前言
今天使用神经网络来为支持向量机(SVM)提供特征,然后实现图片分类。这里直接加载了预训练模型,所以分离器精度不高,若想提高精度要对模型进行细调。
1. 首先导入库,准备数据
使用Wild数据集,首先导入数据集,查看需要处理的数据
import torchvision.models as models
from torchvision import transforms
from torch.nn.parameter import Parameter
from torch.utils.data import DataLoader, Dataset
import cv2
import timm
import torch
import torch.nn as nn
import multiprocessing
from sklearn.svm import SVC
from sklearn.decomposition import PCA as RandomizedPCA
from sklearn.pipeline import make_pipeline
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_lfw_people
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score #准确率得分
import warnings
warnings.filterwarnings('ignore')
num_workers = multiprocessing.cpu_count()
faces = fetch_lfw_people(min_faces_per_person=60)
print(faces.target_names)
print(faces.images.shape)
# 使用ax来定位3行5列画布
fig, ax = plt.subplots(3, 5)
for i, axi in enumerate(ax.flat):
axi.imshow(faces.images[i], cmap='bone')
axi.set(xticks=[], yticks=[],
xlabel=faces.target_names[faces.target[i]])
[‘Ariel Sharon’ ‘Colin Powell’ ‘Donald Rumsfeld’ ‘George W Bush’
‘Gerhard Schroeder’ ‘Hugo Chavez’ ‘Junichiro Koizumi’ ‘Tony Blair’]
(1348, 62, 47)

2. 构建模型和数据加载器
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((64, 64)),
# transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.2, hue=0.2),
transforms.GaussianBlur(kernel_size=3, sigma=(0.1, 2.0)),
transforms.RandomVerticalFlip(),
# transforms.RandomEqualize(),
transforms.ToTensor(),
])
class FaceDataset(Dataset):
def __init__(self, transform=transform, is_test=False, len=256, is_val=True):
self.transform = transform
self.is_test = is_test
self.face = fetch_lfw_people(min_faces_per_person=60)
self.len =len
self.is_val = is_val
def __getitem__(self, idx):
if self.is_val:
idx = self.len - idx
img = self.face.images[idx,:,:]
if not self.is_test:
if self.transform is not None:
img = self.transform(img)
target = self.face.target[idx]
target = torch.as_tensor(target, dtype=torch.float).long()
return img, target
img = img.unsqueeze(0)
return img
def __len__(self):
return self.len # faces.images.shape[0]
# model_names = timm.list_models('*resnet*',pretrained=True)# resnet18
class resnet(torch.nn.Module):
def __init__(self, model_name='resnet18',pretrained=False, num_classes=2): # ,drop=0.1
super().__init__()
resnet18 = timm.create_model(model_name, pretrained=pretrained, in_chans=1, num_classes=num_classes) # , drop_rate=drop, attn_drop_rate=drop
self.backbone = nn.Sequential(*list(resnet18.children())[:-1])
def forward(self, x):
return self.backbone(x)
model_name='resnet18'
resnet = resnet(pretrained=True,model_name=model_name)
- 这里将加载数据写为一个函数方便SVM去调用
# 使用数据加载器加载数据
def getimg(model=resnet, loaders="train"):
# 加载数据的数量
number = 256+64
faceDataset =FaceDataset(len=number)
