要求:
① 按照“类型”字段分类,筛选不同电影属于什么题材
② 整理数据,按照“题材”汇总,查看不同题材的烂片比例,并选取TOP20
③ 将得到的题材烂片比例TOP20制作散点图 → 横坐标为“题材”类型,纵坐标为烂片比例,点大小为样本数量
** 用bokeh制图
** 按照烂片比例做降序排列
提示:
① 删除“类型”字段空值的数据
② 由于一个电影“类型”会有多个,这里需要将一个电影每个“类型”都识别出来,在统计某个题材时都需要计算,例如:
如果一个电影的类型为:“喜剧/爱情”,则在计算“喜剧”、“爱情”题材的烂片比例时,都需要将该电影算上
③ 注意类型字段中,要删除空格字符
④ bokeh图设置点大小,这里通过开方减小数据差距 → size = count**0.5*系数

1 前期准备
import os
os.chdir(r'C:\Users\86177\Desktop')
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
from bokeh.models import ColumnDataSource,HoverTool
from bokeh.plotting import figure,show,output_file
导入相关的库和设置程序运行路径,并对部分警报信息进行忽视处理,设置图形在notebook内直接显示(%matplotlib inline)
2 筛选数据
这个目标是找出什么不同题材的烂片,数据就涉及到两列,一列是豆瓣评分,用来判断是否为烂片,这一步在上一篇文章中已经处理过了,生成的数据为data;还有一列就是电影类型,用来分辨是哪种题材。因此这里要在data数据上进行电影‘类型’这里类的缺失值处理,最终获得目标数据
2.1 查看电影‘类型’数据
data_load = pd.read_excel('moviedata.xlsx')
data = data_load[data_load['豆瓣评分'] >0]
data['类型']
–> 输出结果为:

根据提示可知,‘类型‘里面的内容字段包含了空格和/字符以及缺失值等内容
2.2 缺失值和符号处理
对于遍历循环来说,要处理大量数据之前可以先进行试错
data[data['类型'].isnull() == False]['类型'][0].strip().split(' / ')
–> 输出结果为: [‘剧情’, ‘儿童’]
typelst = [x for x in data[data['类型'].isnull() == False]['类型'].str.strip().str.split(' / ')]
typelst
–> 输出结果为:

直接使用列表推导式,没有办法将数据生成我想要的样子,因此还是要按照原来简单的方式进行操作,只能拆开分布运行了,下面的代码可以充分的展示.append()和.extend()方法之间的区别
