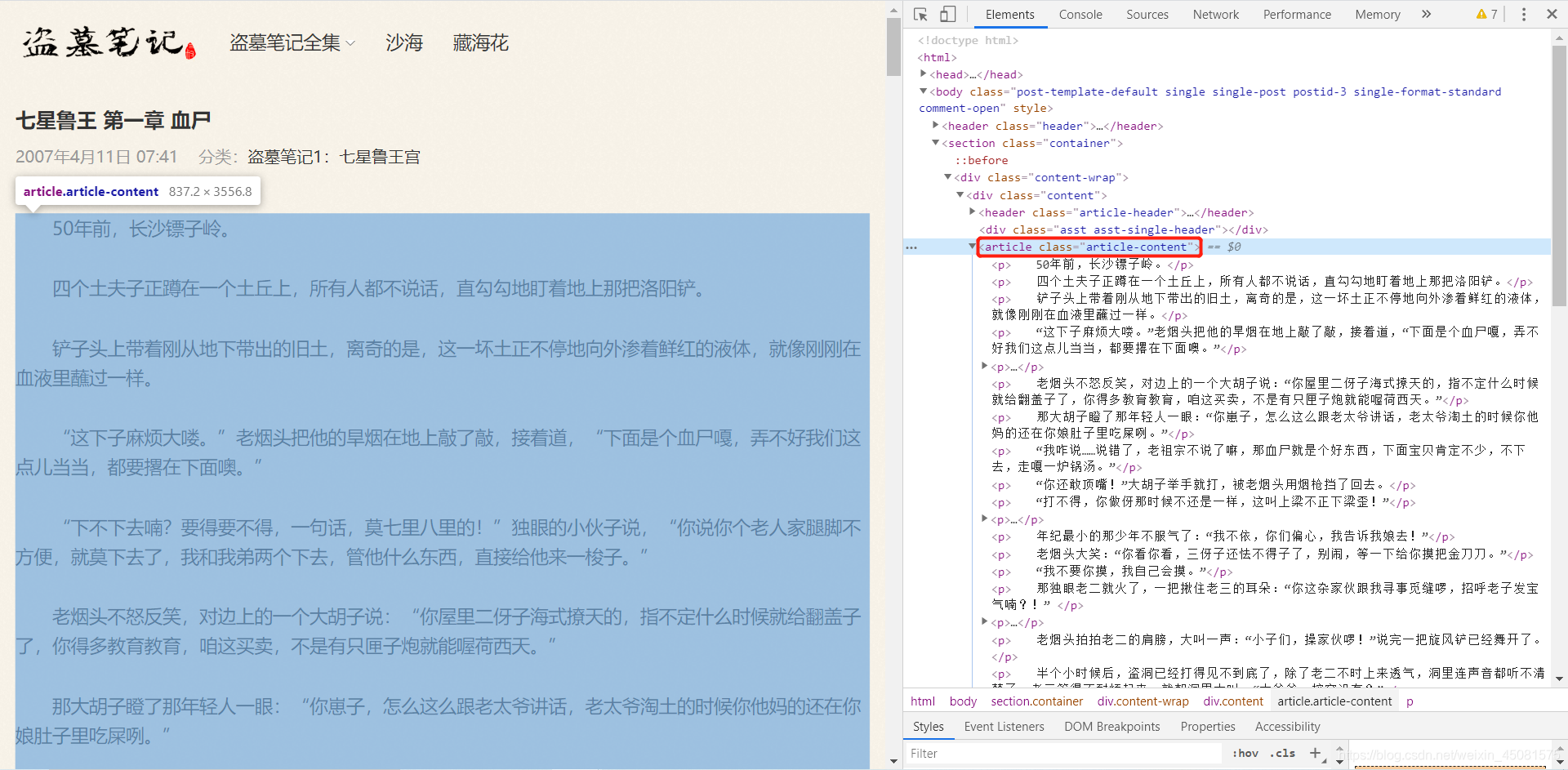
- 正文提取代码示例:
def get_content(url,title):
"""
:param url: 传入正文链接
:return: 返回正文内容
"""
res = requests.get(url=url)
if res.status_code == 200:
parse_html = etree.HTML(res.text)
content = parse_html.xpath("/html/body/section/div[1]/div/article/p/text()") # 正文内容
return title, content
else:
print('your code is fail')
get_content(url)
- 正文保存代码示例:
def save_content(content, name):
"""
:param content: 传入正文内容
:param name: 传入标题
:return:
"""
with open('%s.txt' % name, 'a', newline='') as f:
for data in content:
f.write(data+'/n') # 加一个换行,段落间需要换行
f.close()
3. 完整代码
- 这里针对上边的代码做了整合和部分修改
- 代码直接拷贝即可运行
# -*- coding: utf-8 -*-
# @Time : 2020/1/25 20:20
# @Author : SunriseCai
# @File : DaoMBJSpider.py
# @Software: PyCharm
"""盗墓笔记爬虫程序"""
import os
import requests
from lxml import etree
class DaomubijiSpider(object):
def __init__(self):
self.url_homePage = 'http://www.daomubiji.com'
self.headers = {'User-Agent': 'Mozilla/5.0'}
self.content_titles = None
self.content_links = None
def get_overview(self):
"""
:return: 访问首页,获取二级页面的标题的链接
"""
res = requests.get(self.url_homePage, headers=self.headers)
if res.status_code == 200:
parse_html = etree.HTML(res.text)
links = parse_html.xpath('//*[@id="menu-item-1404"]/ul/li/a/@href')
titles = parse_html.xpath('//*[@id="menu-item-1404"]/ul/li/a/text()')
for link, title in zip(links, titles):
self.get_catalogs(title, link)
self.get_content()
else:
print('your code is fail')
def get_catalogs(self, title, url):
"""
:param title: 传入二级页面标题
