前言
个人认为,大部分的数据结构都是基于链表(二叉树这种也算一种链式结构,其节点会保存了左右节点的指针)与数组组成的,所以链表与数组是数据结构中的一个基石,在上一篇数据结构分析 文章中我结合了查找这一场景,突出了数组与链表的特点,讲解了几个数组、链表变形的、用于查找的数据结构,理解上篇文章,我认为对数组和链表的理解可以更上一层楼
上一篇的 关于查找常用的几个数据结构 文章的主要议题是关于查找的几个数据结构的优劣和对比各自的场景,分析各数据结构与算法之间的碰撞都会产生如何巧妙的化学反应,但是并没有细致去讲解数据结构,如果将讲解数据结构的解析文章杂糅在一起,个人觉得有点不能专注于一个议题中的味道。所以这篇将跳表这一数据结构单独拎出来讲解。不过本篇文章不会侧重于代码上的跳表实现,本篇的议题如下:
- 跳表是什么?
- 跳表快在哪里?为什么Redis要用跳表实现有序集合
跳表
二分查找与数组的劣势
上篇文章中我们讲到了在查找数据时,如果既要查询快,又要可以查询一个范围(也就相当于有序地存储),那么可以使用二分算法,但是二分算法有一个劣势在于底层的数据结构是数组,在我不断增删数据的时候难免要从数组中间地方进行操作,这样就会造成增删操作的时候数组数据要进行拷贝才可以完成操作
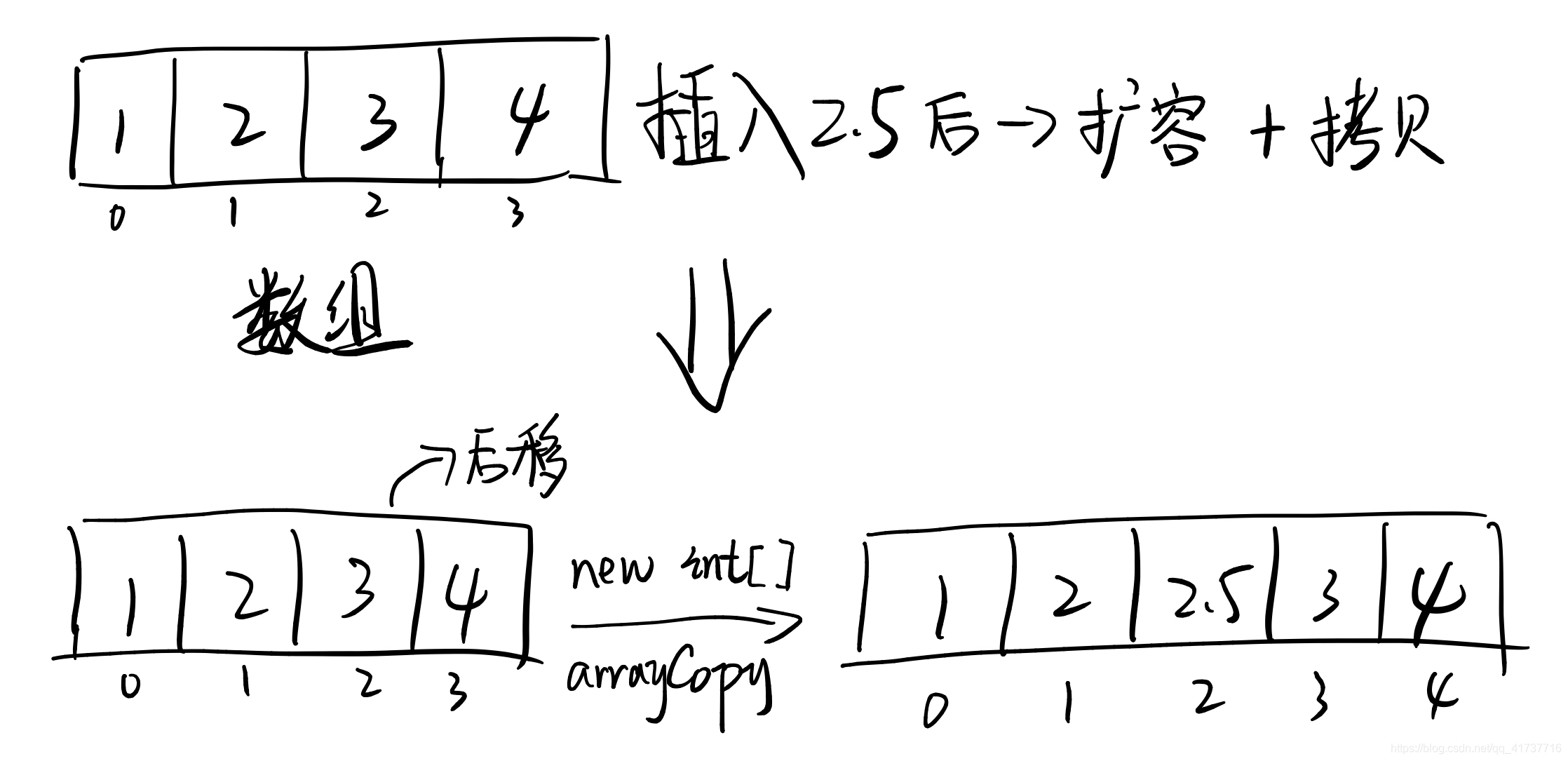
在数据量小的情况下数组表现的会比较优秀,毕竟数组对CPU缓存相当友好。如果数据量大,如果往中间插入或者删除数据,将会导致数组中有一半的数据都会拷贝,只为了后移能在中间插入一个数据,或者是空间不够存放,就要做一个新数组存放数据,开辟一段连续的内存空间,如果数据量大,开辟大的连续内存空间的开销是相当大的。
使用链表实现