typelst = []
for x in data[data['类型'].isnull() == False]['类型'].str.strip().str.split(' / '):
#typelst.append(x) 如果是append的话,那么这三条语句就相当于上面的一条语句
typelst.extend(x)#这里就体现出了append和expend的区别
typelst = list(set(typelst))
print('电影类型一共有{}种,分别为:\n\n{}'.format(len(typelst),typelst))
–> 输出结果为:
电影类型一共有35种,分别为:
[‘音乐’, ‘鬼怪’, ‘喜剧’, ‘运动’, ‘犯罪’, ‘动作’, ‘古装’, ‘短片’, ‘悬疑’, ‘冒险’, ‘戏曲’, ‘News’, ‘传记’, ‘恐怖’, ‘情色’, ‘舞台艺术’, ‘武侠’, ‘科幻’, ‘惊悚’, ‘历史’, ‘歌舞’, ‘脱口秀’, ‘灾难’, ‘剧情’, ‘黑色电影’, ‘家庭’, ‘儿童’, ‘同性’, ‘爱情’, ‘战争’, ‘奇幻’, ‘动画’, ‘真人秀’, ‘西部’, ‘纪录片’]
2.3(1)烂片中不同类型题材的电影数量和比例
这里注意一下(1)的标题和(2)的标题的不同,关于烂片的数据,上一篇文章已经完成了data_lp,这里就不再写入代码了,直接查看data_lp的数据内容
data_lp
–> 输出结果为:

2.2获取的是全部电影的所有类型,但是对于data_lp来说,上一篇文章中只进行了烂片情况的判断,并没有进行烂片中电影类型缺失值的处理,因此要确定烂片中的数据类型,要先处理一下data_lp里面的缺失值,代码和上面的操作类似
data_lp['类型'].isna().sum()
#发现一共存在31个缺失值,那么处理后的数据应该就是515
–> 输出结果为:31
data_lp = data_lp[data_lp['类型'].notnull()].set_index(np.arange(515))
data_lp
–> 输出结果为:

数据筛选完成后,按照三步进行烂片top20的数据输出,这里封装三个函数lp_one_info()、lp_info()、lp_top_20()
def lp_one_info(data,type_i):
dic = {}
dic['lp_name'] = type_i
dic['lp_num'] = len(data[data['类型'].str.contains(type_i)])
dic['lp_rate'] ='{:.2f}%'.format(len(data[data['类型'].str.contains(type_i)])/len(data)*100)