:param url: 传入二级页面链接
:return: 将解析度到的章节目录标题和链接保存到self
"""
if not os.path.exists(title):
os.makedirs(title)
res = requests.get(url=url, headers=self.headers)
if res.status_code == 200:
parse_html = etree.HTML(res.text)
self.content_links = parse_html.xpath('/html/body/section/div[2]/div/article/a/@href')
self.content_titles = [parse_html.xpath('/html/body/section/div[2]/div/article/a/text()'), title]
else:
print('your code is fail')
def get_content(self):
"""
:return: 提取正文页面的正文
"""
folder = self.content_titles[1]
for link, title in zip(self.content_links, self.content_titles[0]):
time.sleep(2) # 休眠2秒,不能给对方服务器造成太大压力
res = requests.get(url=link, headers=self.headers)
if res.status_code == 200:
parse_html = etree.HTML(res.text)
content = parse_html.xpath("/html/body/section/div[1]/div/article/p/text()")
self.save_content(folder, title, content)
else:
print('your code is fail')
def save_content(self, folder, title, content):
"""
:param folder: 传入文件夹
:param title: 传入标题
:param content: 传入正文内容
:return:
"""
with open('%s/%s.txt' % (folder, title), 'a', newline='') as f:
for data in content:
f.write(data+'\n')
f.close()
def main(self):
self.get_overview()
if __name__ == '__main__':
spider = DaomubijiSpider()
spider.main()
来看看成果:
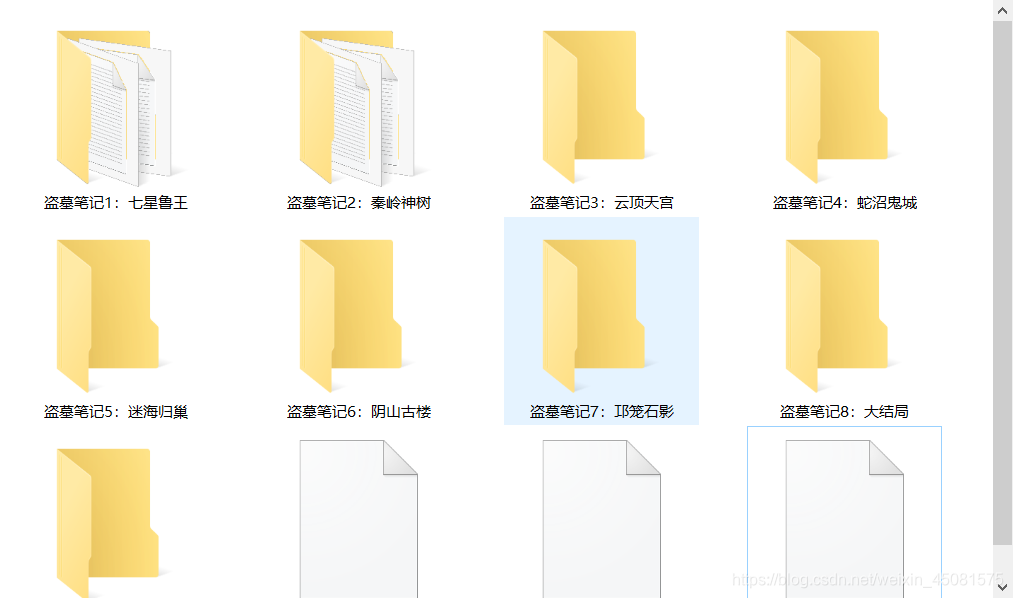
至此,本文结束。
不可否认,本篇文章写的还过得去,建议各位通过复制黏贴代码去执行一番,重温南派三叔的魅力。
最后来总结一下本章的内容:
- 介绍了盗墓笔记网站的爬虫思路
- 详细讲解了如何利用爬虫程序下载全网小说
- 已经很详细了,有任何疑问欢迎在下方留言。

- 感谢你的耐心观看,点关注,不迷路。
- 为方便菜鸡互啄,欢迎加入QQ群组织:648696280
下一篇文章,名为 《Python爬虫从入门到放弃 08 | Python爬虫实战–下载某图片网–待定》。
