【实习周记】Android中ProtoBuf的使用与序列化原理
一.概述
protobuf(Protocol Buffer)是Google推出的一种与语言无关、平台无关、可扩展的序列化结构数据的方法。在兼容性和传输效率上优于Json和Xml。
二.在Android中使用protobuf
1.在项目中接入protobuf
(1).在项目根目录的build.gradle中添加依赖:
dependencies {
classpath 'com.google.protobuf:protobuf-gradle-plugin:0.8.8'
}
(2).在用到protobuf的module的build.gradle中添加protobuf的plugin:
apply plugin: 'com.google.protobuf'
(3).在module的build.gradle中添加protobuf的配置
protobuf {
protoc {
// You still need protoc like in the non-Android case
artifact = 'com.google.protobuf:protoc:3.6.1'
}
generateProtoTasks {
all().each { task ->
task.builtins {
java {}
}
}
}
}
(4).在module的build.gradle中添加proto文件的路径
android {
sourceSets {
main {
proto {
srcDir 'src/main/proto' //proto文件所在路径
include '**/*.proto'
}
java {
srcDir 'src/main/java'
}
}
}
}
(5).在module的build.gradle中添加protobuf-java和protoc的依赖,其中protoc的依赖很重要,lite版使用方法中不需要添加,所以很容易漏掉。
dependencies {
compile 'com.google.protobuf:protobuf-java:3.6.1'
compile 'com.google.protobuf:protoc:3.1.0'
}
(6).混淆规则
-keep class com.pl.longlink.** {*;} //protobuf生成类的路径
-keep class com.google.protobuf.Any {*;} //如果要用到Any,需要keep
2.创建.proto文件
.proto文件语法规则
(1).syntax:指定proto版本
eg: syntax = “proto3”;
(2).package:默认生成文件的包名
eg: package com.leeduo.protobuf;
(3).option java_outer_classname:指定生成类的类名
eg: option java_outer_classname = “Person”;
(4).option java_package:指定生成文件的包名
eg: option java_package = “com.example.leeduo”;
(5).message:指定可以创建实例的类
(6).类内变量的格式:[修饰符] 类型 变量名 = 数字 [ [default = ] ] [ [packed= true] ];
a).修饰符:
optional:表示修饰的变量可以有也可以没有,proto3移除
required:表示修饰的变量必须有,proto3移除
repeated:表示修饰的变量可以重复,可以表示数组
b).default:为变量设置默认值,使用要带中括号,proto3移除
c).packed:当repeated存在时的选项,可以改变repeated修饰的变量的序列化传输方式。
