目录
1. Adaboost
- 处理分类问题的思想
给定训练集,寻找比较粗糙的分类规则/弱分类器 要比寻找精确的分类规则要简单得多。从弱学习算法出发,反复学习,得 到一系列弱分类器;然后组合这些弱分类器,构成一个强分类器。
- 基本做法
改变训练数据的概率(权重)分布(每个训练样本的采样频率),基于不同的训练数据的分布,调用弱学习算法来学习一系列分类器。
- 两个问题
1)每轮训练中,如何改变训练数据的权值或分布?
提高那些被前一轮弱分类器分错的样本的权重,降低已经被正确分类的样本的权重。错分的样本将在下一轮弱分类器中得到更多关注。
2)如何将一系列的弱分类器组合成一个强分类器?
采用加权表决的方法。具体地,加大分类错误率较小的弱分类器的权重,使其在表决中起更大的作用。
- 详细算法流程
输入训练数据集:
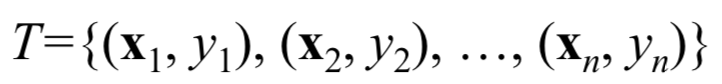
其中是样本特征向量,
(二分类)。
输入一个弱学习算法。
1. 初始化训练数据的权值分布。

假设训练数据集具有均匀分布的权重,也就是说,原始数据集T的每个样本在新数据集
中都会被采样,每个样本的采样频数
,除以数据量n得到权值分布
.保证第一步能在原始数据上学习到基本分类器。
2. 在权值分布为的训练集
上,学习得到基本分类器
,
(在训练集上的分类错误率最低)
1)计算的分类错误率:

上述两种形式是等价的,当没有出现在
中时,
.其实也就是错分样本的权值之和:

2)计算的贡献系数:
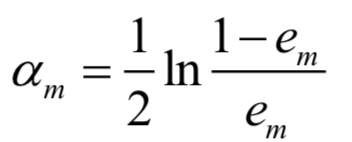
表示
在最终分类器中的重要性(权重)。
是
的单调递减函数,即分类误差率越小的基本分类器在最终分类器中的作用越大。当
(二分类情况下,
性能优于随机猜测),
;当
(二分类情况下,
性能比随机猜测差),
.此时, 该基分类器
将起到负面作用。因此必须保证每个基本分类器要优于随机猜测。
3)更新训练数据集的权重:
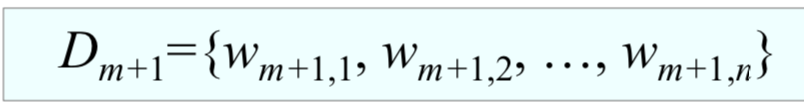
具体计算如下:
是在权值分布为
的训练集
上训练得到的分类误差率最小的分类器,因此他的性能要好于随机猜测,即
。因为
,所以
。对于分类正确的样本,即
,我们要在下一轮减少他对应的权重,因此取
和
相乘;而对于分类错误的样本,即
,我们要在下一轮增加他对应的权重,提高对错误样本的关注度,因此取
和
相乘。

我们也可以从另一个角度来理解:对于分对的样本,减小权重,分错的样本,增加权重。得到新的权值分布
,在权值分布为
的训练集
上训练得到的分类误差率最小的分类器
,即
在
上的性能会比较好,而
在
上的性能会比较差(因为
增加了
分错样本的权重,减小了其分对样本的权重)。这样一来,两个基本分类器
和
差别就会比较大,集成起来的效果就会更好(如果所有基本分类器都相同,集成起来的效果和其中一个没什么差别,所以各个基本分类器差异越大,集成起来的效果越好)。
不断地改变训练样本的权值,使其在基本分类器中起不同的作用,这正是AdaBoost的一个特点。
3. 不断重复步骤2,得到,然后构建基本分类器的线性组合:

对于两类分类问题,得到最终的分类器:

线性组合 f(x) 实现了对M个基本分类器的加权表决。系数 表示基本分类器
的重要性。 注意,所有
之和并不为 1。f(x) 的符号决定了实例(即样本) x 的类别, f(x) 的绝对值表示分类的置信度。
利用基本分类器的线性组合构建最终的分类器, 也是AdaBoost的另一个特点。
- 例题




2. 模型选择的基本原则
这是本章作业题中的一道题:“请从机器学习的角度简述模型选择的基本原则”:
对于模型,一些机器学习方法计算复杂度低,一些可更好地应用先验知识,另一些则具有更好的分类或聚类性能。没有任何一个分类方法一定优于其它方法!(之所以有些要做得好一些,与问题本身、先验分布以及其它知识有关) 对于在训练集上表现同样良好的两个分类器,人 们会更喜欢越简单的那个分类器,甚至期望它对于测试数据会做出更好的结果。因此,有以下几个原则:
1)没有免费的午餐定理(No Free Lunch, NFL):对“寻找代价函数极值”的算法,在平均到所有可能的代 价函数上时,其表现都恰好相同。
-
学习算法必须要引入一些与问题领域有关的假设。
-
不存在一个与具体应用无关的、普遍适用的“最优分类器”。
-
在没有假设的前提下,我们没有理由偏爱某一学习或分类算法而轻视另一个。
-
要想在某些指标上得到性能的提高,必须在另一些指标上付出相应的代价。因此,要求我们深刻地理 解所研究对象的本质:先验知识、数据分布、训练数据量、代价准则
2)丑小鸭定理(Ugly Ducking)
-
不存在与问题无关的最优的特征/属性集合。
-
不存在与问题无关的模式之间的“相似性度量”。
3)Occam 剃刀原理(Occam’s Razor)
- 如无必要,勿增实体
-
设计者不应该选用比“必要”更加复杂的分类器。
-
如果对训练数据分类的效果相同,“简单的”分类器往往优于“复杂的”分类器。
-
相比复杂的假设,我们更倾向于选择简单的、参数少的假设
4)最小描述长度原理(Minimum Description Length, MDL)
我们必须使模型的算法复杂度、以及与该模型相适应的训练数据的描述长度之和最小。也就是说,我 们应该选择尽可能简单的分类器或模型:赤池信息量准则,即 Akaike information criterion (AIC)、 贝叶斯信息准则,即 Bayesian information criterion (BIC)、网络信息准则,即 Network Information Criterion (NIC)。
更多模型选择内容:模型选择
3. 分类器集成
更多集成学习的内容:Blending and Bagging,AdaBoost
- 目标
将若干单个分类器集成起来,共同完成最终的分类任务,期望取得比单个分类器更好的性能。
- 有效条件
1)每个单一的学习器错误率都应当低于0.5(2分类,总之就是比随机猜测要好),否则集成的 结果反而会提高错误率。
2)进行集成学习的每个分类器还应当各不相同。如果每 个分类器分类结果相差不大,则集成后的分类器整体 和单个分类器做出的决策实际上没有什么差异,性能 得不到提高。
- 分类器集成的基本方法(本章作业题中的一道题)
1)按基本分类器类型是否相同

2)按训练数据处理方式
A. Bagging:
a. 训练一组基分类器,每个基分类器通过一个 bootstrap 训练样本集来训练。
b. 一个bootstrap训练样本集是通过有放回地随机从一个给 定的数据中抽样得到。
c. 获得所有基本分类器之后,bagging通过投票进行统计,被投票最多的类则确定为预测类。

B. Random Subspace:

C. Adaboost/boosting:具体可见第一部分(在分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行组合,提高分类性能。)
D. 随机森林。
