聚类算法之K-Means算法原理及实现
1. 聚类和相似度
1.1 聚类
将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。
由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。
1.2 相似度
计算向量之间的相似度的常用方法:
设有P1(x1,y1),P2(x2,y2)
-
欧氏距离:空间中两点的直线距离。
-
曼哈顿距离:又称“城市街区距离”。
-
余弦距离:
余弦相似度用向量空间中的两个向量夹角的余弦值作为衡量两个样本差异的大小。
余弦值越接近 1 ,说明两个向量夹角越接近 0 度,表明两个向量越相似。
Tips:对于特征向量中含有的不同量级的数据应先将数据归一化。
2. K-Means算法原理
K-Means算法是聚类算法中最经典的算法。其中K代表划分的簇的数目,而Means则是算法的核心概念—质心(聚类中心)。
2.1 K-means算法思想
给定的样本集,事先确定聚类簇数K,让簇内的样本尽可能紧密分布在一起,使簇的距离尽可能大。
该算法试图使集群数据分为n组独立数据样本,使n组集群间的方差相等,数学描述为最小化惯性或集群内的平方和。
2.1 K-Means步骤及流程
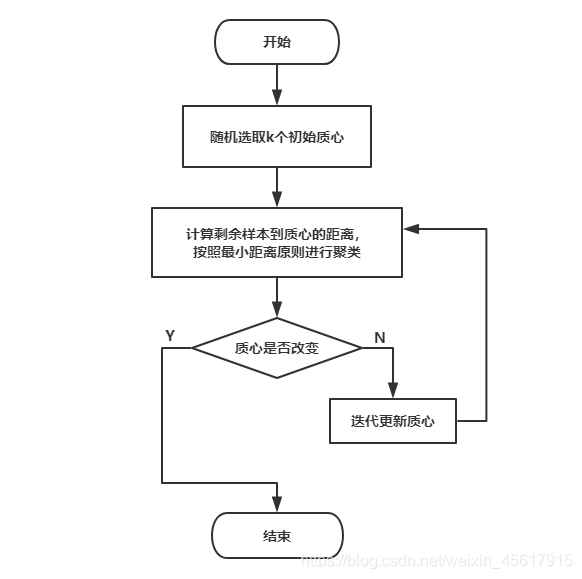
1.K-Means算法步骤
输入:数据集X,簇值K
输出:K个簇划分
算法步骤:
① 在数据集中随机为K个聚类选择初始质心
② 将数据集按照最小距离原则进行聚类
③ 使用K个聚类的样本均值迭代更新质心
④ 复步骤②,③,直到质心稳定不再发生变化
⑤ 输出最终的质心和K个聚类划分
2.K-Means算法流程图
2. K-Means算法实现
2.1 准备数据
随机创建300个二维数据作为训练集。
数据集的标准差设为0.3使其生成一个符合高斯分布的数据集。
import matplotlib.pyplot as plt //导入matplotlib.pyplot 实现数据可视化
from sklearn.datasets.samples_generator import make_blobs // make_blobsmake_blobs函数是为聚类产生数据集
X, y = make_blobs( n_samples=300, //数据样本点个数
n_features=2, //数据的维度
centers=[[-1,-1],[0,0],[1,1]], //产生数据的中心点
cluster_std=[0.3,0.3,0.3] //数据集的标准差
)