eg: string name = 1 [default = “jack”];
d).类型:
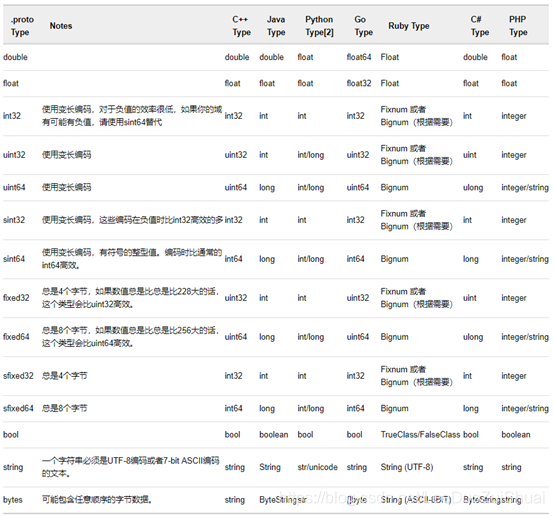
e).数字:该数字为每一个变量(key)在同一个局域下唯一的标识(tag),大于等于1,0留给未初始化的时候用。
3.在代码中使用protobuf
1.编写.proto文件
2.编译项目,生成中间类
3.调用中间类的方法,生成消息对象
4.序列化:writeTo(); 反序列化:parseFrom();
说明:使用提供的builder构建对象
正常情况,使用set方法填充数据
对于被repeated修饰的变量,使用add方法添加
在.proto文件中创建枚举类时,tag要从0开始,其他情况。从1开始。
三.protobuf序列化原理
1.序列化
Protocol Buffer将消息里的每个字段进行编码后,再利用T - L - V 存储方式进行数据的存储,最终得到的是一个二进制字节流
序列化 = 编码 + 存储
Protocol Buffer对于不同数据类型采用不同的序列化方式
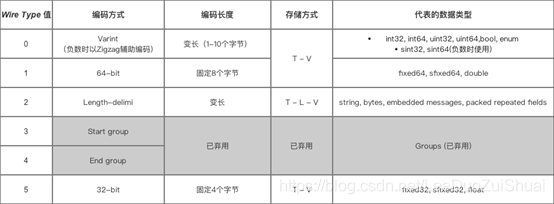
2.数据传输方式:T-L-V
Tag - Length - Value,标识 - 长度 - 字段值
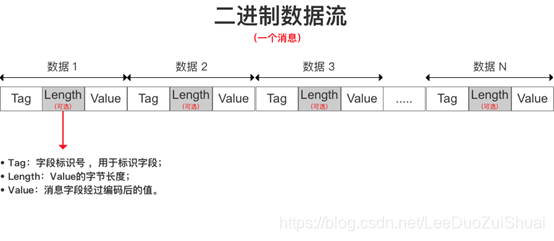
(1).Tag:字段标识符,由字段的数据类型(wire_type)和标识号(field_number)构成
Tag的计算公式:Tag = (field_number << 3) | wire_type
通常Tag占用一个字节的长度,如果标识号超过了16,则占用多一个字节的位置
(2).Length:Value的字节长度采用Varint编码
(3).Value:编码后的消息字段的值
3.编码方式
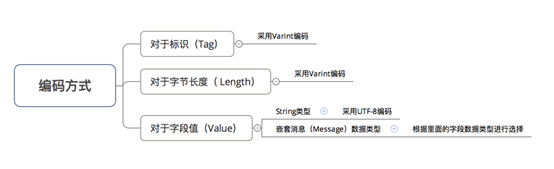
(1).64-bit和32-bit
编码后的数据具备固定大小 = 64位(8字节) / 32位(4字节)
两种情况下,都是高位在后,低位在前
(2).Varint
取出字节串末7位,在最高位添加1构成一个字节。
如果是最后一次取出,则在最高位添加0构成1个字节。
通过将字节串整体往右移7位,继续从字节串的末尾选取7位,直到取完为止。
将形成的每个字节按序拼接成一个字节串,该字节串就是经过Varint编码后的字节。
a).Varint 编码方式的不足
计算机定义负数的符号位为数字的最高位,采用Varint编码方式表示一个负数,需要5个byte。
b).解决
sint32 / sint64 类型表示负数,通过先采用 Zigzag 编码(将有符号数转换成无符号数),再采用Varint编码,从而用于减少编码后的字节数。
(3).Zigzag
编码:sint32:(n <<1) ^ (n >>31)
sint64:(n <<1) ^ (n >>63)
解码:(n >>> 1) ^ -(n & 1)
(4).UTF-8
string类型采用UTF-8编码
4.存储方式
T-V或T-L-V
说明:
repeated修饰的字段
无packed: 以多个 T - V对存储
有packed:以T - L - V - V – V-……方式存储
5.使用建议
(1).字段标识号(Field_Number)尽量只使用 1-15,且不要跳动使用,因为Tag里Field_Number是需要占字节空间的。如果Field_Number>16时,Field_Number的编码就会占用2个字节,
那么Tag在编码时也就会占用更多的字节。
(2).若需要使用的字段值出现负数,请使用sint32 / sint64,不要使用int32 / int64因为采用sint32 / sint64数据类型表示负数时,会先采用Zigzag编码再采用Varint编码,从而更加有效压缩数据。
