理解
人工神经网络:(ANN)对一组输入信号和一组输出信号之间的关系进行建模,使用的模型来源于人类大脑。
激活函数:这个过程涉及对总的输入信号求和,和确定是否能满足激活阈值。如果满足,神经元传递信号,否则,不操作。又称为阈值激活函数。激活函数有很多,自变量是输入和,因变量是输出值,他们之间的差异主要是输出信号的范围不同。要认识到,许多激活函数,影响输出信号的输入范围值是相对较窄的。过高或者过低的输入信号,输出信号会恒为1或0,。因为本质上我们要将输入值压缩到一个较小的范围,(通过标准化或规范化完成),这样可以预防取值尺度很大的特征支配取值尺度较小的特征,也能更快地训练。
网络拓扑:学习能力来源于拓扑结构。有3个关键特征:层的数目,网络中信息是否允许向后传播,网络中每一层内的节点数。
1.层的数目:
单层网络:只有一组连接权重
多层网络:添加一个或多个隐藏层(在信号达到输出节点之前处理来着输入节点的信号)
全连接:前一层的每个节点都连接到下一层的每个节点(这不是必须的)
2.信息传播方向:
前馈网络:网络上的输入信号在一个方向上从一个节点到另一个节点连续第传送,直到到达输出层。
递归网络(反馈网络):允许信号使用循环在两个方向传播。有时候会增加一个短期记忆(又叫延迟),这包含了能够理解经过一段时间的时间序列能力。
3.每一层的节点数:
没有一个可信的规则来确定隐藏层中神经元的个数。过多神经元可能过拟合。最好的做法是基于验证数据集,使用较少的节点产生适用的性能。
用向后传播训练神经网络
向后传播:通过两个过程的多次循环进行迭代。一个迭代成为一个新纪元,通常开始之前随机设置权重,算法通过过程循环,直到到达一个停止准则。包括:前向阶段——神经元被激活后,沿途应用每一个神经元的权重和激活函数,一旦到达最后一层,产生一个输出信号。后向阶段——由前向阶段产生的输出信号与训练数据的真实目标值进行比较,差异产生的误差在网络中向后传播,修正神经元之间的连接权重。
梯度下降:吴恩达在机器学习课上举了这样的例子,你在山坡的某一点要下山,想找最快下山的路,那么就要找到你周围坡度下降最快的方向迈一步,接着再找下降最快的方向,这样每次都选择下降最快的方向,能很快找到最低点。(可能是局部最低点)
R语言实现:
compute函数
compute(x, covariate, rep = 1)
Arguments
x: an object of class nn.
covariate: a dataframe or matrix containing the variables that had been used to train the neural network.
rep:an integer indicating the neural network’s repetition which should be used.(隐藏层的数目,当隐藏层数目为1时,相当于线性模型)
>install.packages("neuralent")
>library(neuralent)
> concrete_model<-neuralnet(strength~cement+slag+ash+water+superplastic+coarseagg+fineagg+age,concrete_train)
> plot(concrete_model)
> model_results<-compute(concrete_model,concrete_test[1:8])
> predict_strength<-model_results$net.result
> cor(predict_strength,concrete_test$strength)#获取两个数值向量的相关性,接近1表示两个变量有很强的相关性
[,1]
[1,] 0.7149014767优化模型:可以提高隐藏层的个数
支持向量机(SVM)
理解:目标是创建一个边界平面(成为超平面),使得任意一边的数据划分都是均匀的,这个平面定义了数据点之间的界限,这些数据点代表根据他们的特征值绘制在多维空间的案例。比如二维空间划分的是一条直线,三维空间划分的是一个平面。
寻找最大间隔:如果分割线不止一种选择,应该如何划分?寻找创建两个类之间最大间隔的最大间隔超平面。
支持向量:每个类中最接近最大间隔超平面的点,每个类必须至少有一个支持向量,也可能有多个。
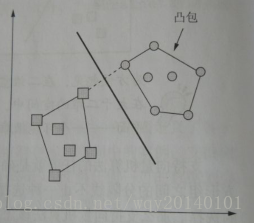
- 线性可分:如果类是线性可分,最大间隔超平面要尽可能远离这组数据点的外边界,这些外边界形成凸包,最大间隔超平面就是凸包直接最短距离的垂直平分线。
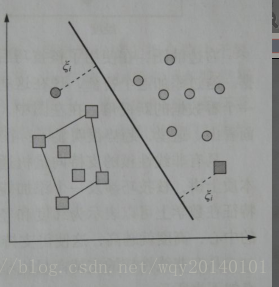
- 非线性可分:使用松弛变量,在距离花费上增加成本(违反约束的点),我们试图使成本最小。
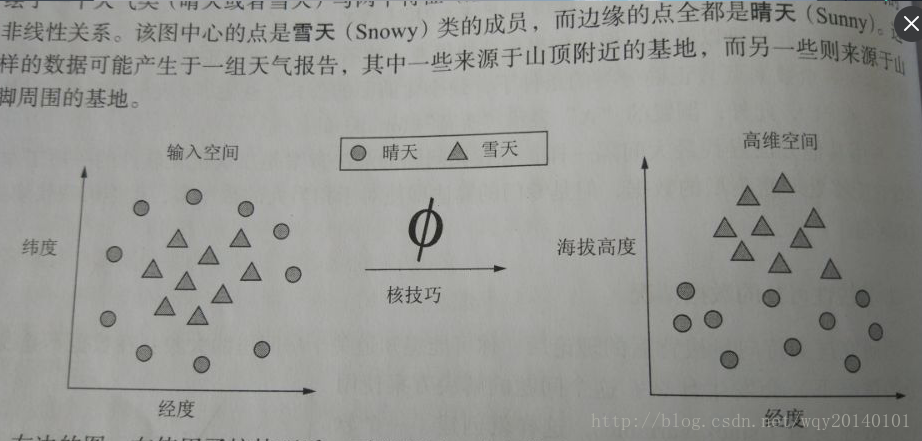
或者,有一种核技巧(将问题映射到更高维的空间)
举例:图像字符识别
>install.packages("kernlab")
> letter_classifier<-ksvm(letter~.,data=letters_train,kernel="rbfdot")
> letter_predictiobs<-predict(letter_classifier,letter_test)
> agreement<-letter_predictiobs==letter_test$letter
> table(agreement)
agreement
FALSE TRUE
281 3719
> prop.table(table(agreement))
agreement
FALSE TRUE
0.07025 0.92975 优化:选择不同的核函数