那么如果我们使用链表去实现二分查找,是不是就没有频繁开辟连续大内存和拷贝数据的开销呢?
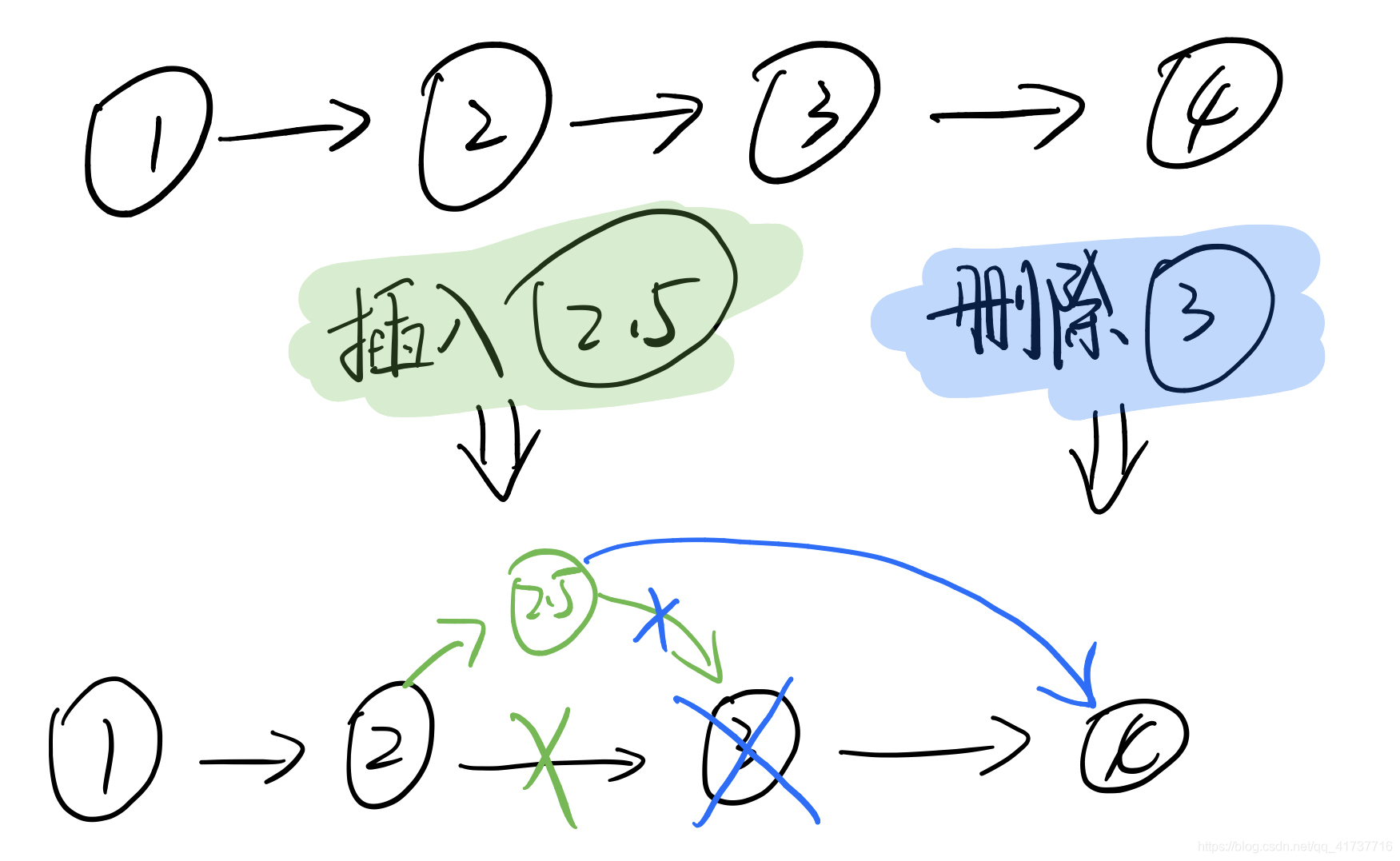
是的,只需要断开和连接指针即可。那么我们如何将其融入二分查找的算法思想呢?我们知道,二分查找之所以快,是因为查找一次就可以砍掉一半的数据,就像我们猜数字,1-100,猜50,如果答案比50大,只需要查找51-100,1-49这部分的数据就被我们砍掉了。但是链表有个缺点就是不支持随机访问,我们访问数组中中间的地方只需要O(1)的复杂度,因为其内存地址我们已经知道了(数组地址加上下标就是我们需要拿的元素的内存地址(假设元素字节大小为1)),如果是链表,访问中间部分的数据要一个个遍历节点,在上面的例子中我们需要数50个节点我们才知道中间的那个Node在哪里,那如果我们将中间的那个Node直接提取出来呢?