return dic
lp_one_info()函数是为了实现lp_info()的功能而创建的,也是在试错的前提下对一个数据进行的试验,type_i就是typelst里面的某一个数据,具体举例如下
lp_one_info(data_lp,typelst[0])
–> 输出结果为: {‘lp_name’: ‘真人秀’, ‘lp_num’: 0, ‘lp_rate’: ‘0.00%’}
def lp_info(data,ls):
lp_ls = []
for type_i in ls:
lp_ls.append(lp_one_info(data_lp, type_i))
return(lp_ls)
lp_info()函数的功能就是对于typelst里面的每条数据进行逐条输出并保存在列表里面,运行结果如下
lp_info(data_lp,typelst)
–> 输出结果为:

def lp_top_20(lp_ls):
df_lp= pd.DataFrame(lp_ls)
df_lp.sort_values(by='lp_num',inplace = True,ascending = False)
df_lp_20 = df_lp[:20].set_index(np.arange(1,21))
return df_lp_20
lp_top_20()函数的功能是直接返回烂片数据类型的前20,运行代码如下
lp_top_20(lp_info(data_lp,typelst))
–> 输出结果为:
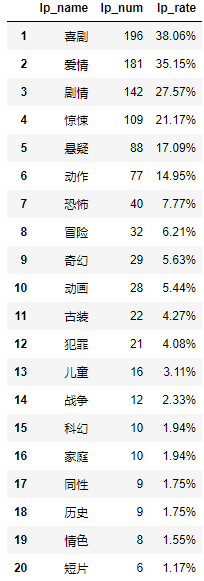
2.3(2)不同类型电影题材的烂片数量及比例
仔细思考一下,那种题材电影容易出烂片,可以得出这个结论的前提就是:各种题材的烂片在全部数据data之间的占比的大小,占比越多越是倾向烂片,而不是与局部样本data_lp中对比,因此只要对函数lp_one_info()进行部分代码修改即可,这也是封装函数的便捷性,最后把第三个函数进行了拆分,后面的操作还会使用,觉得还是不封装三个函数比较方便
def lp_one_info(data,type_i):
dic = {}
data_i = data[data['类型'].str.contains(type_i)]
data_lp = data_i[data_i['豆瓣评分'] < 4.3]
dic['lp_name'] = type_i
dic['lp_num'] = len(data_lp)
dic['type_num'] = len(data_i)
#dic['lp_rate'] ='{:.2f}'.format(len(data_lp)/len(data_i)) 这就是最后bokeh制图时候不出图的原因,不可以进行格式化
