目录
TreeSet练习(Comparable和Comparator接口)
接口 Collection<E>
常用的接口和实现类

公有基类方法

通用迭代器:接口 Iterator<E>
用于遍历集合,返回的元素顺序根据实现类的不同而不同

remove():删除上一次调用next()返回的元素。
List<E>接口集合
List<E>接口特有迭代器:接口 ListIterator<E>
系列表迭代器,允许程序员按任一方向遍历列表(0 ~ n,length - 1 ~ 0)、最重要的是:这个迭代期间允许修改列表(添加或删除元素)。

需要注意的是:
ListIterator迭代器的add()方法
ListIterator迭代器的add()方法,不像ArrayList的add()方法一样是追加到末尾的。而ListIterator迭代器的add()方法会将数据插入到调用next()方法后的的后面,如果未调用过next()方法直接调用add()方法,会将元素插入到0索引的前面(之前0索引的元素变成了1索引的位置)。
通过next()指定位置后,add()方法能实现插入到指定位置
List<E>集合常用的具体子类
| 类 | 数据结构 | 优点 | 缺点 |
| Vector | 数组结构:通过删除或添加元素,会不断的new <T>[ size ];, 把旧的数组元素复制到新的数组中。 |
线程同步 | 增、删、查都慢 |
| ArrayList | 数组结构:通过删除或添加元素,会不断的new <T>[ size ];, 把旧的数组元素复制到新的数组中。 |
线程不同步, 查询很快 |
增、删、慢 |
| LinkedList | 链表结构:在堆内存中的数据都是不规则的,通过连续添加元素会: Object(0x0) <—— (0x0) Object (0x1) <—— (0x1) Object (0x2) <—— (0x2) Object (0x3) <—— (0x3) Object (0x4) ... ...n 也就是后一个添加的元素位置会记住前一个元素的地址 |
线程不同步, 增、删速度快 |
查询慢 |
Set<E>接口集合
和接口Collection的方法一样。正常情况下存储的元素是不重复的,而List是允许重复的。
常用具体子类
| 类 | 数据结构 | 优点 |
| HashSet | 哈希 ( 散列)结构。 使用注意:元素必须重写继承自超类Object的hashCode()和equals()方法。 重写hashCode():根据元素自身的特点计算哈希值。 重写equals():为了解决哈希值的冲突。 内部使用了HashMap |
线程不同步, 查询更快 |
| LinkedHashSet | 链表 + 哈希 ( 散列)结构。 因为HashSet不保证元素添加时的顺序, 所以派生自HashSet类的LinkedHashSet就能保证元素添加时的顺序, 在添加元素时此元素位置上记住上一次添加的元素的地址,所以就能保证迭代时的顺序。 |
线程不同步, 查询更快, 存入元素的有序 |
| TreeSet | 二叉树结构。 可对元素进行自定义排序方式。 基本数据类型会自然字典顺序排序(包括JDK某些实现了Comparable<T>接口)。 元素要具备比较性,需要实现Comparable<T>接口,重写int compareTo(Object o)方法, 返回数字有三个: -1(只要是负数),代表小于。 1(只要是正数),代表大于。 0,相等就不存。 如果元素不实现Comparable<T>接口,可以构造一个Comparator<T>比较器。 为了降低耦合性,可以构造一个带有Comparator<T>接口(比较器)的TreeSet, 而不是让元素实现Comparable<T>接口。 内部使用了TreeMap |
线程不同步, 可以自定义排序方式。 |
哈希(散列)算法:简单演示图
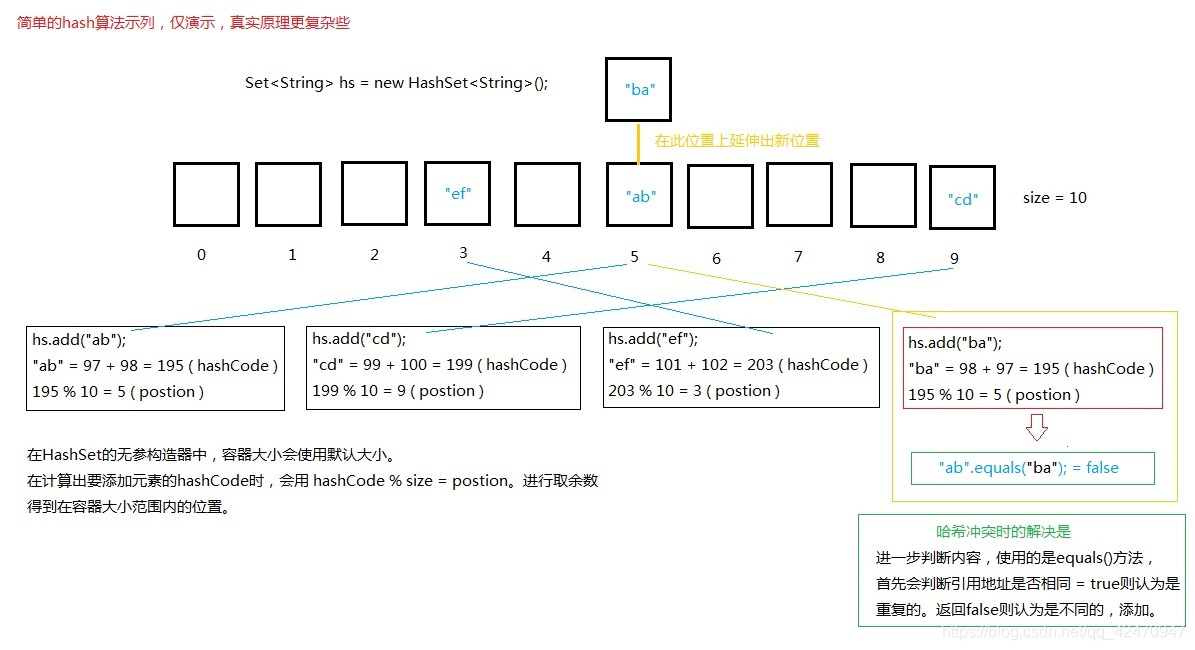
java的String类字符串hashCode算法并不是像图上一样,仅演示,看图:

Object.java的HashCode()方法代码段
public int hashCode() {
int lockWord = shadow$_monitor_;
final int lockWordStateMask = 0xC0000000; // Top 2 bits.
final int lockWordStateHash = 0x80000000; // Top 2 bits are value 2 (kStateHash).
final int lockWordHashMask = 0x0FFFFFFF; // Low 28 bits.
if ((lockWord & lockWordStateMask) == lockWordStateHash) {
return lockWord & lockWordHashMask;
}
//主要的方法,上面的代码段我不知道是干嘛用的,一般都只会执行下面的方法
return System.identityHashCode(this); //将对象的内存16进制地址转换成整数作为HashCode值