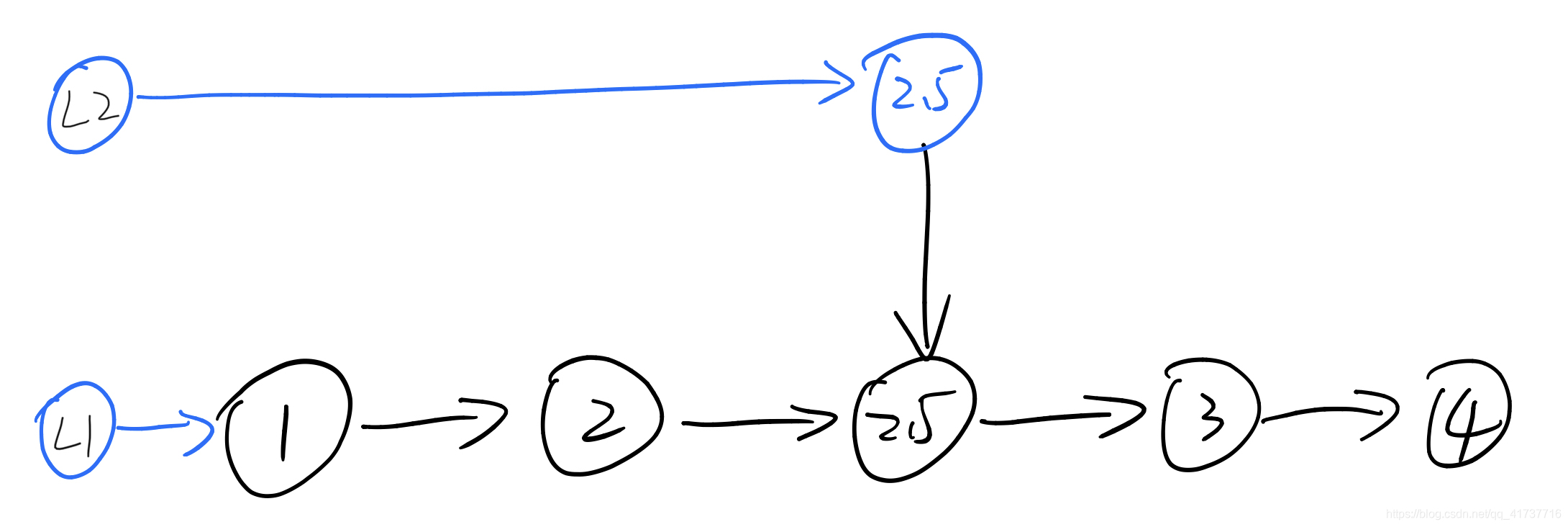
我们将中间的那个节点提取出一层(Level),此时他在Level2这一层链表中,此时如果我们需要寻找大于等于3的那些数据,我们第一步做的是找到最高的那一层(L2),找到了2.5这个节点,发现要找的数据在2.5后面,而后面又没有数据了,此时降级,往后面查找,到了L1,看到自己后面是3,返回3后面的所有数据,结束。这样是不是就有了二分查找的几分味道呢?可能数据量小不太能看出来,让我们增加一些数据,然后多加几层Level看看
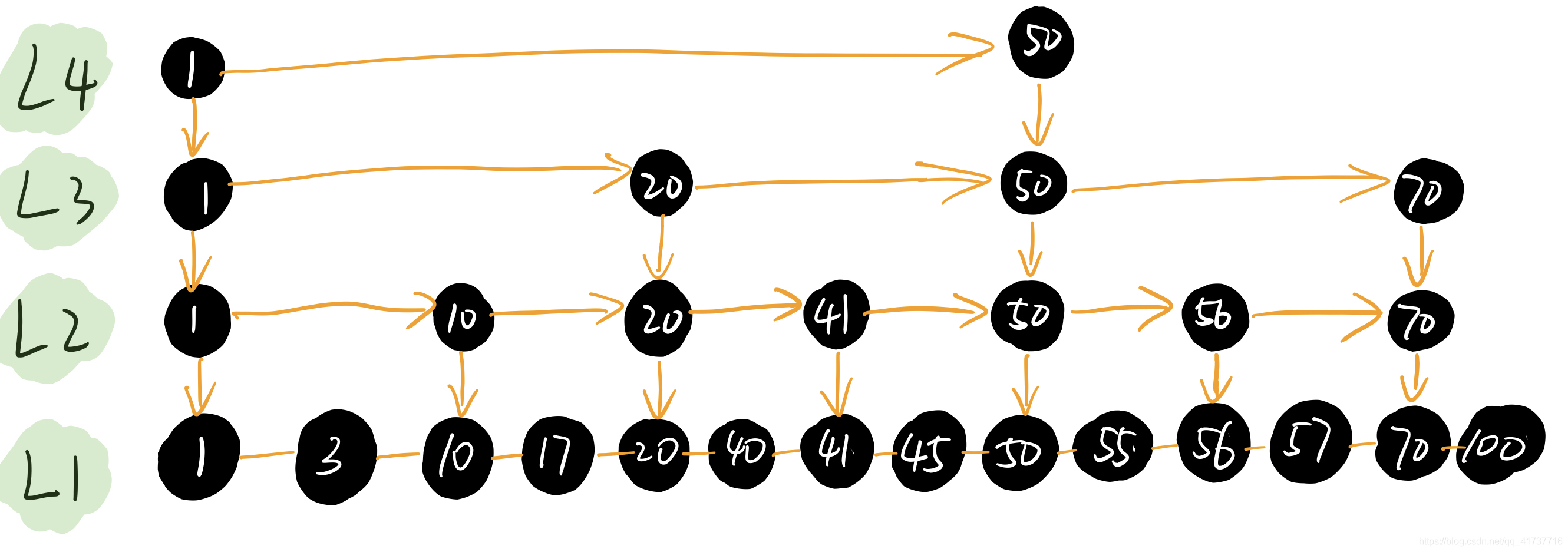
这次我们整4层,且每两个节点做一个提取,现在我想查找大于57且小于80的数据,如何查找?
