一.HashSet
HashSet底层数据结构采用的是哈希表,元素无序(即不保证元素的排列顺序不会发生改变)且不可重复,增删操作的时间复杂度都是O(1),元素可以且只可以存在一个null值。
另外,HashSet集合判断两个元素是否相等的标准是equals()方法返回值为true且hashCode()方法返回值也相等。
事实上,当一个元素存入HashSet集合中的时候会调用hashCode方法获得其hashCode值,然后根据hashCode值来决定元素在内存中的存储位置。
二.LinkedHashSet
LinkHashSet底层利用哈希表唯一确定元素的存储位置以保证唯一性,同时依靠链表实现元素的插入有序排列(即使得元素的添加顺序将会与元素的访问次序一致)。
演示代码:
package package04_collection;
import java.util.Iterator;
import java.util.LinkedHashSet;
public class LinkedHashSetTest {
public static void main(String[] args) {
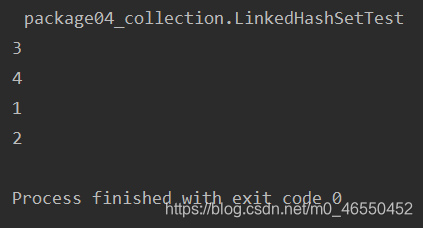
LinkedHashSet<Integer> lhs = new LinkedHashSet<Integer>();
lhs.add(3);
lhs.add(4);
lhs.add(1);
lhs.add(2);
lhs.add(2);
Iterator<Integer> iterator = lhs.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
符合预期效果:
三.TreeSet
TreeSet集合底层结构是红黑树(平衡二叉查找树),用于实现对元素的排序(可自定义排序规则),不允许元素重复且不能存在null值。
测试代码(自然排序)
package package04_collection;
import java.util.Iterator;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
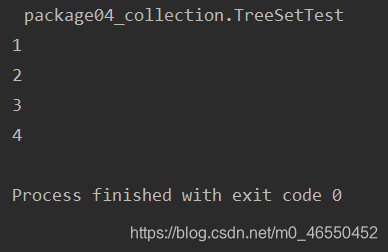
TreeSet<Integer> ts = new TreeSet<>();
ts.add(2);
ts.add(3);
ts.add(4);
ts.add(1);
ts.add(1);
Iterator<Integer> iterator = ts.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
效果截图:
注意:如果当TreeSet元素对象是引用数据类型时,由于不知道该对元素采用何种排序方式,编译器将会报错。这个时候就应该采用自定义排序,实现Comparator接口并重写compare()方法。