(本文为原创,转载请注明:https://blog.csdn.net/wht506520189/article/details/104067982)
系统日志分析
1 需求分析
XX系统的日志量非常庞大,每天落地日志将近四亿到五亿条。XX表有二十几个字段。这里选择对每日业务量峰值和业务总量进行分析。
1.1 分析对象
每日业务量峰值、业务总量。
1.2 分析目标
预测下一日业务量峰值、业务总量。
1.3 实施措施
进行时间序列分析。
2 时间序列分析背景调研
2.1 什么是时间序列
在生产和科学研究中,对某一个或一组变量x(t)进行观察测量,将在一系列时刻t1, t2, …, tn (t为自变量且t1<t2<…< tn ) 所得到的离散数字组成序列集合x(t1), x(t2), …, x(tn),我们称之为时间序列,这种有时间意义的序列也称为动态数据。这样的动态数据在自然、经济及社会等领域都是很常见的。如在一定生态条件下,动植物种群数量逐月或逐年的消长过程、某证券交易所每天的收盘指数、每个月的GNP、失业人数或物价指数等等。
时间序列分析是根据系统观测得到的时间序列数据,通过曲线拟合和参数估计来建立数学模型的理论和方法。它一般采用曲线拟合和参数估计方法(如非线性最小二乘法)进行。时间序列分析常用在国民经济宏观控制、区域综合发展规划、企业经营管理、市场潜量预测、气象预报、水文预报、地震前兆预报、农作物病虫灾害预报、环境污染控制、生态平衡、天文学和海洋学等方面。
2.2 时间序列建模的基本步骤
首先,用观测、调查、统计、抽样等方法取得被观测系统时间序列动态数据。
其次,根据动态数据作相关图,进行相关分析,求自相关函数。相关图能显示出变化的趋势和周期,并能发现跳点和拐点。跳点是指与其他数据不一致的观测值。如果跳点是正确的观测值,在建模时应考虑进去,如果是反常现象,则应把跳点调整到期望值。拐点则是指时间序列从上升趋势突然变为下降趋势的点。如果存在拐点,则在建模时必须用不同的模型去分段拟合该时间序列,例如采用门限回归模型。
最后, 辨识合适的随机模型,进行曲线拟合,即用通用随机模型去拟合时间序列的观测数据。对于短的或简单的时间序列,可用趋势模型和季节模型加上误差来进行拟合。对于平稳时间序列,可用通用ARMA模型(自回归滑动平均模型)及其特殊情况的自回归模型、滑动平均模型或组合-ARMA模型等来进行拟合。当观测值多于50个时一般都采用ARMA模型。对于非平稳时间序列则要先将观测到的时间序列进行差分运算,化为平稳时间序列,再用适当模型去拟合这个差分序列。
2.3 时间序列分析目的
①系统描述。根据对系统进行观测得到的时间序列数据,用曲线拟合方法对系统进行客观的描述。
②系统分析。当观测值取自两个以上变量时,可用一个时间序列中的变化去说明另一个时间序列中的变化,从而深入了解给定时间序列产生的机理。
③预测未来。一般用ARMA模型拟合时间序列,预测该时间序列未来值。
④决策和控制。根据时间序列模型可调整输入变量使系统发展过程保持在目标值上,即预测到过程要偏离目标时便可进行必要的控制。
可以这么说,时间序列分析的目的是,试图明白过去并且预测未来。
3 基础知识
3.1 平稳性
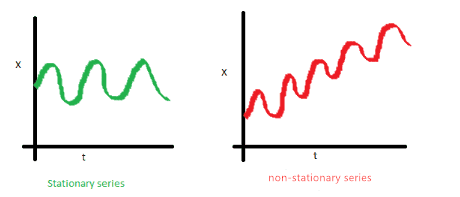
如果数据是平稳性的,它要满足以下性质:
- 序列的平均值不应该是时间的函数。下图中红色的线是不平稳的,因为它的平均值随时间增长。
-
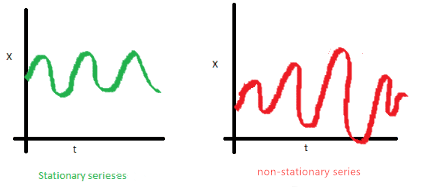
序列的方差不应该是时间的函数。这个属性被称为同方差。注意到红色数据随时间的变化很大。
-
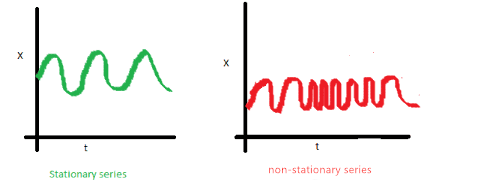
第i项和第i+m项的协方差不应该是时间的函数。在下面的图中,你会注意到随时间的推移差距变得越来越近。因此,红色序列的协方差是随时间变化的。
分析可知,如果一个序列,它的均值和方差是一个常数,则这个序列具有平稳性。但实际上很难达到这个条件,大多数的序列的均值和方差会随着时间有细微的变动,并不严格的是一个常数,这样的序列称之为具有弱平稳性的序列。
为什么要关心数据的平稳性?