dic['lp_rate'] =len(data_lp)/len(data_i)
return dic
def lp_top_20(data,ls):
lp_ls = []
for type_i in ls:
lp_ls.append(lp_one_info(data, type_i))
return lp_ls
df_lp= pd.DataFrame(lp_top_20(data,typelst))
df_lp.sort_values(by='lp_rate',inplace = True,ascending = False)
df_lp_20 = df_lp[:20].set_index(np.arange(1,21))
df_lp_20
#对于最终生成DataFrame的数据,尽量不用函数
–> 输出结果为:
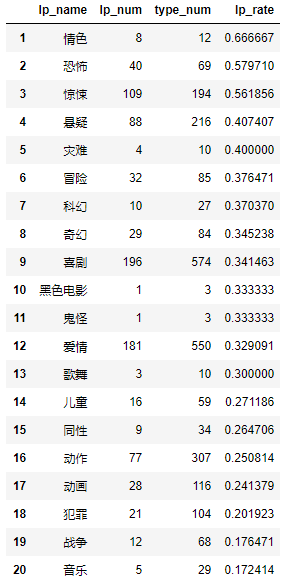
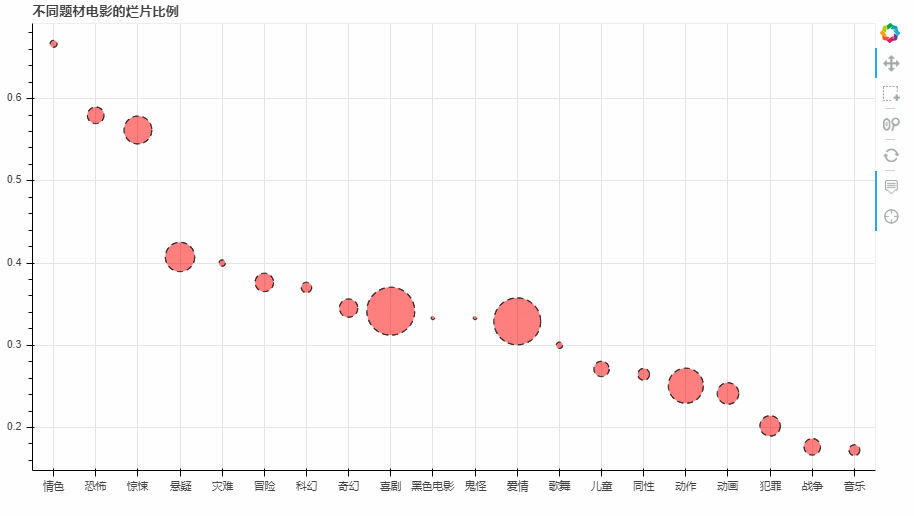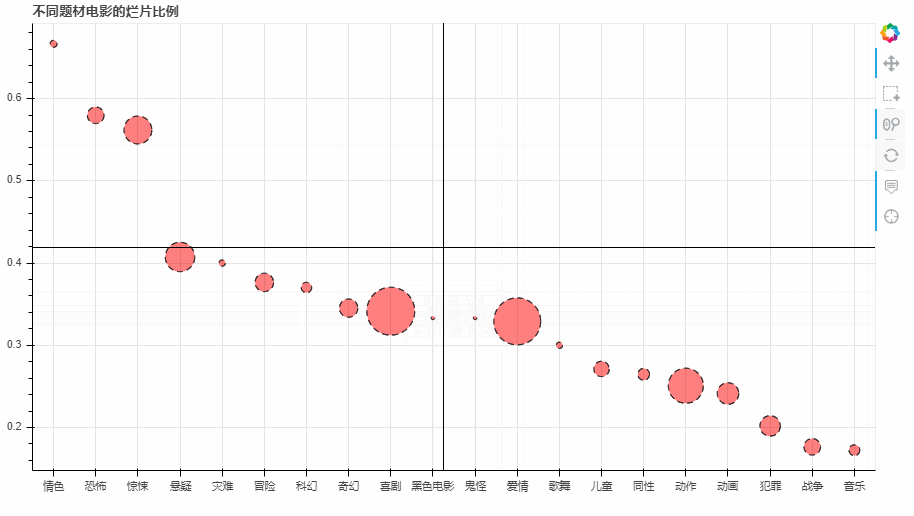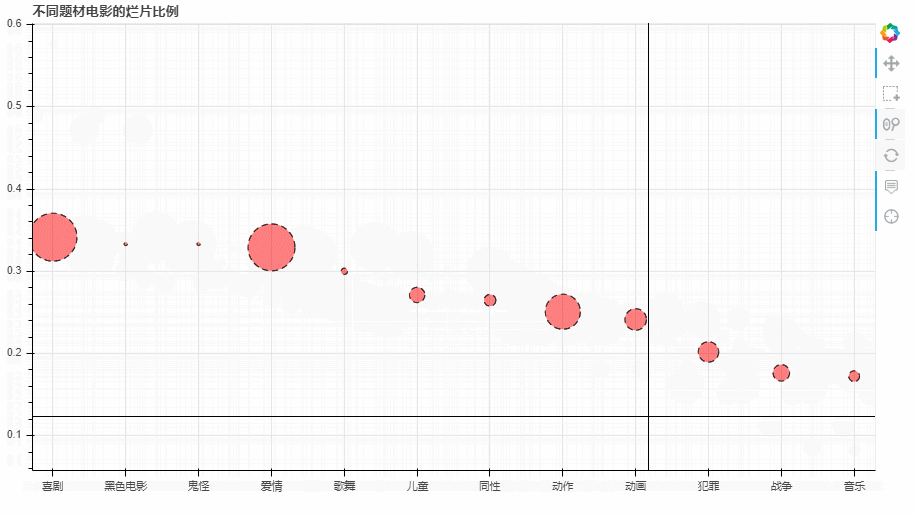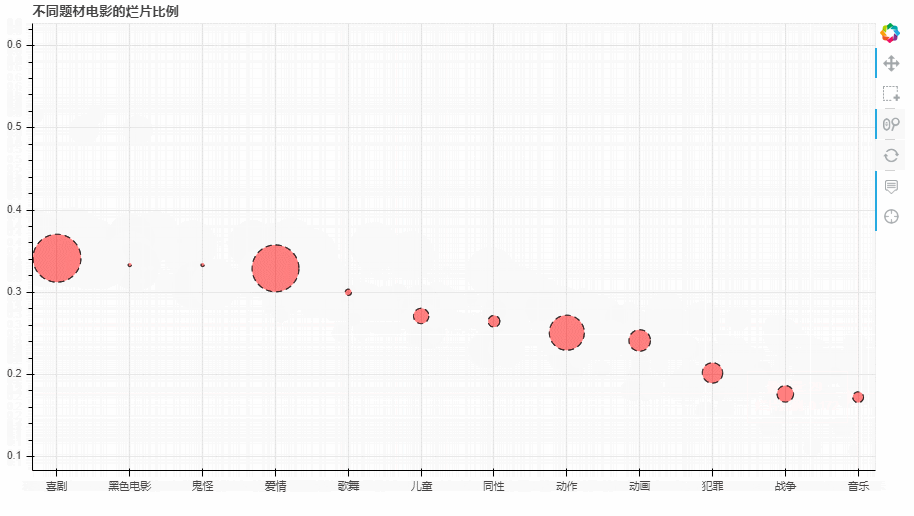
4 Bokeh制图
df_lp_20["size"] = df_lp_20['type_num']**0.5*2
#设置点的大小
source = ColumnDataSource(df_lp_20)
ls_type = df_lp_20['lp_name'].tolist()
hover = HoverTool(tooltips = [("数据量","@type_num"),
("烂片比例","@lp_rate")])
output_file("1.html")
p = figure(x_range = ls_type, plot_width = 900, plot_height = 500, title = "不同题材电影的烂片比例",
tools = [hover, 'reset, xwheel_zoom, pan, crosshair, box_select'])
p.circle(x = 'lp_name', y ="lp_rate",source = source, size = "size", line_color = "black",
line_dash = [6,4], fill_color = "red",fill_alpha = 0.5)
show(p)
#为什么当y='lp_rate'一直输出空白,然而当y=lp_num或者y=type_num时都有图形输出,调试了半天,最终的结果在def lp_one_info()函数里面,lp_rate的结果
#不能格式化输出,否则无法识别
–> 输出结果为: