一、前言
-
Protobuf是一种轻便高效的结构化数据存储格式,可以用于结构化数据序列化,很适合做数据存储或 RPC 数据交换格式。它可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
-
可以简单理解为,是一种跨语言、跨平台的数据传输格式。与json的功能类似,但是无论是性能,还是数据大小都比json要好很多。
-
protobuf的之所以可以跨语言,就是因为数据定义的格式为.proto格式,需要基于protoc编译为对应的语言。
二、效果
既然说到了性能,还是数据大小都比json要好很多。那么我们不如来用一个例子了解一下具体展现在哪里。这同一个数据经过Protobuf和Json格式转换后的数据大小。可以直观的看到Protobuf足足少了四分之三。

三、教程
1)安装
protobuf下载地址
我是windows所以就选择了windows的包
将protoc-23.1-win64.zip解压后打开该目录的bin目录,复制路径
打开电脑的环境变量设置,在系统变量下面选择Path变量编辑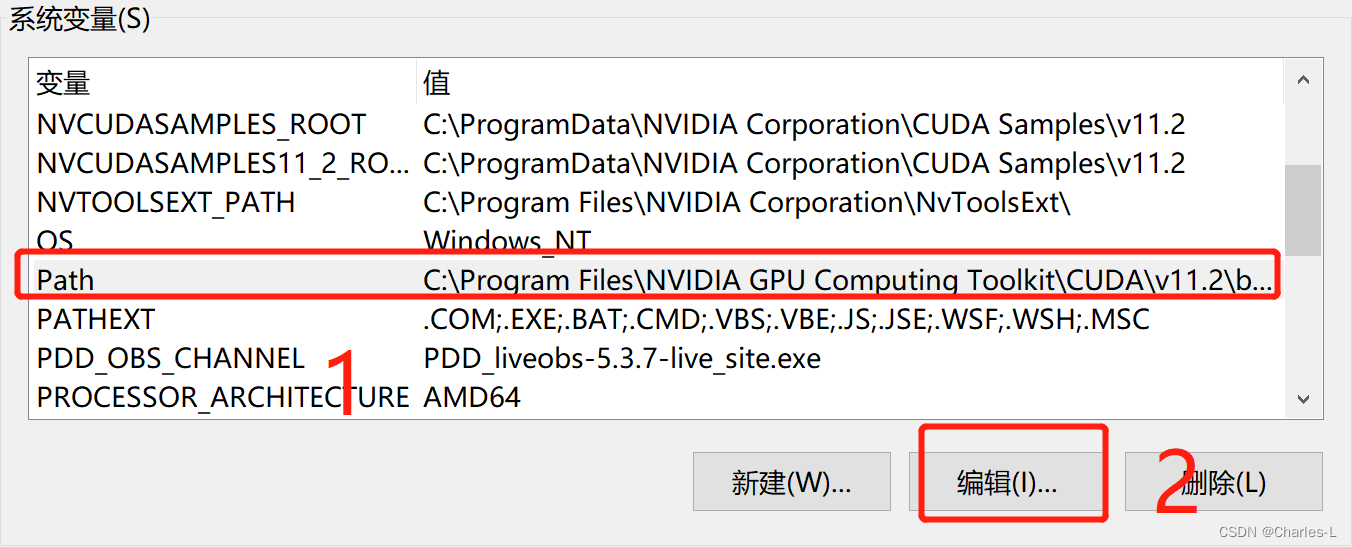
新建一个,然后将复制的路径粘贴到下面
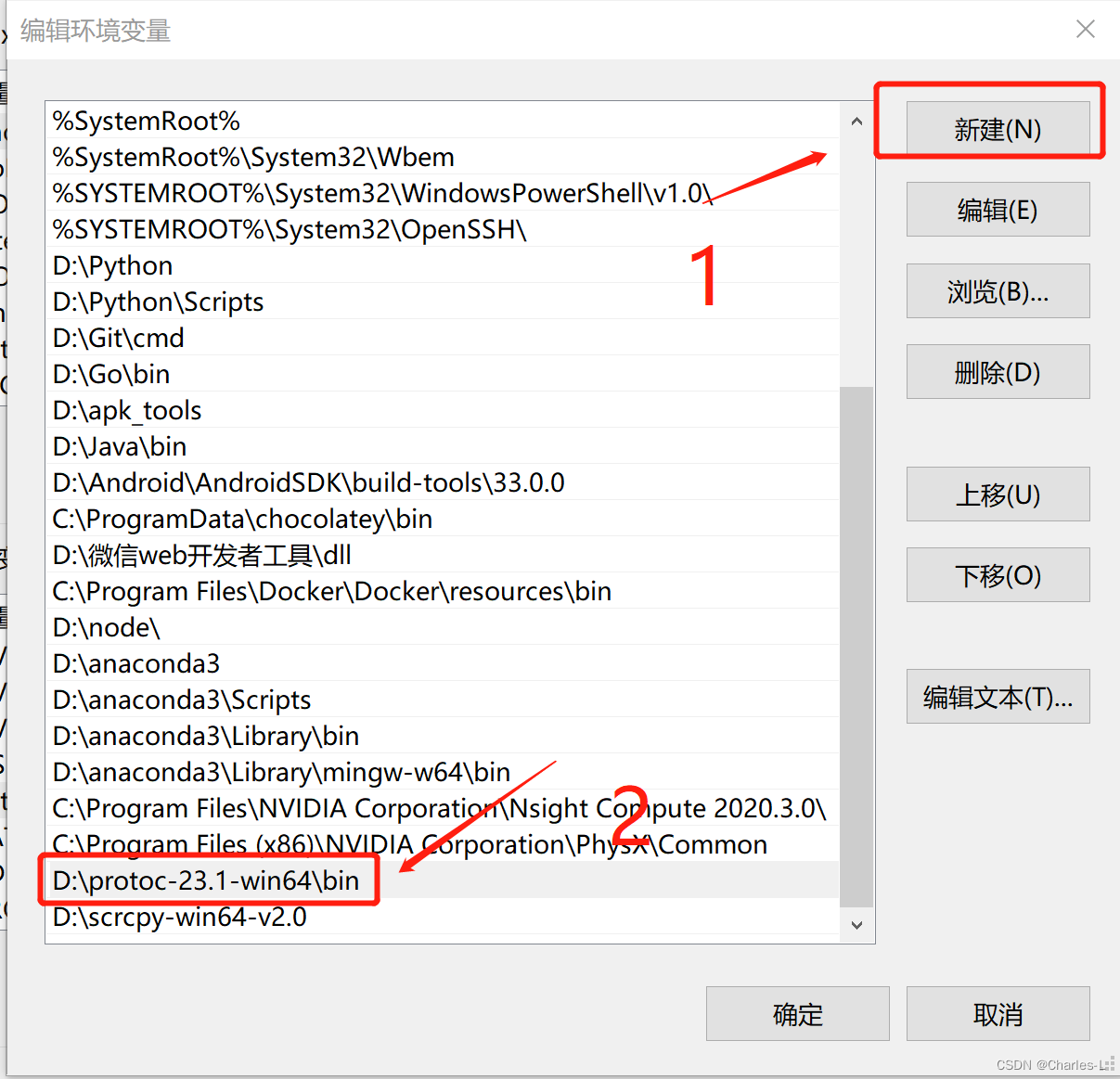
在命令行敲一下下面命令查看是否可以正常调用
protoc --version

然后再解压protobuf-23.1.zip文件,找到python