一个平稳的时间序列是容易进行预测的,我们可以假设其未来与现在的统计属性是相同的或成比例的。
我们用的大多数时间序列分析模型都是假设协方差平稳。这就意味着这些预测模型的统计描述如均值、方差、协方差等只有在序列平稳时才是有效的,否则无效。
如上所说,金融证券中的大多数时间序列都是不平稳的。因此,有一大部分时间序列分析需要检验我们要预测的序列是否是平定的,如果它不是,我们怎需要找到方法去把它转化成平稳的序列。
3.2 序列相关
实质上,当我们对一个时间序列建模时,我们将该系列分成三个部分:趋势、周期和随机。随机分量称为残差或误差。它仅仅是预测值与观测值的差异。当我们模型的残差彼此相关时是自相关。
3.2.1 自相关
自相关系数可以这么理解:把一列数据按照滞后数拆成两列数据,在对这两列数据做类似相关系数的操作。如下一个例子,
,此为原始序列;拆成
两个序列,这组数据是求滞后数为2的自相关系数,则变成求 两者的“相关系数”,相关系数打引号是因为这个相关系数的公式和以往的有点不一样。自相关系数的推导公式如下:
可以这么理解自相关系数, 她就是用来表达一组数据前后数据 (自己和自己) 的相关性的。
3.2.2 偏自相关
滞后 k 偏自相关系数就是指在给定中间 k-1 个随机变量 的条件下,或者说,提出了中间 k-1 个随机变量的干扰之后, 可以用 Yule-Walker方程求解,如下形式:
其中,
3.3 为什么要关注序列相关性
我们关心的序列相关(自相关)是因为它对我们的模型预测的有效性是至关重要的,是与平稳性密切相关。回想一下,根据定义一个平稳的时间序列的残差是连续不相关的。如果在模型中我们不能解释这一点,我们系数的标准误差的作用会被降低,从而膨胀了T统计量的大小。使得结果中存在太多Type-1误差,使得我们拒绝我们的零假设即使是在它是真的。忽略自相关意味着我们的模型预测将是空谈,我们在的模型中可能得出了有关自变量的影响的不正确的结论。
4 相关算法
4.1 白噪声
白噪声是第一个需要明白的时间序列模型。根据定义,一个白噪声过程的时间序列具有连续不相关的误差,并且那些误差的预期平均值等于零。另一个关于连续不相关误差的描述是独立同分布。这很重要,因为如果我们的TSM(Time Series Model)是得当的,并且成功的捕获了基本过程,那么我们模型的残差将会是独立同分布的,类似于白噪声过程。因此,一部分时间序列分析是在试图拟合时间序列致使残差序列与白噪声不可区分。
下面模拟白噪声的过程。用一个函数,绘制时间序列和分析序列相关。代码如下:
import mpl_toolkits.axisartist.axislines as axislines
import pandas as pd
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.graphics.api import qqplot
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
def tsplot(y, lags=None, figsize=(10,8), style='bmh'):
if not isinstance(y, pd.Series):
y = pd.Series(y)
with plt.style.context(style):#定义局部样式
fig = plt.figure(figsize=figsize)
layout = (3, 2)
ts_ax = plt.subplot2grid(layout, (0, 0), colspan=2)
acf_ax = plt.subplot2grid(layout, (1,0))
pacf_ax = plt.subplot2grid(layout, (1,1))
qq_ax = plt.subplot2grid(layout, (2,0))
pp_ax = plt.subplot2grid(layout, (2,1))
y.plot(ax=ts_ax)