}
public boolean equals(Object o) {
return this == o; //只对比引用是否相同
}
//从这个方法知道,是对象的内存地址,通过hashCode值转换成的16进制地址
//而hashCode值是内存16进制地址转换成
public String toString() {
return getClass().getName() + '@' + Integer.toHexString(hashCode());
}测试一般只执行System.identityHashCode(Object);方法是否成立:
Object o = new Object();
System.out.println("地址 = " + o.toString());
System.out.println("hashCode() = " + o.hashCode());
System.out.println("toHex --> hashCode() = " + Integer.toHexString(o.hashCode()));
System.out.println();
System.out.println("identityHashCode() = " + System.identityHashCode(o));
System.out.println("toHex --> identityHashCode() = " + Integer.toHexString(System.identityHashCode(o)));输出:
地址 = java.lang.Object@15db9742
hashCode() = 366712642
toHex --> hashCode() = 15db9742
identityHashCode() = 366712642
toHex --> identityHashCode() = 15db9742所以我们未重写默认的HashCode()方法值是通过对象的内存16进制地址转换为整数而成

HashSet存储元素过程
- 调用元素的hashCode()方法得到哈希值(调用底层函数,对象内存16进制地址转成的整数)
- 通过哈希值与容器大小%取余计算出位置
- 如果此位置上没有元素则添加。如果已有元素,则调用此位置上元素的equals(Object obj)进行比较:返回true则认为是相同的元素,不覆盖。返回false则认为是不同的元素,并对此位置上延伸一个新位置出来,进行添加。(正常情况下,
返回false就要考虑减少元素的哈希算法冲突,这种情况很少发生)。
在使用Set集合前,必须重写原始类型Object的hashCode()和equals()方法。
当然,不重写也没关系,这样只能保证引用的不同而存储,引用相同而不覆盖。
什么时候可以重写?比如:为了保证对象内容数据的唯一而不重复。如下:
HashSet练习
需求:保证对学生对象数据的唯一性。相同数据的学生视为同一个人则不存。
思路:
- 利用以上HashCode值冲突原理。首先重写对象的hashCode()方法:逻辑为用内部数据计算出对象的哈希值(为了让相同数据的对象引起哈希冲突后进一步调用equals()方法比较数据是否相同)。
- 然后重写equals()方法:对比数据值是否相同,如果相同true则认为是同一个对象。
- 如果不同false则认为是不同的对象,此时就是真正的哈希值冲突了,这时候就要尽量保证哈希值算法对对象的唯一性,当然这种现象很少发生。
Student.java
package com.bin.demo;
public class Student {
private String name;
private int age;
Student(String name, int age) {
setName(name);
setAge(age);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() { //这里使用IDE自动生成的,当然也可以自定义
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) { //hash值冲突相同,进一步地判断对象是否唯一
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj; //这行代码到下面是判断,名字和年龄是否相同
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
}
Main函数
public class Main {
public static void main(String[] args) {
Set<Student> hs = new HashSet<Student>();
hs.add(new Student("超神", 17));
hs.add(new Student("剑圣", 16));
hs.add(new Student("铠甲", 18));
hs.add(new Student("斌哥", 20));