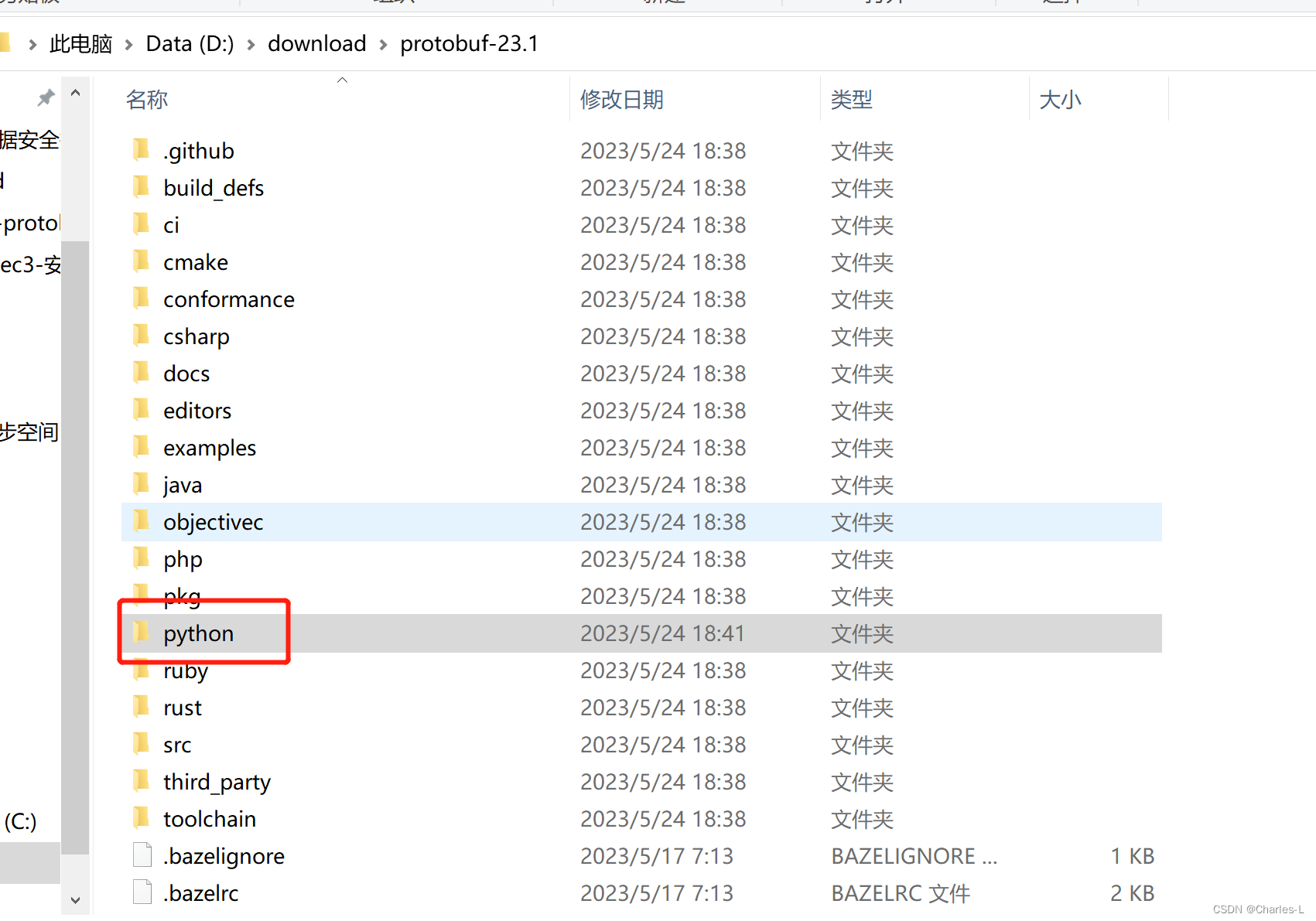
)
python目录打开cmd将下面三条命令敲入(pip的protobuf和下载的protobuf版本最好一致)–要在当前目录下的cmd噢
pip install protobuf
python setup.py build
python setup.py install
cmd打开python可以正常输入下面命令就代表安装成功了。
from google.protobuf.internal import builder

2)使用
一个大概流程图
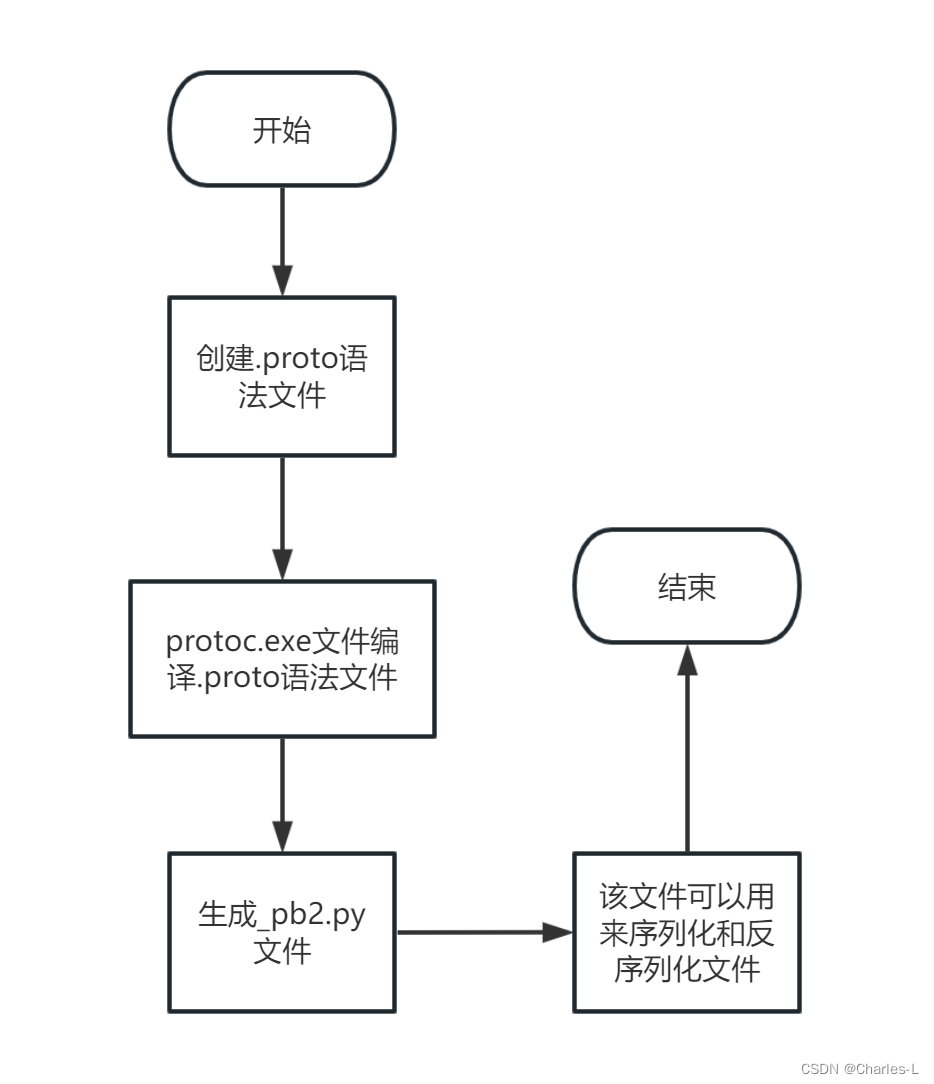
1.创建.proto文件
根据流程图,我们第一步是创建一个.proto文件
2.proto语法
既然知道这是一个语法文件,那么里面肯定是要写一些语法在里面的。
这些语法是相当于一个和使用者的约定,约定这些字段是这种语法定义的结构。(这里只是基础例子写的语法,具体的可以看文章gRPC之proto语法)
//第一行的含义是使用的是proto3的语法,如果没有这句,则默认使用proto2;
syntax = "proto3";
/*Person定义有三个承载消息的属性,每一个被定义在Person 消息体中的字段,都是由数据类型和属性名称组成。
里面的1,2,3是代表了编号,protobuf为了节省空间,使用了编号来代替字段名,只有服务器和客户端拥有同样的proto语法文件才可以知道正确的字段名