X是存储了300个二维数据的二维数组。

y存储样本数据所属簇的标签。
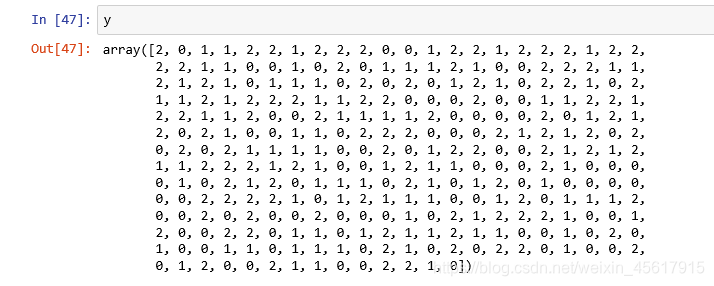
2.2 测试数据
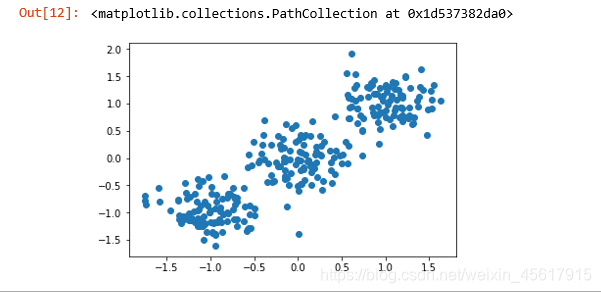
2.2.1 将数据集绘制成散点图
使用 plt.scatter( ) 方法绘制数据集的散点图,X[:,0]表示选取X中第一列的数据,即x坐标,X[:,1]表示选取X中第二列的数据,即y坐标。
plt.scatter(X[:,0],X[:,1],marker='o')
散点图如下:
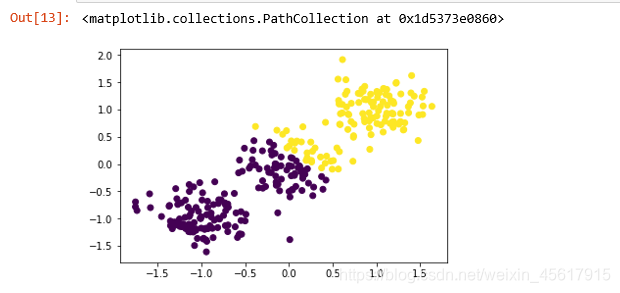
2.2.2 K=2时K-Means聚类结果
导入sklearn.cluster中的KMeans函数。
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=2).fit_predict(X)//对X中的数据进行聚类方法并指定n_cluster为2
plt.scatter(X[:,0], X[:,1], c=y_pred)//c=y_pred表示散点图的颜色按照y_pred的标签绘制
K-Means聚类结果:
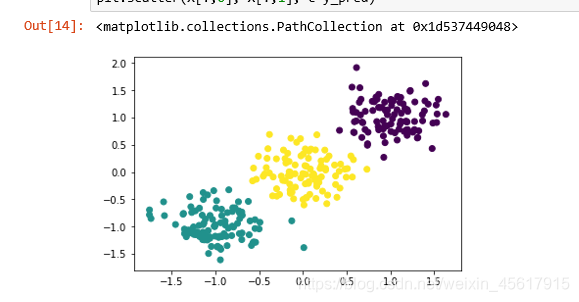
2.2.2 K=3时K-Means聚类结果
y_pred = KMeans(n_clusters=3).fit_predict(X)//对X中的数据进行聚类方法并指定n_cluster为2
plt.scatter(X[:,0], X[:,1], c=y_pred)//c=y_pred表示散点图的颜色按照y_pred的标签绘制
K-Means聚类结果:
2.2.3 K=4时K-Means聚类结果
y_pred = KMeans(n_clusters=4).fit_predict(X)//对X中的数据进行聚类方法并指定n_cluster为2
plt.scatter(X[:,0], X[:,1], c=y_pred)//c=y_pred表示散点图的颜色按照y_pred的标签绘制
K-Means聚类结果:
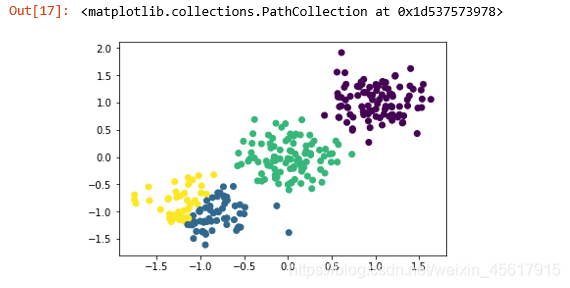
由k=2,3,4的K-Means聚类结果可以明显看到k=3时聚类结果最好。
3.K-Means算法的优缺点
- 聚类高斯分布的效果较优。
- K-Means是一种无监督学习,在一些特殊情况无法评判其好坏。
- 依赖于初始质心,容易陷入局部最优。
- 对于圆环形聚类,聚类结果较差,无法将每一个圆环聚类为同一个簇。