hs.add(new Student("神龙", 20));
hs.add(new Student("铠甲", 18));
hs.add(new Student("斌哥", 20));
for (Student s : hs) {
System.out.println(s.toString());
}
}
}输出:
Student [name=铠甲, age=18]
Student [name=神龙, age=20]
Student [name=超神, age=17]
Student [name=剑圣, age=16]
Student [name=斌哥, age=20]
这就保证了不同对象的内部数据的唯一性。
二叉树 (简单介绍)

如图所见:我们在代码实现中,大的元素放右边,小的放左边,排序就是顺序排序(从小到大)。相反则_大的放左边,小的放右变,排序就是逆序排序(从大到小)。
TreeSet练习(Comparable<E>和Comparator<E>接口)
需求:对学生进行升序排序,依据年龄大小进行升序排序。如果年龄相等则对名字进行字典顺序排序,如果名字也相等则认为是相同一个人则不存。
Student.java 需要实现Comparable接口
package com.bin.demo;
public class Student implements Comparable<Student> {
private String name;
private int age;
Student(String name, int age) {
setName(name);
setAge(age);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Student s) { //主要条件:age,次要条件:name
// if (this.age > s.age) {
// return 1;
// } else if (this.age < s.age) {
// return -1;
// } else {
// return this.name.compareTo(s.name);
// }
int isAge = this.age - s.age; //相减不是大于就是小于或等于
return isAge == 0 ? this.name.compareTo(s.name) : isAge; // 如果年龄相等,按名字排序,使用的是字符串的字典顺序。如果名字相等还是返回0不存
}
}
main: 如果元素不实现Comparable接口,则使用Comparator接口比较器进行比较
public class Main {
public static void main(String[] args) {
//同样可以使用比较器对:集合和元素降低耦合,这样可以构造Tree集合传入不同的排序方式
Comparator<Student> cpt = new Comparator<Student>() {
@Override
public int compare(Student news, Student s) {
// if (news.getAge() > s.getAge()) {
// return 1;
// } else if (news.getAge() < s.getAge()) {
// return -1;
// } else {
// return news.getName().compareTo(s.getName());
// }
int isAge = news.getAge() - s.getAge(); //相减不是大于就是小于或者等于
return isAge == 0 ? news.getName().compareTo(s.getName()) : isAge; // 如果年龄相等则用名字进行升序排序,如果名字也相同则不存
}
};
TreeSet<Student> ts = new TreeSet<Student>(cpt);
ts.add(new Student("超神", 17));
ts.add(new Student("剑圣", 16));
ts.add(new Student("铠甲", 18));
ts.add(new Student("斌哥", 20));
ts.add(new Student("神龙", 20));
ts.add(new Student("铠甲", 18));
ts.add(new Student("斌哥", 20));
for (Student s : ts) {
System.out.println(s);
}
}
}
输出:
Student [name=剑圣, age=16]
Student [name=超神, age=17]
Student [name=铠甲, age=18]
Student [name=斌哥, age=20]
Student [name=神龙, age=20]
使用Comparator比较器更为灵活,可以降低集合和元素之间的耦合。可以定义不同的比较器功能,对学生进行不同方式的排序。
增强For循环