不然解析出来的也是1,2,3为代表的结果
*/
message Person {
int32 id = 1;
string name = 2;
message Iphone {
string number = 1;
}
//repeated: 这个属性代表了可以重复增加,就相当于往List数组增加数据
repeated Iphone phones = 3;
}
message totalPerson{
repeated Person person = 1;
}
3.protoc.exe文件编译.proto语法文件
在cmd输入下面命令,example.proto是你写的.proto语法文件。
protoc --python_out=. example.proto

然后会在同级目录下出现example_pb2.py文件
4.序列化
既然得到了example_pb2.py文件,那我们可以开始尝试序列化一份数据了。
先创建一份main.py文件,通过定义好的example_pb2.py文件语法来定义数据(实则是根据.proto文件来定义),然后进行一个序列化操作(使用SerializeToString)。
import example_pb2
# 从生成的example_pb2导入totalPerson(相当于初始化对象)
result_pro = example_pb2.totalPerson()
# 从语法文件可以看到totalPerson中有repeated就代表person是可以被add多个的,我们这里就新增一个就好了;
person_message = result_pro.person.add()
# person被初始化后,就可以定义里面的属性了
person_message.id = 1
person_message.name = "laowang"
# 基础属性定义完后,还有一个复合属性phones,这里对他进行一个新增初始化
phone = person_message.phones.add()
# 定义对象属性
phone.number="123456"
# 这里是将定义好的数据进行一个序列化操作
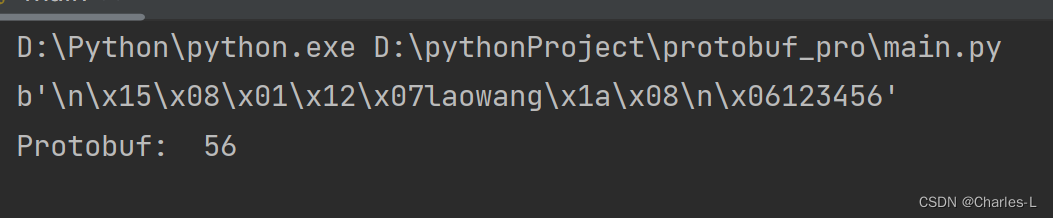
result=result_pro.SerializeToString()
print(result)
print("Protobuf: ", result.__sizeof__())
# 这里是将定义好的数据进行一个序列化操作并且存入到bin文件
with open("my_example.bin", "wb") as f:
f.write(result)
5.反序列化
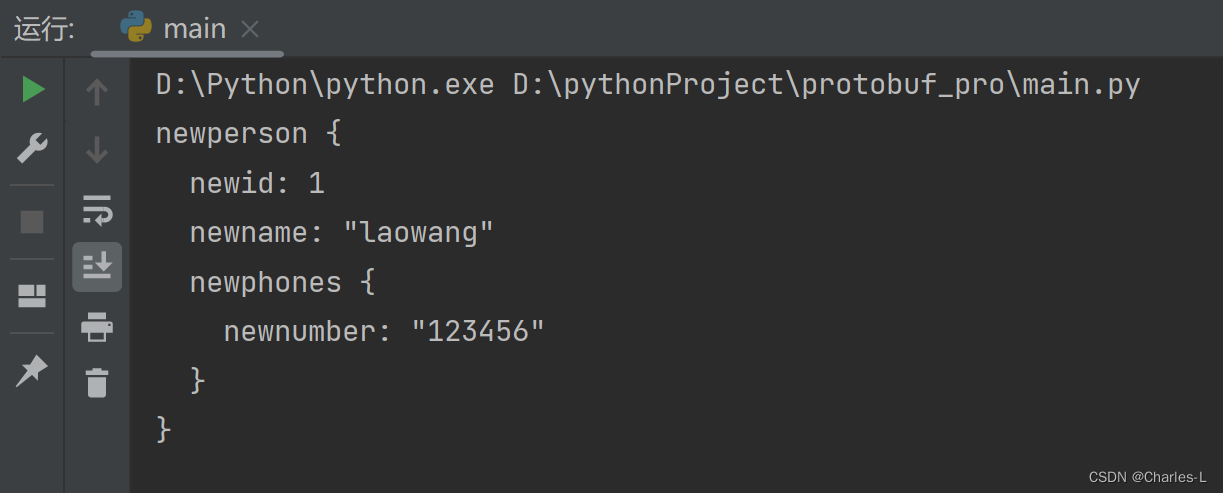
上图可以看到成功序列化数据出来了,我们现在则要对保存的bin文件进行反序列化
- 先通过有proto语法文件的反序列化(使用ParseFromString)