ts_ax.set_title('Time Series Analysis Plots')
sm.graphics.tsa.plot_acf(y, lags=lags, ax=acf_ax, alpha=0.5)#自相关系数ACF图
sm.graphics.tsa.plot_pacf(y, lags=lags, ax=pacf_ax, alpha=0.5)#偏相关系数PACF图
sm.qqplot(y, line='s', ax=qq_ax)#QQ图检验是否是正太分布
qq_ax.set_title('QQ Plot')
stats.probplot(y, sparams=(y.mean(), y.std()), plot=pp_ax)
plt.tight_layout()
plt.show()
return
np.random.seed(1)
randser = np.random.normal(size=1000)#高斯概率分布
tsplot(randser, lags=30)
运行后如下:

可以看出这个过程是随机的并且中心为0。ACF和PACF图也显示没有明显的相关性。在QQ和概率图中,将数据的分布与另一个理论分布进行比较。在这个示例中,理论分布是标准正态分布。显然,数据是随机分布的,遵循高斯(正常)白噪声分布。
4.2 随机游走
随机游走(Random Walk)的意义在于它是非稳定的,因为观察点之间的协方差是时间相关的。如果我们建模的TS是一个随机游走,那么它是不可预测的。
使用“numpy.random.normal(size = our_sample_size)”函数从标准正态分布中抽样模拟一个随机游走。Python代码如下:
np.random.seed(1)
n_samples = 1000
x = w =np.random.normal(size=n_samples)
for t in range(n_samples):
x[t] = x[t-1] + w[t]
_ = tsplot(x, lags=30) #上面的tsplot函数
运行后,得到下图:

显然,通过随机游走产生的时间序列不是固定的。随机游走模型如下:
因此,随机游走系列的一阶差分应该等于一个白噪声过程。 在产生的随机游走序列进行一阶差分,使用“np.diff()”函数,代码如下:
np.random.seed(1)
n_samples = 1000
x = w =np.random.normal(size=n_samples)
for t in range(n_samples):
x[t] = x[t-1] + w[t]
#随机游走序列的一阶差分
_ = tsplot(np.diff(x),lags=30)
运行结果如下:

很明显,我们生成的随机游走序列的一阶差分是一个白噪声序列。
4.3 线性模型
假设因变量 y 和 k 个自变量 之间存在简单的线性关系:
其中 是一个随机变量。进一步假定对自变量的 n 组不同取值,得到因变量 y 的 n 次观测,则有:
其中,
4.4 回归模型
4.4.1 线性回归
线性回归模型是指因变量和自变量之间的关系是直线型的。 回归分析预测法中最简单和最常用的是线性回归预测法。与线性模型类似,假设因变量 y 和 k 个自变量 之间有联系,每个影响因子都会对 y 产生一定的影响,设每个影响因子所占的比重为 则有:
其中
4.4.2 逻辑回归
也称对数几率回归。逻辑回归(Logistic Regression, LR)模型其实仅在线性回归的基础上,套用了一个逻辑函数,但也就由于这个逻辑函数,使得逻辑回归模型成为了机器学习领域一颗耀眼的明星,更是计算广告学的核心。这里的逻辑函数就是Sigmoid函数:
将 t 换成 ax+b 就可得线性回归模型:
4.4.3 多项式回归
上述所有内容均是真对线性模型,如果y 与 x 有非常明显的非线性关系,则可能需要用到非线性回归,如多项式回归,通用多项式回归方程如下 :
- 首先可以构建出 [xn,x{n-1},\cdots,x] ,然后进行线性回归,