增强For在JDK1.5开始出现,迭代功能就抽取出来了
Collection接口 就继承了 Iterable接口,

枚举接口Enumeration<E>迭代器,因为名称过长过时了(此接口只对Vector进行迭代)

JDK1.2后就被Iterator取代了枚举接口Enumeration<E>

public class Main {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
Vector<Integer> v = new Vector<Integer>(list);
//枚举方式迭代器,只有Vector拥有获取此迭代器的方法:已过时
for (Enumeration<Integer> e = v.elements(); e.hasMoreElements();) {
System.out.println(e.nextElement());
}
//通用for循环
for (Iterator<Integer> li = list.listIterator(); li.hasNext();) {
System.out.println(li.next());
}
//高级for循环
for (int i : list) {
System.out.println(i);
//list.add(-1); //发生并发修改异常:java.util.ConcurrentModificationException
}
}
}通用For循环与增强For循环的区别:
- 增强For只能操作Collection接口的类型和数组,并且迭代期间不能操作元素。会报并发修改异常java.util.ConcurrentModificationException异常。
- 通用For循环能操作索引,并且迭代期间可以对元素进行操作。
- 所以增强For只为遍历,开发中减少代码。通用For还是比较强。
Map<K,V>接口集合
键值对的存储方式。保证键的唯一。
需要注意的方法:
- put(K key, V value): 方法,将值与键进行关联,返回的是这个键与上一次关联的值,如果上一次并没有与该键关联的值就返回null。
- remove(key): 删除该键的映射关系,并返回与该键关联的值,如果没有该键则返回null。
- keySet(): 返回Set<K>集合的键。set 支持元素移除,通过 Iterator.remove 操作可从映射中移除相应的映射关系。它不支持 add 或 addAll 操作。
- entrySet() : 返回 Set<Map.Entry<K,V>>集合,Map.Entry是Map接口里的内部的静态接口,此方法将每个键值对封装成了一个Map.Entry<K,V>,该接口有getKey()、getValue()、setValue(V v)、等方法。通过 Iterator.remove 操作可从映射中移除相应的映射关系。它不支持 add 或 addAll 操作。
- values(): 返回Collection<V>集合,返回的都是值。collection 支持元素移除,通过 Iterator.remove 操作可从映射中移除相应的映射关系。它不支持 add 或 addAll 操作。
遍历时不能调用(除Iterator.remove()方法)外的添加和删除元素方法,否则会报 java.util.ConcurrentModificationException
Map集合遍历三种方式
package com.bin.demo;
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Map<String, Integer> m = new HashMap<String, Integer>();
m.put("A", 1);
m.put("B", 2);
m.put("C", 3);
m.put("D", 4);
m.put("E", 5);
// keySet()
Set<String> s = m.keySet();
for (Iterator<String> i = s.iterator(); i.hasNext();) {
String key = i.next();
int value = m.get(key);
System.out.println("key = " + key + " ————> " + "value = " + value);
} // 增强 for (String s : m.keySet())
// entrySet()
Set<Map.Entry<String, Integer>> me = m.entrySet();
for (Iterator<Map.Entry<String, Integer>> i = me.iterator(); i.hasNext();) {
Map.Entry<String, Integer> e = i.next();
String key = e.getKey();
int value = e.getValue();