首先我们需要找到大于等于57的数据,且前面一个节点小于57,这个数据就是我们要找的57-80的起点节点,而终点数据就是小于等于80且后面一个节点大于80的节点:
- 找最高层L4,找到1后发现要找的数据至少大于57,所以数据还在1后面,此时找到节点50,则降级往后查找
- 到L3,发现后面是70,说明数据至少就在这两个节点之间,继续降级
- 到L2,发现后面是56,说明数据就在56和后面一个70节点之间,指针移动到56节点,继续往下
- 到L1,发现是最后一级,则数据在此层就可以拿到,56往后即为57,满足第一个大于等于57且前面一个节点小于57的条件,则57就是起点节点,往后遍历到70,发现后面是100,大于80了,则70是终点节点
此时我们遍历了几次呢?
1 -> 50 -> 50-> 50 -> 56 -> 56 -> 57 -> 70
只需要7次的节点遍历即可找出数据
如果我们不使用跳表,单纯一个链表遍历需要遍历几次呢?从头节点1开始遍历到57,需要遍历12次才能拿到答案,在数据量比较小的情况下可能你还是不能很直观的感受到,我们先来看看跳表到底为什么可以只遍历7次就能拿到结果数据:
可以看到,我们第一次就直接从最高一级开始出发,这样的操作会直接pass掉1-50前面的所有节点,直接砍掉一半的节点,继续往下层遍历,虽然后面只砍掉了一个节点,但是如果在数据量大的情况下,每下一层都会砍掉很多数据,也就是说,我们的遍历次数其实是跟这个Level层数有关系的,如果我们继续每两个提升一个节点到上一层,在上面的例子中14个节点需要log14(2为底)约等于4层,那如果是64个数据,其实只需要6层,65536个数据,只需要16层,100W+个数据只需要20层,可以看到,log级别在大数据量下的表现十分惊人,而层数大致可以看作是遍历次数,为什么呢?