train_loader = DataLoader(faceDataset, batch_size=256, shuffle=False, num_workers=0, pin_memory=True, drop_last=True)
text_loader = DataLoader(faceDataset, batch_size=64, shuffle=False, num_workers=0, pin_memory=True, drop_last=True)
loader = train_loader if loaders=="train" else text_loader
for image, target in loader:
model.eval()
image2 = model(image).detach().numpy()
return image2, target
每个图像包含(62×47)或近3000像素。有1348张人脸图
这里使用了resnet18网络提取了512个特征
然后将它提供给SVC。下面是将预处理器和分类器打包成管道的代码
为了测试分类器的训练效果,将数据集分解成训练集和测试集进行交叉检验。
3. 对分类器进行训练
#3千个特征过多,一般使用预处理器来提取更有意义的特征(采用PCA主成成分分析法)提取150个基本元素
# pca = RandomizedPCA(n_components=150, whiten=True, random_state=42) # n_components=150
svc = SVC(kernel='rbf', class_weight='balanced') # kernel='rbf'
from sklearn.preprocessing import StandardScaler
model = make_pipeline(StandardScaler(), svc) # 打包管道
# 网格搜索:通过不断调整参数C,和参数gamma(控制径向基函数核的大小),确定最优模型
param_grid = {
'svc__C': [5, 10, 15, 20, 25, 30],
'svc__gamma': [0.001, 0.003, 0.01, 0.03, 0.1, 0.3]}
grid = GridSearchCV(model, param_grid)
image, target = getimg(loaders="train") # 用深度学习网络获得特征
%time grid.fit(image, target)
print(grid.best_params_)
# 最优参数落在了网格的中间位置。如果落在边缘位置,我们还需继续拓展网格搜索范围。接下来,我们可以对测试集的数据进行预测了
CPU times: total: 938 ms
Wall time: 2.05 s
{‘svc__C’: 10, ‘svc__gamma’: 0.001}
4. 检验分类器效果
下面将一些测试图片和预测图片进行对比:
model = grid.best_estimator_ # 向支持向量机中加载最好的参数
face = fetch_lfw_people(min_faces_per_person=60)
image, target = getimg(loaders="text") # 用深度学习网络获得特征
yfit = model.predict(image) # 使用支持向量机进行预测
print('人脸识别分类准确率:',accuracy_score(target, yfit))
fig, ax = plt.subplots(4, 6)
for i, axi in enumerate(ax.flat):
axi.imshow(face.images[i,:,:].reshape(62, 47), cmap='bone')
axi.set(xticks=[], yticks=[])
axi.set_ylabel(faces.target_names[yfit[i]].split()[-1],
color='black' if yfit[i] == target[i] else 'red')
fig.suptitle('Predicted Names; Incorrect Labels in Red', size=14)
人脸识别分类准确率: 0.828125
Text(0.5, 0.98, ‘Predicted Names; Incorrect Labels in Red’)

- 下面我们打印分类效果报告,列举每个标签的统计结果,从而对评估器的性能有更全面的了解:
from sklearn.metrics import classification_report # 分类效果报告模块
print(classification_report(target, yfit,
target_names=faces.target_names))
precision recall f1-score support
Ariel Sharon 1.00 0.50 0.67 2
Colin Powell 0.71 0.92 0.80 13
Donald Rumsfeld 1.00 0.75 0.86 8
George W Bush 0.88 0.88 0.88 24
Gerhard Schroeder 0.67 0.80 0.73 5
Hugo Chavez 1.00 1.00 1.00 1
Junichiro Koizumi 1.00 0.75 0.86 4
Tony Blair 0.83 0.71 0.77 7
accuracy 0.83 64
macro avg 0.89 0.79 0.82 64
weighted avg 0.85 0.83 0.83 64
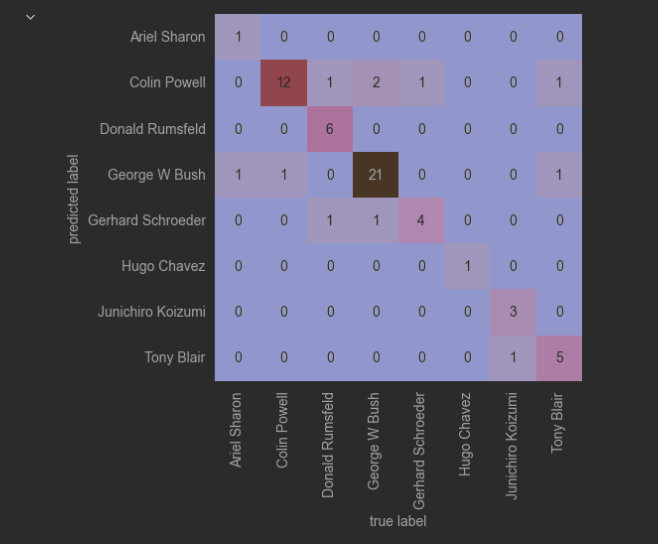
5. 画出人脸数据混淆矩阵
import seaborn as sns
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(target, yfit)
sns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False,
xticklabels=faces.target_names,
yticklabels=faces.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label');