System.out.println("key = " + key + " ————> " + "value = " + value);
} // 增强 for (Map.Entry<String, Integer> e : m.entrySet())
// values()
Collection<Integer> c = m.values();
for (Iterator<Integer> i = c.iterator(); i.hasNext();) {
int value = i.next();
System.out.println("value = " + value);
} // 增强 for (int value : m.values())
}
}
输出:
key = A ————> value = 1
key = B ————> value = 2
key = C ————> value = 3
key = D ————> value = 4
key = E ————> value = 5
key = A ————> value = 1
key = B ————> value = 2
key = C ————> value = 3
key = D ————> value = 4
key = E ————> value = 5
value = 1
value = 2
value = 3
value = 4
value = 5
这里用的是HashMap,是不保证有序的
Map集合常用子类
| 类 | 数据结构 | 优点 |
| HashTable | 哈希表结构。 | 线程同步, 不允许Null键, 不允许Null值 |
| HashMap | 哈希表结构。 | 线程不同步, 允许Null键, 允许Null值。 |
| LinkedHashMap | 链表 + 哈希表结构。 | 线程不同步, 允许Null键, 允许Null值, 元素的插入是有序的。 |
| TreeMap | 二叉树结构。 元素需要具备比较功能。键需要实现Comparable<E>接口, 如果键不实现Comparable<E>接口,需要构造一个Comparator<E>比较器。 |
线程不同步, 可以对Map集合中的键进行自定义排序。 |
HashMap练习
需求:同样是对学生进行存储,键是学生对象(有名字和年龄),值是存学生当前所在的城市,学生名字和年龄一样则视为同一个人则不存。
Student.java 覆盖equals()和hashCode()方法。
package com.bin.demo;
public class Student {
private String name;
private int age;
Student(String name, int age) {
setName(name);
setAge(age);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() {//同样需要利用哈希冲突原理,然后用equals()方法进行数据的判断是否相同
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
}
Main.java
package com.bin.demo;
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<Student, String> m = new HashMap<Student, String>();
m.put(new Student("啊斌", 20), "广东");
m.put(new Student("雨烟", 19), "广西");
m.put(new Student("豪哥", 22), "江苏");
m.put(new Student("昌弟", 17), "广西");
m.put(new Student("贺弟", 18), "深圳");
m.put(new Student("益达", 23), "北京");
m.put(new Student("啊斌", 20), "广西"); //去了广西:新的值映射到键
m.put(new Student("雨烟", 19), "广东"); //去了广东:新的值映射到键
for (Student s : m.keySet()) {
String value = m.get(s);
System.out.println("key = " + s + " ————> 地址 = " + value);
}
}
}
输出:
key = Student [name=益达, age=23] ————> 地址 = 北京
key = Student [name=啊斌, age=20] ————> 地址 = 广西
key = Student [name=贺弟, age=18] ————> 地址 = 深圳
key = Student [name=雨烟, age=19] ————> 地址 = 广东
key = Student [name=豪哥, age=22] ————> 地址 = 江苏
key = Student [name=昌弟, age=17] ————> 地址 = 广西
TreeMap练习