查找的时间复杂度
例如我们现在想找17这个节点,首先到了L4的1节点,17肯定在1-50节点范围内,而下一层L3的1-50节点由于我们是每两个节点提升一次,那么L4中1-50的节点对应在L3中最多只有3个,所以我们最多遍历两次就可以找到我们要往下的那个节点。来看看例子:
- 第一次遍历:此时L4的50节点直接往下到L3,遍历第一次到L3的20这个节点
- 第二次遍历:然后看看20前面的节点(遍历操作)是1,1比17大,而20比17小,我们选择在20这个节点开始往下
- 第三次遍历:往下到了L2的20节点
从上面的操作我们可以看出,其每下一层都需要最多3次(可能只需要一次,这与数据和几个节点提升一次层数有关),在上面的例子中如果有5层,我们也就需要平均3*5=15次的遍历即可找到数据,那么层数又是怎么算呢,其实层数与几个节点提升一次有关系,在上面的例子中,我们每两个节点提升一次层数,也就是说每提升一层总数量除以2,一直除一直除直到最后顶层只有2个数据,这不就是以2为底计算 logN 的过程吗?也就是说,层数乘3即为时间复杂度,3为常量直接忽略,则此时可以知道,其时间复杂度为 O(logN)
大数据量下的查找
我们在100万+数据中找到某个范围,也只需要找O(logN)级别的节点就可以找到,随便估计一下(很随便但比较直观)也只需要20-50多次的遍历,如果纯遍历,找中间范围的某个数据,你需要遍历至少50万个节点…
跳表的增删操作
