Java中的集合类包含的内容很多而且很重要,很多数据的存储和处理(排序,去重,筛选等)都需要通过集合类来完成。
首先java中集合类主要有两大分支:
(1)Collection (2)Map
先看它们的类图:
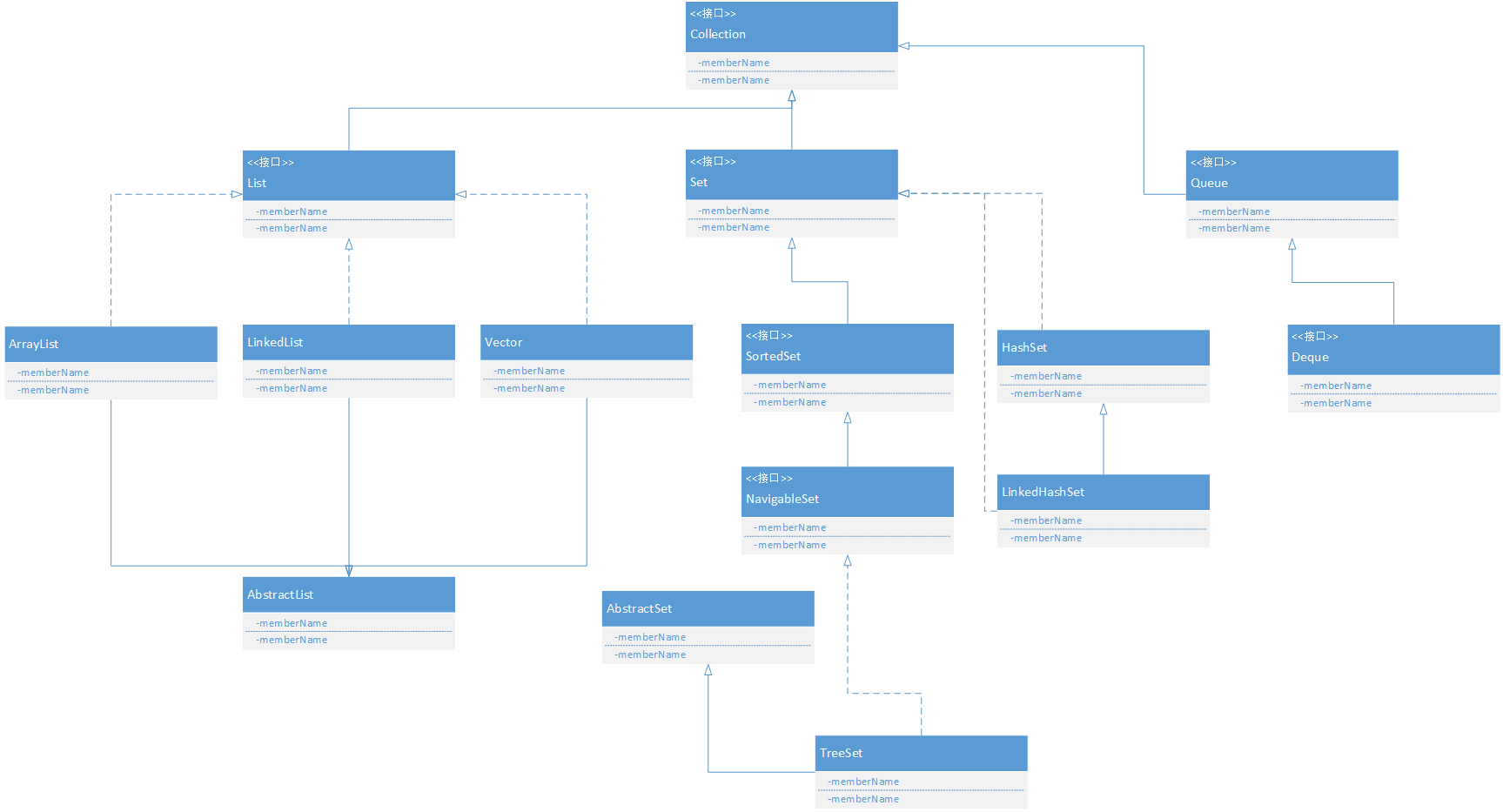
(1)Collection
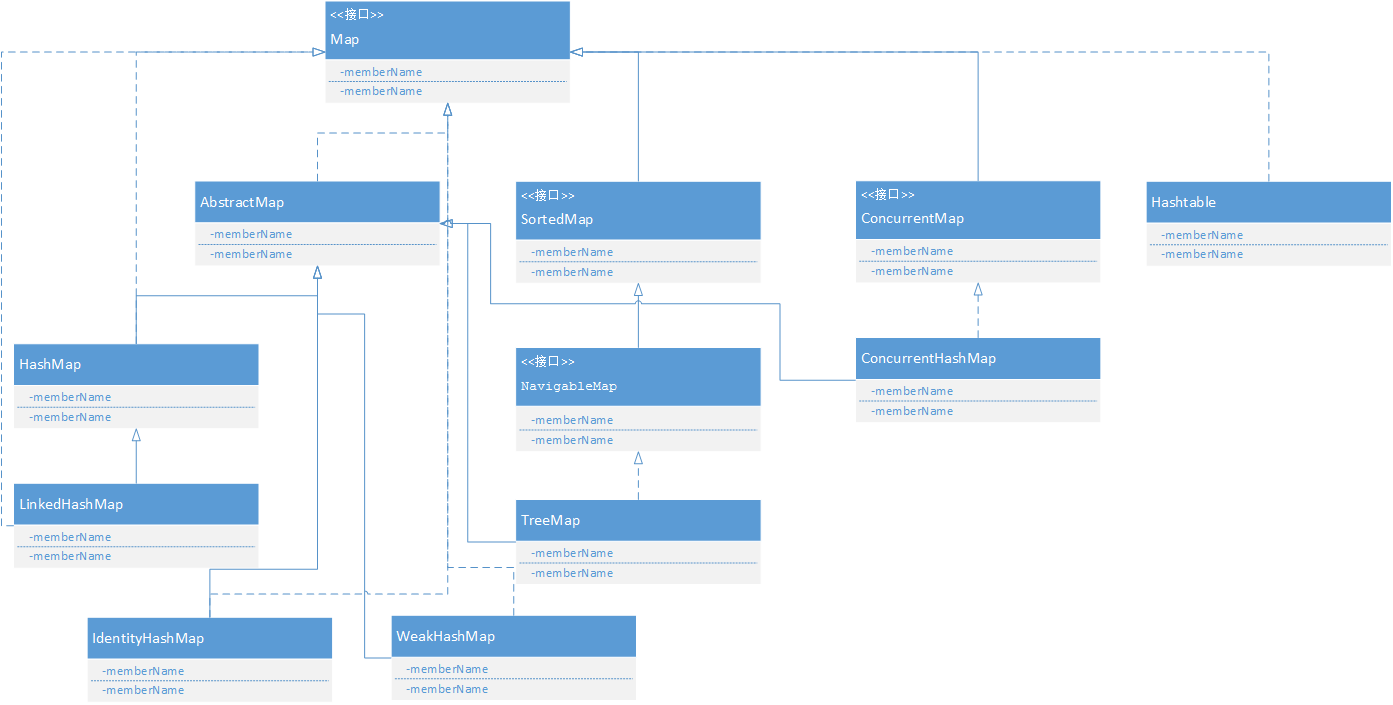
(2)Map
先看看Collection下的东西:
List:
1.可以允许重复的对象。
2.可以插入多个null元素。
3.是一个有序容器,保持了每个元素的插入顺序,输出的顺序就是插入的顺序。
常用的实现类有 ArrayList、LinkedList 和 Vector。
ArrayList和Vector底层都是用数组实现的,最大的区别在于Vector是线程安全的,因此效率不如ArrayList。
LinkedList底层用双链表实现,与前两个相比,优点是便于增删元素,缺点是访问元素性能效率相对低。
(数组连续内存空间,查找速度快,增删慢;链表充分利用了内存,存储空间是不连续的,首尾存储上下一个节点的信息,所以寻址麻烦,查找速度慢,但是增删快。)
还有一点是继承Vector类的Stack,Java自带的栈。进栈push(),弹栈pop(),获取栈顶peek(),判断空否empty()...