import example_pb2
# 从生成的example_pb2导入totalPerson(相当于初始化对象)
result_pro = example_pb2.totalPerson()
with open("my_example.bin", "rb") as f:
result_pro.ParseFromString(f.read())
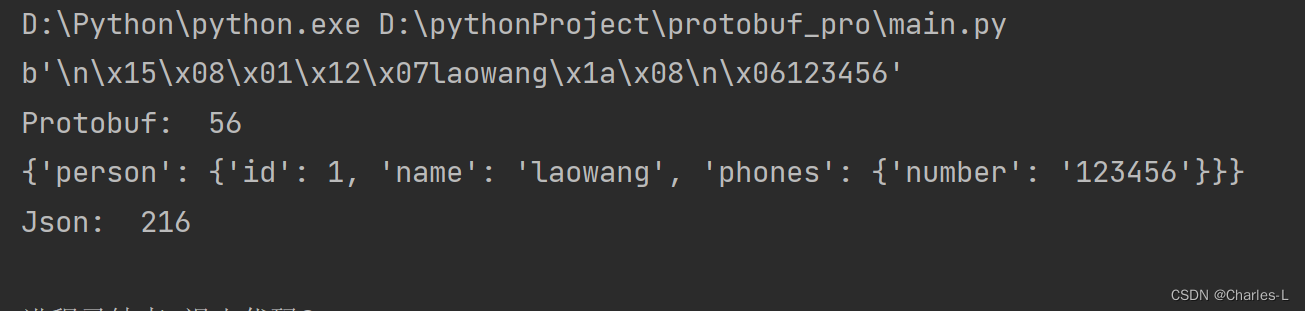
print(result_pro)
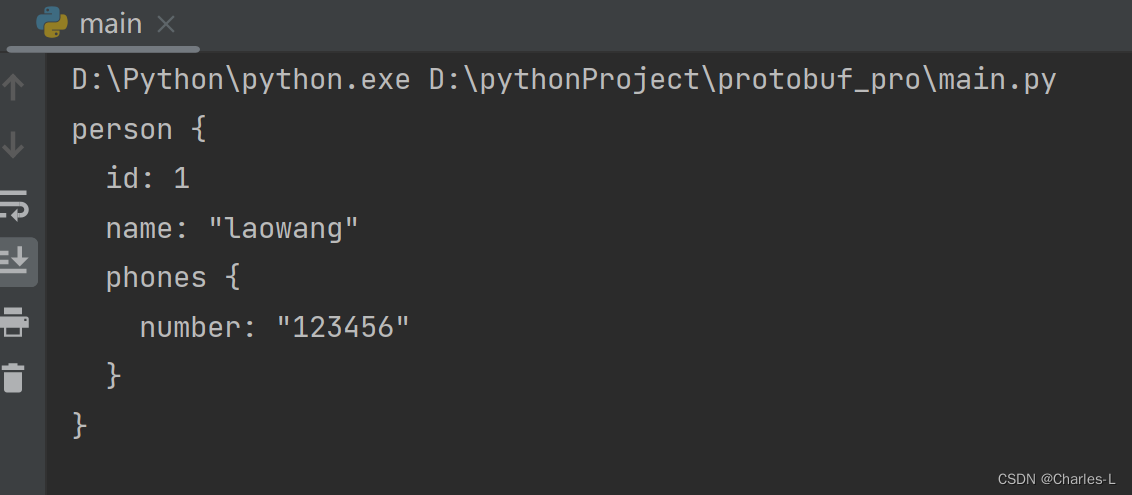
可以看到很好的还原出来了我们定义并且想要的数据格式。接下来我们看看json类似的数据格式与之对比
- 无proto语法文件的反序列化
如果没有语法文件呢,不用急,protobuf给了我们这样一个工具可以帮助我们除了键名基本还原出来。(在my_example.bin同级目录下打开cmd输入下面命令)
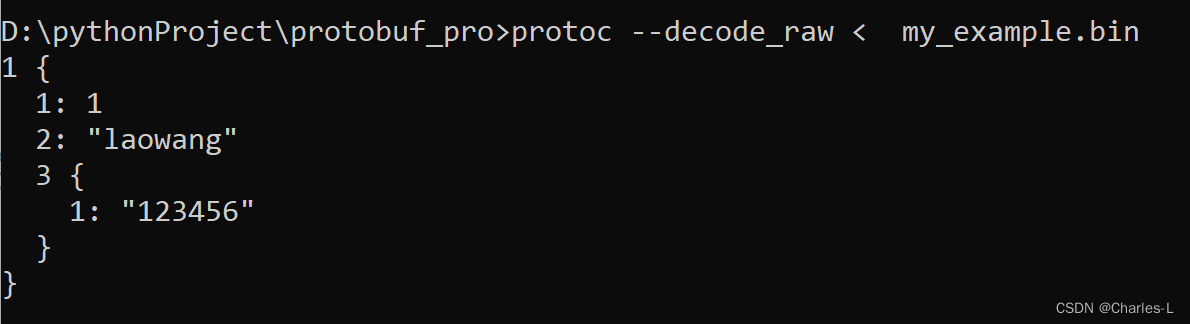
protoc --decode_raw < my_example.bin
可以得到下面的数据结构,对比上面除了键名不同其他都是一样的,这就是protobuf对于键名不是很敏感的原因,他更敏感我们上面注释说的编号。这里展现的就是我们之前给键名定义的编号。
所以如果想要复刻只需要自己重新写一个proto语法文件,对照着编号结构,重新起一个键名进行生成_pb2.py文件去达到序列化相同的数据结构。
新建一个myprotobuf.proto语法文件,把键名全部换了(图方便相当于根据上图的结果来模拟一个.proto语法结构)
syntax = "proto3";
message newPerson {
int32 newid = 1;
string newname = 2;
message newIphone {
string newnumber = 1;
}
repeated newIphone newphones = 3;
}
message newtotalPerson{
repeated newPerson newperson = 1;
}
然后编译它生成myprotobuf_pb2.py
protoc --python_out=. myprotobuf.proto
修改main.py文件调用,这里还是读取我们上次序列化数据的bin文件
import myprotobuf_pb2
# 从生成的example_pb2导入totalPerson(相当于初始化对象)
result_pro = myprotobuf_pb2.newtotalPerson()
# 反序列化
with open("my_example.bin", "rb") as f:
result_pro.ParseFromString(f.read())
print(result_pro)
可以看到成功反序列化出来了数据