- 在进行多项式回归时,如果阶次选的太大,很容易发生过拟合现象,即训练误差远小于测试(或者验证)误差。
4.5 自回归模型
自回归模型(Autoregressive model,简称AR模型),是统计上一种处理时间序列的方法,用同一变数例如 x 的之前各期,即 并假设它们为一线性关系。因为这是从回归分析中的线性回归发展而来,只是不是用 x 预测 y ,而是预测自己,所以叫做自回归。
广泛运用在经济学、信息学、自然现象的应用上。
如果一个时间序列 y_t 满足:
其中, 是独立同分布的随机变量序列,并且满足 则称时间序列 为服从p阶的自回归模型。令 自回归模型的平稳条件是滞后算子多项式
的根均在单位圆外,即
AR模型对偏自相关函数(PACF)截尾,对自相关函数(ACF)拖尾。所谓截尾指的是从某阶开始均为(接近)0的性质,拖尾指的是并不存在某一阶突然跳变到0而是逐渐衰减为0。
时间序列自相关与概率论中的相关定义本质是一致的,它衡量的是序列自身在不同时刻随机变量的相关性;偏自相关系数则剔除了两时刻之间其他随机变量的干扰,是更加纯粹的相关。
AR模型在金融模型中主要是对金融序列过去的表现进行建模,如交易中的动量与均值回归。
4.6 移动平均模型
MA模型(moving average model)滑动平均模型,模型参量法谱分析方法之一,也是现代谱估中常用的模型。
MA模型和AR大同小异,它并非是历史时序值的线性组合而是历史白噪声的线性组合。与AR最大的不同之处在于,AR模型中历史白噪声的影响是间接影响当前预测值的(通过影响历史时序值)。
如时间序列
满足
则称时间序列
服从 q 阶的移动平均模型。
MA模型对偏自相关函数(PACF)拖尾,对自相关函数(ACF)截尾。在金融模型中,MA常用来刻画冲击效应,例如预期之外的事件。
4.7 自回归移动平均模型
自回归滑动平均模型(ARMA 模型,Auto-Regressive and Moving Average Model)是研究时间序列的重要方法,由自回归模型(简称AR模型)与滑动平均模型(简称MA模型)为基础“混合”构成。在市场研究中常用于长期追踪资料的研究,如:Panel研究中,用于消费行为模式变迁研究;在零售研究中,用于具有季节变动特征的销售量、市场规模的预测等。
ARMA模型参数估计的方法很多:
- 如果模型的输入序列{ u_n }与输出序列{ a_n }均能被测量时,则可以用最小二乘法估计其模型参数,这种估计是线性估计,模型参数能以足够的精度估计出来;
- 许多谱估计中,仅能得到模型的输出序列{ x_n },这时,参数估计是非线性的,难以求得ARMA模型参数的准确估值。从理论上推出了一些ARMA模型参数的最佳估计方法,但它们存在计算量大和不能保证收敛的缺点。因此工程上提出次最佳方法,即分别估计AR和MA参数,而不像最佳参数估计中那样同时估计AR和MA参数,从而使计算量大大减少。
将预测指标随时间推移而形成的数据序列看作是一个随机序列,这组随机变量所具有的依存关系体现着原始数据在时间上的延续性。一方面,影响因素的影响,另一方面,又有自身变动规律,假定时间序列为 由回归分析,
误差项 在不同时期具有依存关系,由下式表示:
由此,获得ARMA模型表达式:
通常记为 ARMA(p,q) 模型。
4.8 差分自回归移动平均模型
ARIMA模型是在ARMA模型的基础上解决非平稳序列的模型,因此在模型中会对原序列进行差分,所谓的差分,也就是一个时间序列的当前值与前一个的值相减所得到的序列,如序列 它的一阶差分序列为 二阶差分是一节差分的差分,依次类推。直到得到一个平稳非白噪声差分序列,在这个序列的基础上进行ARMA分析。
4.9 自回归条件异方差模型
ARCH模型(Autoregressive conditional heteroskedasticity model,自回归条件异方差模型)将当前一切可利用信息作为条件,并采用某种自回归形式来刻画方差的变异,对于一个时间序列而言,在不同时刻可利用的信息不同,而相应的条件方差也不同,利用ARCH 模型,可以刻画出随时间而变异的条件方差。