Set:
1.不允许重复对象
2. 无序容器,你无法保证每个元素的存储顺序,TreeSet通过 Comparator 或者 Comparable 维护了一个排序顺序。
3. 只允许一个 null 元素
Set 接口最流行的几个实现类是 HashSet、LinkedHashSet 以及 TreeSet。最流行的是基于 HashMap 实现的 HashSet;TreeSet 还实现了 SortedSet 接口,因此 TreeSet 是一个根据其 compare() 和 compareTo() 的定义进行排序的有序容器。
HashSet:哈希表是通过使用称为散列法的机制来存储信息的,元素并没有以某种特定顺序来存放;底层是HashMap。
LinkedHashSet:以元素插入的顺序来维护集合的链接表,允许以插入的顺序在集合中迭代; 底层是HashMap。
TreeSet:提供一个使用树结构存储Set接口的实现,对象以升序顺序存储,访问和遍历的时间很快。底层是TreeMap。
例子:插入BADECF https://www.cnblogs.com/ibook360/archive/2011/11/28/2266062.html
HashSet<String> hs = new xxxxSet<String>();
hs.add("B");
hs.add("A");
hs.add("D");
hs.add("E");
hs.add("C");
hs.add("F");
System.out.println("xxxxSet 顺序:\n"+hs);
HashSet 顺序:
[D, E, F, A, B, C] //无序
LinkedHashSet 顺序:
[B, A, D, E, C, F] //插入顺序
TreeSet 顺序:
[A, B, C, D, E, F] //有序
Queue: https://www.cnblogs.com/zhilu-doc/p/5251643.html
没怎么用过。可以用LinkedList实现,例如:Queue q = new LinkedList();
remove 移除并返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
element 返回队列头部的元素 如果队列为空,则抛出一个NoSuchElementException异常
offer 添加一个元素并返回true 如果队列已满,则返回falsepoll 移除并返问队列头部的元素 如果队列为空,则返回null
peek 返回队列头部的元素 如果队列为空,则返回null
接下来看看Map有什么好东西
Map:
1.Map 不是collection的子接口或者实现类。Map是一个接口。
2.Map 的每个 Entry 都持有两个对象,也就是一个键一个值,Map 可能会持有相同的值对象但键对象必须是唯一的。
3. Map 里你可以拥有随意个 null 值但最多只能有一个 null 键。
4.Map 接口最流行的几个实现类是 HashMap、LinkedHashMap、Hashtable 和 TreeMap。(HashMap、TreeMap最常用)
HashMap https://blog.csdn.net/junchenbb0430/article/details/78643100
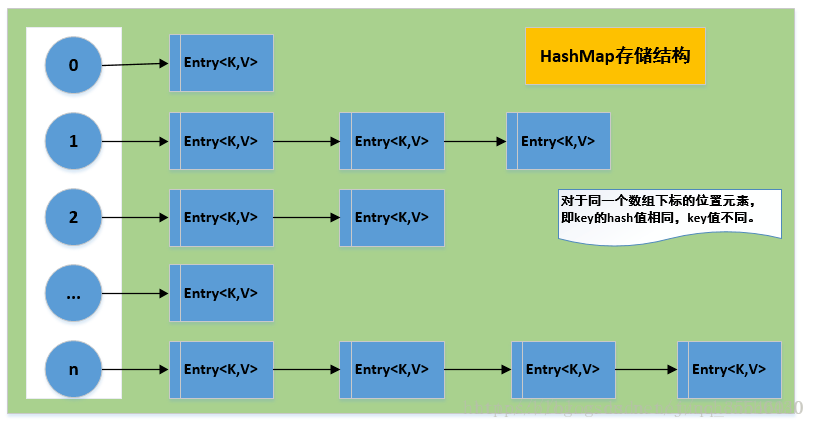
HashMap是最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。因为键对象不可以重复,所以HashMap最多只允许一条记录的键为Null,允许多条记录的值为Null,是非同步的,底层是数组+链表。先对Key用hashcode()计算存放位置,再对Value用equals()遍历链表查找。
在jdk1.8版本后,java对HashMap做了改进,在链表长度大于8的时候,将后面的数据存在红黑树中,以加快检索速度。
(解决链表长度过长时链表的查询性能差的问题)
Hashtable
Hashtable与HashMap类似,是HashMap的线程安全版,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢,它继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低。
ConcurrentHashMap
线程安全,并且锁分离。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的,在遍历的时候会比HashMap慢,有HashMap的全部特性。
TreeMap
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序(自然顺序),也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。不允许key值为空,非同步的;
Map推荐遍历方式
entrySet()
Set<Map.Entry<K,V>> entrySet() //返回此映射中包含的映射关系的 Set 视图。(一个关系就是一个键-值对),就是把(key-value)作为一个整体一对一对地存放到Set集合当中的。Map.Entry表示映射关系。entrySet():迭代后可以e.getKey(),e.getValue()两种方法来取key和value。返回的是Entry接口。
典型用法如下:
//将map集合中的映射关系取出,存入到set集合
Iterator it = map.entrySet().iterator();
while(it.hasNext()){
Entry e =(Entry) it.next();
System.out.println("键"+e.getKey () + "的值为" + e.getValue());
}
https://blog.csdn.net/HHcoco/article/details/53117525