需求:同样是对学生进行存储。键是学生对象(有名字和年龄),值是存学生当前所在的城市,学生名字和年龄一样则视为同一个人则不存。升序排序:主要条件根据年龄进行排序,次要条件年龄相同后根据名字在编码表的顺序位置进行排序。
Student.java 实现Comparable接口
package com.bin.demo;
public class Student implements Comparable<Student> {
private String name;
private int age;
Student(String name, int age) {
setName(name);
setAge(age);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Student s) {
// if (this.age > s.age) {
// return 1;
// } else if (this.age < s.age) {
// return -1;
// } else {
// return this.name.compareTo(s.name);
// }
int isAge = this.age - s.age; //相减不是大于就是小于或等于
return isAge == 0 ? this.name.compareTo(s.name) : isAge; // 如果年龄相等则用名字进行升序排序,如果名字相同则不存
}
}
Main.java 如果元素不实现Comparable接口,可以使用Comparator接口比较器
package com.bin.demo;
import java.util.Comparator;
import java.util.Map;
import java.util.TreeMap;
public class Main {
public static void main(String[] args) {
//同样可以使用比较器对:集合和元素降低耦合,这样可以构造Tree集合传入不同的排序方式
Comparator<Student> cpt = new Comparator<Student>() {
@Override
public int compare(Student news, Student s) {
// if (news.getAge() > s.getAge()) {
// return 1;
// } else if (news.getAge() < s.getAge()) {
// return -1;
// } else {
// return news.getName().compareTo(s.getName());
// }
int isAge = news.getAge() - s.getAge(); //相减不是大于就是小于或者等于
return isAge == 0 ? news.getName().compareTo(s.getName()) : isAge; // 如果年龄相等则用名字进行升序排序,如果名字也相同则不存
}
};
Map<Student, String> m = new TreeMap<Student, String>(cpt);
m.put(new Student("啊斌", 20), "广东");
m.put(new Student("雨烟", 19), "广西");
m.put(new Student("豪哥", 22), "江苏");
m.put(new Student("昌弟", 17), "广西");
m.put(new Student("贺弟", 18), "深圳");
m.put(new Student("益达", 23), "北京");
m.put(new Student("啊斌", 20), "广西"); //去了广西:新的值映射到键
m.put(new Student("雨烟", 19), "广东"); //去了广东:新的值映射到键
for (Student s : m.keySet()) {
String value = m.get(s);
System.out.println("key = " + s + " ————> 地址 = " + value);
}
}
}
输出:
key = Student [name=昌弟, age=17] ————> 地址 = 广西
key = Student [name=贺弟, age=18] ————> 地址 = 深圳
key = Student [name=雨烟, age=19] ————> 地址 = 广东
key = Student [name=啊斌, age=20] ————> 地址 = 广西
key = Student [name=豪哥, age=22] ————> 地址 = 江苏
key = Student [name=益达, age=23] ————> 地址 = 北京
Comparable接口和Comparator接口比较器
对于Tree集合来说。我们比较器返回的数值,顺序排序(从小到大)和逆序排序(从大到小)都是我们自己的逻辑实现的。