ARCH模型的基本思想是指在以前信息集下,某一时刻一个噪声的发生是服从正态分布。该正态分布的均值为零,方差是一个随时间变化的量(即为条件异方差)。并且这个随时间变化的方差是过去有限项噪声值平方的线性组合(即为自回归)。这样就构成了自回归条件异方差模型。用数学公式表达其模型:
其中,y_t 为因变量,x_t 为自变量,\varepsilon_t 为误差项。误差项 \varepsilon_t 的平方服从AR§过程,即:
其中, 为条件异方差。 则称上述模型是自回归条件异方差模型,即ARCH模型。序列
ARCH模型通常对主体模型的随机扰动项进行建模分析。以便充分的提取残差中的信息,使得最终的模型残差 成为白噪声序列。
从上面的模型中可以看出,由于噪声的方差是过去有限项噪声值平方的回归,也就是说噪声的波动具有一定的记忆性,因此,如果在以前时刻噪声的方差变大,那么在此刻噪声的方差往往也跟着变大;如果在以前时刻噪声的方差变小,那么在此刻噪声的方差往往也跟着变小。体现到期货市场,那就是如果前一阶段期货合约价格波动变大,那么在此刻市场价格波动也往往较大,反之亦然。这就是ARCH模型所具有描述波动的集群性的特性,由此也决定它的无条件分布是一个尖峰胖尾的分布。
4.10 广义自回归条件异方差模型
GARCH(Generalized AutoRegressive Conditional Heteroskedasticity,广义自回归条件异方差模型)模型是一个专门针对金融数据所量体订做的回归模型,除去和普通回归模型相同的之处,GARCH对误差的方差进行了进一步的建模。特别适用于波动性的分析和预测,这样的分析对投资者的决策能起到非常重要的指导性作用,其意义很多时候超过了对数值本身的分析和预测。
GARCH模型形如ARCH:
其中,y_t 为因变量,x_t 为自变量,\varepsilon_t 为误差项。但是误差项 \varepsilon_t 的平方服从ARMA(p,q)过程,即:
其中, 为条件异方差。序列
由于GARCH (p,q)模型是ARCH模型的扩展,因此GARCH(p,q)同样具有ARCH(q)模型的特点。但GARCH模型的条件方差不仅是滞后残差平方的线性函数,而且是滞后条件方差的线性函数。
GARCH模型适合在计算量不大时,方便地描述了高阶的ARCH过程,因而具有更大的适用性。
5 数据分析
编程语言采用 Python3.5 ,需要安装相应的 Python 库。主要文件处理模块 xlwt,xlrd;科学计算模块 pandas ,numpy,scipy;算法库模块 stats,statsmodels;绘图模块 matplotlib 。
5.1 数据获取
数据从XX系统日志数据库XX 表中获取。获得的原始数据表形如下图:

汇总了 2017-1-3 至 2018-7-24 间的每日峰值时间、业务峰值、业务总量数据,导出为 Excel 文件形式。这些数据剔除了节假日和周末。
5.2 数据预处理
导出为 Excel 文件中数据可能会存在一些问题,比如可能存在如下问题:
- 数据重复的情况,如一天的数据可能重复好几次;
- 有些数据的值为 NULL ;
- 有些数据一天存在几个峰值的情况;
- 业务峰值数据或业务总量数量明显异常;
这些情况必须得先进行清理,针对具体的时间重查数据库,对明显错误的数据进行删除等等。经过初始的处理,会得到一份比较干净的数据。以这个 Excel 文件为例,读取数据的代码如下:
import xlwt
import xlrd
class tsa:
filename = ''
total = [] #业务总量 序列
day = [] #业务量对应的时间 序列
peek = [] #业务峰值 序列
peek_time = [] #业务峰值对应的时间 序列
sum = -1 #序列长度
#初始化函数
def __init__(self,path):
self.filename = path
#从原始 Excel 文件获取数据,如 total,day,peek,peek_time,sum.