又由于其链表结构,使得增删数据只需要断开与重建指针即可,所以增删数据其实瓶颈在查找数据的时间复杂度上,查找到数据之后增删节点那都是一瞬间的事情(其实Redis在跳表结构上与哈希表结合,将查找数据的复杂度直接将为O(1),所以Redis中有序集合删一个已知的节点的时间复杂度可以视为常量级别,如果范围删或者是插入还是需要O(logN) 的时间复杂度的。这个思想在我上一篇文章中就有讲到)
但是有一个问题,如果删除的节点都是提升为高层的节点怎么办?
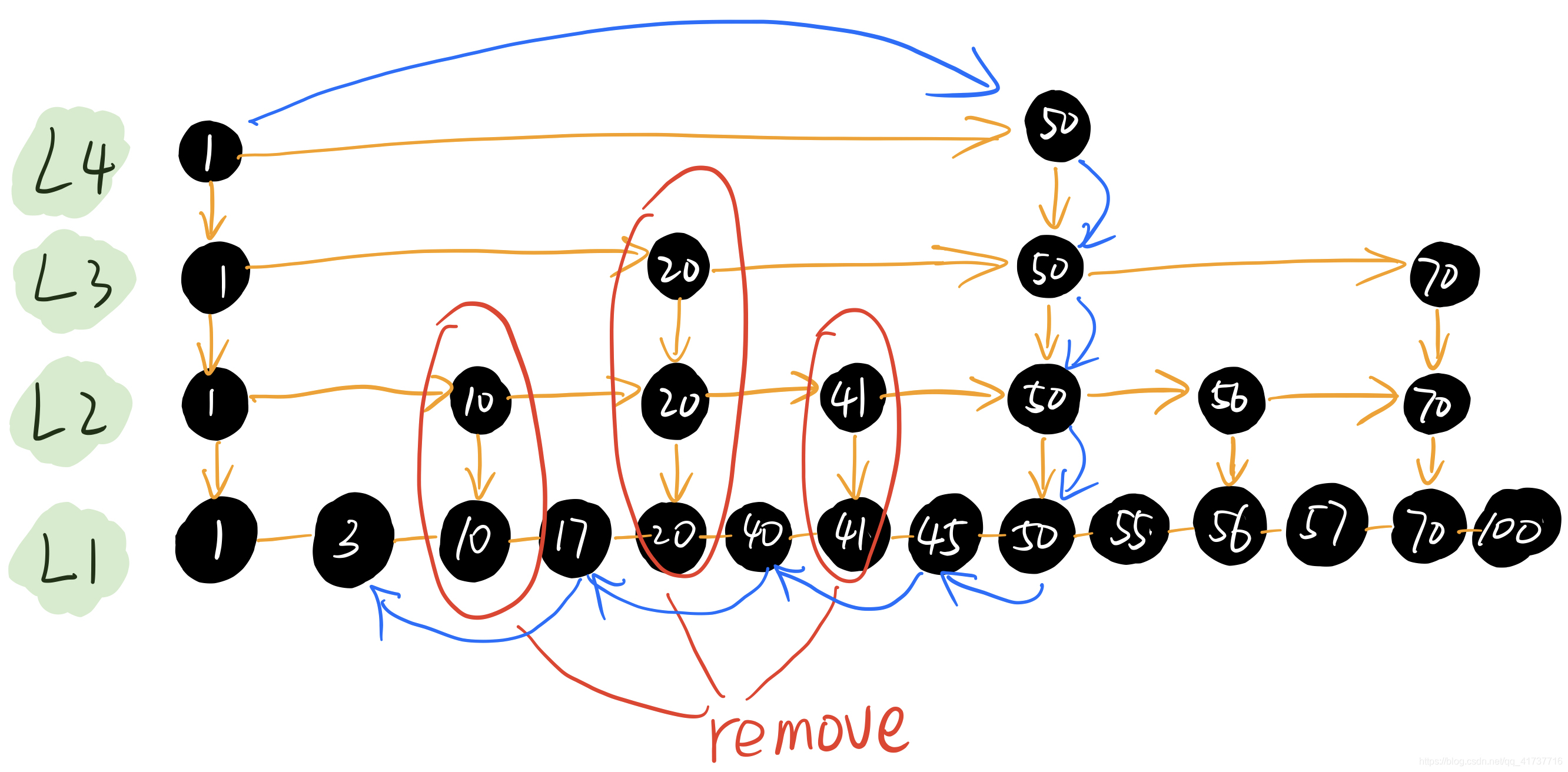
可以看到,如果我们将10、20、41这三个有提升的节点全删了,我们要找3这个节点,将直接退化为链表的时间复杂度,为了避免这种情况,我们需要动态的去调整哪些节点会提升为高层,具体提升为几层(L4还是L3还是L2)
Redis中的有序集合
- 动态调整层数
在Redis中,其动态调整的策略即为随机策略,首先插入元素时会有一个几率,被提升,我们做一个假设:
- 插入数据A,找到A要插入的位置后,调用随机函数,有30%的概率其会被提升到L2
- 运气很好,A被提升为L2,继续调用随机函数,有10%的概率会被提升为L3
- 这次运气不太好,所以A这个数据就只被提升最高为L2
在Redis中好像一共有64层还是32层,有点忘记了,越往上层几率越小,这样的话,想要达到顶层64层,需要的数据量可就不少了。这样一来,是同样可以达到我们上述的每两个节点提升一层的效果的,读者可以在自己脑中推演一遍。
但是这个随机函数的概率值是一个动态值,在上面删除节点例子中,如果删掉了L2、L3代表节点,那么这个提升的随机概率将会稍微升高一些,比如提升L2的概率会从30%提升为33%,这样会让多一些节点补充刚刚删掉的L2,等L2节点上来了,这个概率又会从33%下降为30%,达到了动态调整Level层数的效果。即使删除了很多高层节点,也不会退化为链表。