上面的二叉树练习都是顺序排序,所以下面是逆序排序学生的算方法
二叉树 (简单介绍)——方便看放这
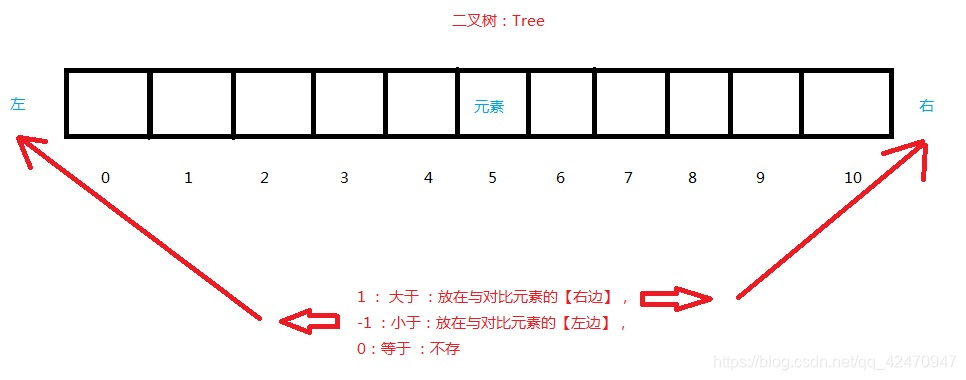
如图所见:我们在代码实现中,大的元素放右边,小的放左边,排序就是顺序排序(从小到大)。相反则_大的放左边,小的放右变,排序就是逆序排序(从大到小)。
Comparable(逆序排序)
@Override
public int compareTo(Student s) {
if (this.age > s.age) {
return -1; //新元素大于旧元素,就放左边
} else if (this.age < s.age) {
return 1; //新元素小于旧元素,就放右边
} else {
return this.name.compareTo(s.name); //如果相等则不存
}
/*旧元素 减 新元素,
* 返回的数据:新元素则会使用旧元素的对比(大、小)
* 如果大于:则把新元素放到右边(此时新元素是小的)
* 如果小于:则把新元素放到左边(此时新元素是大的)
*/
// int isAge = s.age - this.age; //相减不是大于就是小于或等于
// return isAge == 0 ? this.name.compareTo(s.name) : isAge; // 如果年龄相等则用名字进行升序排序,如果名字相同则不存
}Comparator(逆序排序)
Comparator<Student> cpt = new Comparator<Student>() {
@Override
public int compare(Student news, Student s) {
if (news.getAge() > s.getAge()) {
return -1; //新元素大于旧元素,就放左边
} else if (news.getAge() < s.getAge()) {
return 1; //新元素小于旧元素,就放右边
} else {
return news.getName().compareTo(s.getName()); //如果相同不存
}
/*旧元素 减 新元素,
* 返回的数据:新元素则会使用旧元素的对比(大、小)
* 如果大于:则把新元素放到右边(此时新元素是小的)
* 如果小于:则把新元素放到左边(此时新元素是大的)
*/
// int isAge = s.getAge() - news.getAge(); //相减不是大于就是小于或者等于
// return isAge == 0 ? news.getName().compareTo(s.getName()) : isAge; // 如果年龄相等则用名字进行升序排序,如果名字相同则不存
}
};Collections集合工具类
- 二分查找
- 最值
- 元素的排序
- 元素的替换
- 最重要的是:可对非同步集合转成同步集合。
- 等等...
集合转数组
和Collections集合工具类无关,集合转数组是通过Collection接口中的方法:

第一个方法返回后可能根据需求还得强转,通常用第二种方法:传入一个任意类型的(除基本类型)数组,就返回这个类型的数组。
package com.bin.demo;
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
list.add(3);
/*
* 构造和集合相等长度的数组,如果构造的数组大小不合适集合的size,则会自动new相等长度的数组
*/
Integer[] arr = list.toArray(new Integer[list.size()]); //如果数组类型和集合元素类型不匹配,则发生java.lang.ArrayStoreException异常
for (int i : arr) {
System.out.println(i);
}
}
}
输出:
1
2
3
Arrays工具类(操作数组)
- 任何类型的数组进行排序
- 二分查找
- 复制到新数组
- 替换元素
- 转换String
- 数组转集合,注意事项:(转换后不支持对数组的增删)(如果数组元素是基本类型数据,则直接把数组引用当作集合元素。如果数组元素是引用类型数据,则把数组的每个元素当作集合元素存储)
- 等等...
数组转集合注意
package com.bin.demo;
import java.util.Arrays;
import java.util.List;
public class Main {
public static void main(String[] args) {
int[] arr = {1, 2, 3, 4, 5};
List<int[]> aList = Arrays.asList(arr);
// aList.add(new int[] {-1}); //异常: java.lang.UnsupportedOperationException
System.out.println(aList.size()); //打印长度
}
}
输出:
1