Redis系列-7.有序集合(zset)结构
文章中可能有地方描述偏差,欢迎留言指证
1.基本
大体结构和前面讲的集合差不多,只是在排序上增加了分数。redis用的是score,和权重不一样,我认为分数更好。分多的在前面,分少的在后面,可以灵活的控制排序。需要注意的时,这里分数只能是数值类型,int float double 都行,和C里值数值类型一样(redis就是用C写的),用ABC这样去当分数是不行的。分数也是可以用负数的
2.集合内
下面所有描述里 {}都是必需参数,<>是可选参数
设置值
zadd {key} {score} {member} [score member...]
第一个参数是键名
第二个参数是分数
第三个参数是值在添加值的同时就会添加分数。返回值是添加成功的个数。
在redis3.2之后添加了nx一类的命令,用法和字符串中讲到的一样。windows版最新版也支持了。
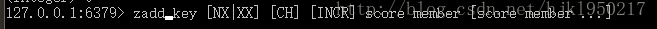
incr命令是自增,还有自减等,用法和前面一样。但是个人建议用后面讲到的增加固定分数来设计,作用是一样的,还方便修改。
增加某一个成员的分数
zincrby {key} {increment} {member}
key:键名
increment:要增加的分数
member:成员此命令会返回操作后成员的分数。
如果要减分的话也是可以的
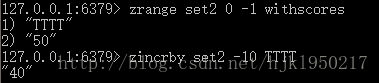
按排名范围获取成员
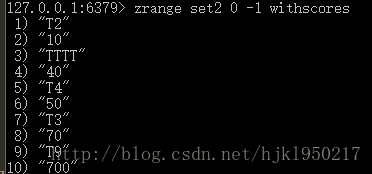
zrange {key} {start} {end} < withscores>//从低到高返回
zrevrange {key} {start} {end} < withscores>//从高到低返回获取命令是按范围返回的,但是可以用0 -1来遍历。。withscores加上后会同时返回分数
按分数范围获取成员
zrangebyscore {key} {min} {max} < withscores> < limit offset count>//从低到高返回
zrevrangebyscore {key} {max} {min} < withscores> < limit offset count>//从高到低返回先看看所有测试数据:
获取命令是按范围返回的,但是可以用0 -1来遍历。。withscores加上后会同时返回分数,limit后面是起始位置和要获取的个数

但是limit是在结果集中取,不是从有序集合中第一个取:
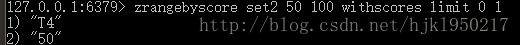
同时min max还支持区间,开区间是小括号( 。 闭区间就直接写就行,不用加符号。 -inf可以代替无限小,+inf可以代替无限大。

如果min和max写错,会提示区间不是浮点数。原因是因为参数识别不了
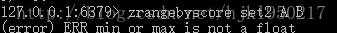
计算成员个数
zcard {key} 计算有序集合的个数,和前面的一样,时间复杂度也为O(1)
计算分数范围内的成员个数
zcount {key} {min} {max}和上面不同的是,这个会遍历数据。也许范围内只有5个,但命令会遍历整个集合。
计算某一个成员的分数
zscore {key} {member}如果成员不存在,会返回nil。
计算分数其实就是读取数据,时间复杂度是O(1),但是在提前知道成员的名字。所以需要在其他地方保存成员。个人认为有序集合适合排序,但不适合保存信息,这些在后面会专门有一篇博客来说这些。
计算某一个成员的排名
zrank {key} {member}//按分数从低到高
zreverank {key} {member}//按分数从高到低此命令会返回排名 是int类型的。
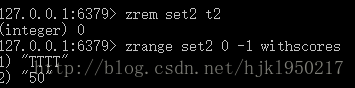
删除成员
zrem {key} {member} < member...>和前面的删除命令一样的用法。。成功返回int类型的1,失败或成员不存在会返回0;
删除升序排名内的元素
zremrangebyrank {key} {start} {end}返回结果是删除的个数
注意命令是按升序删除排名范围内的元素!如果想是降序删除的话,用-数。。-1是分数最高的,-2是倒数第二的,依次类推。
删除分数范围内的元素
zremrangebyscore {key} {min} {max}分数是可以为负的,所以不存在升序还是降序了。min和max也可以用区间。 开区间是小括号( 。 闭区间就直接写就行,不用加符号。 -inf可以代替无限小,+inf可以代替无限大。
3.集合间的操作
这些集合间的操作和数学中的集合一样的。。差集 并集 交集等等
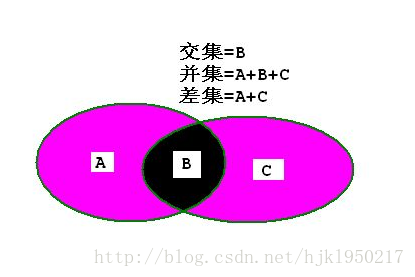
在有序集合中,因为计算量比较大,所以计算命令都是存储系列的命令。
求多个集合的交集
zinterstore
{TargetKey}
{num}
{key} < key...>
< weights weight <weight....> >
< aggregate sum|min|max>
TargetKey:要保持结果的键,也是有序集合。如果已经存在,则会覆盖
num:要计算的键的个数
key:要计算的键名,有多少就写多少
weights:每个键的权重,计算时数据的分数会乘以对应的值,默认是1.写的顺序和key的顺序要一对应
aggregate:可以对结果集的分数做汇总,默认是sum求和,min是最小值,max是最大值。注意:是针对每一项。比如做交集,默认sum,权重为2的话。那选出结果后,分数就是新值=(原值1+原值2)*2
和做交集一致,只是做了并集计算。判断的依据还是元素名
求多个集合的并集
zunionstore
{TargetKey}
{num}
{key} < key...>
< weights weight <weight....> >
< aggregate sum|min|max>
TargetKey:要保持结果的键,也是有序集合。如果已经存在,则会覆盖
num:要计算的键的个数
key:要计算的键名,有多少就写多少
weights:每个键的权重,计算时数据的分数会乘以对应的值,默认是1.写的顺序和key的顺序要一对应
aggregate:可以对结果集的分数做汇总,默认是sum求和,min是最小值,max是最大值。注意:是针对每一项。比如做交集,默认sum,权重为2的话。那选出结果后,分数就是新值=(原值1+原值2)*2
命令也是一样,返回结果。。并集什么意思就不用讲了呗
4.内部编码
有两种:
ziplist:压缩列表,当有序集合的元素小于zset-max-ziplist-entries配置时(默认128个),且每一个元素的值都小于zset-max-ziplist-value的配置时(默认是64字节),redis会选中这个类型,有效减少内存的使用
skiplist:跳跃表,当集合不满足ziplist条件时,使用这个类型。因为此时ziplist的读写效率会下降。
5.适合场景
1.用户赞数
有序集合数据中只存分数和元素名,而且可以很方便的获取分数或元素员。这在用户的赞,视频播放量中使用就非常好。。视频网站中经常有热播剧,那用这个结构就可以很方便的实现。合理的设计一下,类似优酷网上的播放量和排名,一个节点就可以完成了。当然,实际中因数据量大小,网络有等原因,优酷网可能不会这么简单的设计。
2.做排名
比如美国选举这样的需求,每一个选民投票后,分数+1.这样不用做任何额外的逻辑,就可以获得前3名