- 与Hash表结合
这个思想是我一直反复提及的,hash的优点在于查找一个给定值是O(1)的时间复杂度,但是不能范围查询,其正好和跳表补缺补漏,可谓如虎添翼
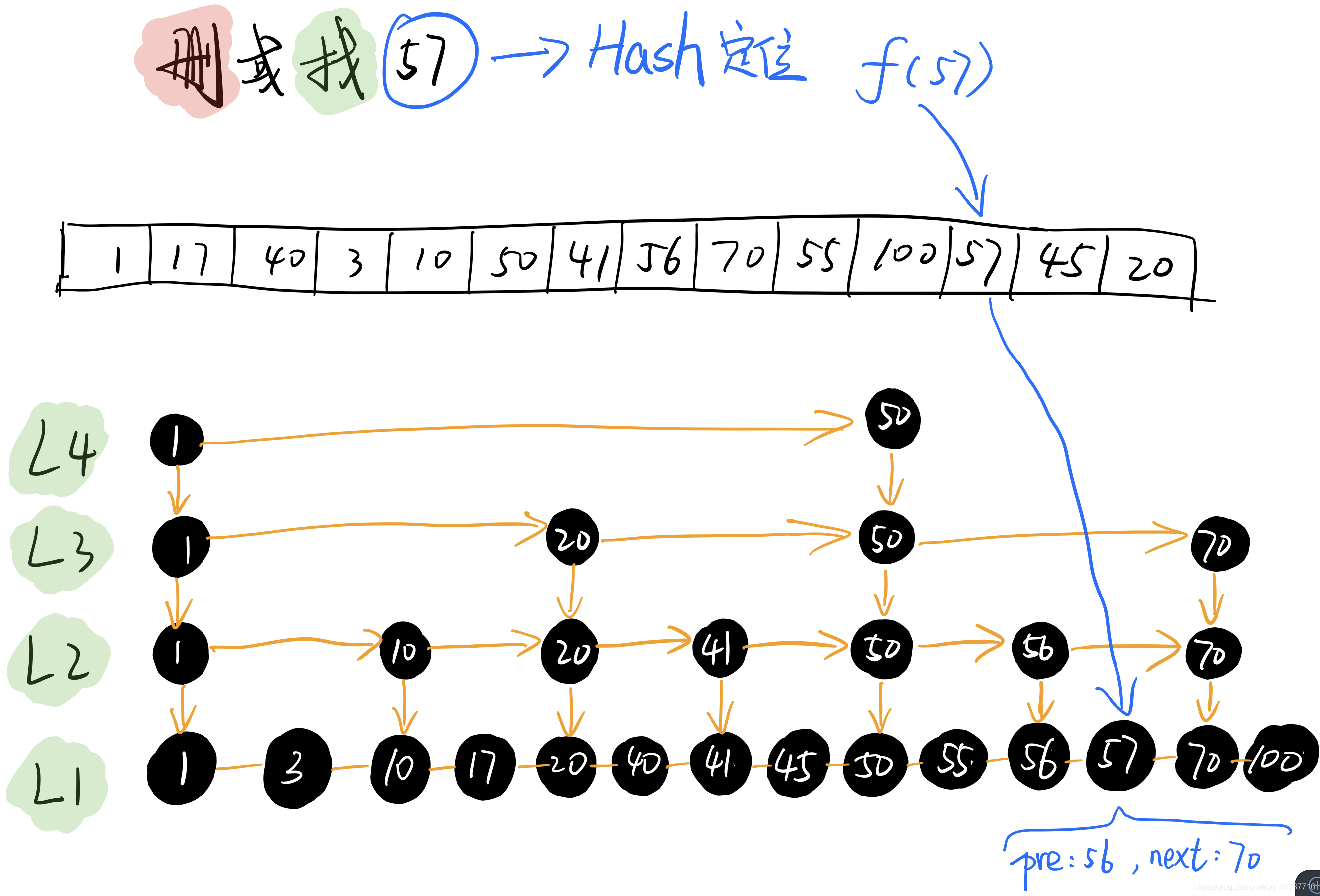
只需要HashMap中找一下,就可以找到57这个节点,而Node57中有一个前驱节点和后继节点,我们此时只需要将前驱节点56的next指针指向70,70这个后继节点的pre指针指向56就完成了删除操作。
单纯的查找57这个值也是只需要一个哈希即可完成,在Redis中的有序集合就是这么实现的(Redis中C语言实现的SortedSet的struct定义里面就是一个HashMap和一个SkipList)
- 为什么不用红黑树
- 在Redis中查找一个范围数据(56-70)这个需求是一定要有的,而红黑树做范围查找的话没有跳表效率高,但也不是说平衡树做不了范围查找,就像MySQL中的B+Tree,其树节点就像跳表这样有重复的节点,最底部的叶子节点会保存全部数据的链表形式,这样就可以支持范围查找了,这也就是MySQL为什么要用B+Tree作为索引的原因
- 相对来说,实现一个跳表(虽然也有一点小难度)比实现一个红黑树(甚至是平衡树)要简单很多,效率两者来说都是一样的,那么Redis的作者为何要吃力不讨好选择平衡树来实现呢?跳表的动态平衡策略可是比红黑树简单很多的