def getData(self):
data = xlrd.open_workbook(self.filename)
table = data.sheets()[0]
nrows = table.nrows
ncols = table.ncols
self.sum = nrows - 1
for i in range(1,nrows):
self.total.append(table.col_values(5)[i])
# Excel 文件读取日期时需要进行特殊处理
date = xlrd.xldate_as_tuple(table.col_values(3)[i],0)
date0 = str(date[0]) + '-'
if date[1] < 10:
date0 = date0 + '0' + str(date[1]) + '-'
else:
date0 = date0 + str(date[1]) + '-'
if date[2] < 10:
date0 = date0 + '0' + str(date[2]) + ' '
else:
date0 = date0 + str(date[2]) + ' '
if date[3] < 10:
date0 = date0 + '0' + str(date[3]) + ':'
else:
date0 = date0 + str(date[3]) + ':'
if date[4] < 10:
date0 = date0 + '0' + str(date[4]) + ':'
else:
date0 = date0 + str(date[4]) + ':'
if date[5] < 10:
date0 = date0 + '0' + str(date[5])
else:
date0 = date0 + str(date[5])
date = xlrd.xldate_as_tuple(table.col_values(6)[i], 0)
date1 = str(date[0]) + '-'
if date[1] < 10:
date1 = date1 + '0' + str(date[1]) + '-'
else:
date1 = date1 + str(date[1]) + '-'
if date[2] < 10:
date1 = date1 + '0' + str(date[2])
else:
date1 = date1 + str(date[2])
self.day.append(date1)
#认为业务峰值在 10000 以下为异常
a = table.col_values(1)[i]
if a > 10000:
self.peek.append(a)
self.peek_time.append(date0)
def main(self):
self.getData()
if __name__ == '__main__':
path = '集中交易容量数据.xlsx'
tsa(path).main()
这样获取到我们所需的序列。例如 peek 的数据序列为:

5.3 分析原始数据特性
有了 peek 、total 列表,即有了业务峰值时间序列、业务总量时间序列,就可以进行一系列的分析了。
5.3.1 画时序图
首先,先观察序列的时序图;
import mpl_toolkits.axisartist.axislines as axislines
import pandas as pd
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.graphics.api import qqplot
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
#补充上面tsa中的函数
class tsa:
#业务峰值时序图
def sequence_diagram(self):
dta = pd.Series(self.peek)
dta.index = pd.Series(range(len(self.peek)))
dta.plot(figsize=(12, 8))
plt.title('业务峰值')
plt.show()
#业务总量时序图
def sequence_diagram_total(self):
dta = pd.Series(self.total)
dta.index = pd.Series(range(len(self.total)))
dta.plot(figsize=(12, 8))
plt.title('业务总量')
plt.show()
#执行流程
def main(self):
self.getData()
self.sequence_diagram_peek()
self.sequence_diagram_total()
#测试
if __name__ == '__main__':
path = '集中交易容量数据.xlsx'
tsa(path).main()
运行结果如下:


5.3.2 分析平稳性
从上面的时序图中大概可以看出业务峰值和业务总量的走势,并没有表现出明显的与时间关联的关系。假设这两个序列是与时间无关的具有弱平稳性的序列,为了验证这一想法,我们需要对这两个序列进行一阶差分分析。具体实施如下:
class tsa;
#业务峰值一阶差分时序图
def sequence_diagram_diff1_peek(self):
dta = pd.Series(self.peek)
dta.index = pd.Series(range(len(self.peek)))
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(111)
diff1 = dta.diff(1)
print(diff1.var()) #一阶差分后的方差
print(diff1.mean()) #一阶差分后的均值
diff1.plot(ax=ax1)
plt.title('业务峰值一阶差分')
plt.show()
# 业务总量一阶差分时序图
def sequence_diagram_diff1_total(self):
dta = pd.Series(self.total)
dta.index = pd.Series(range(len(self.total)))
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(111)
diff1 = dta.diff(1)
print(diff1.var()) #一阶差分后的方差
print(diff1.mean()) #一阶差分后的均值
diff1.plot(ax=ax1)
plt.title('业务总量一阶差分')
plt.show()
def main(self):
self.getData()
self.sequence_diagram_diff1_peek()
self.sequence_diagram_diff1_total()
if __name__ == '__main__':
path = '集中交易容量数据.xlsx'
tsa(path).main()
运行结果如下:


图中的业务峰值一阶差分序列与业务总量一阶差分序列能观测为一个类似白噪声序列,它们一阶差分后的均值接近为0,方差近视为一个常数,类似为一个随机游走模型。来通过求其自相关系数、偏自相关系数图验证这一想法,具体实施如下:
class tsa:
#求业务峰值一阶差分序列自相关,偏自相关滞后系数图
def acf_pacf_diff1_peek(self):
dta = pd.Series(self.peek)
dta = dta.diff(1) #求一阶差分
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(dta, lags=40, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(dta, lags=40, ax=ax2)
fig.suptitle('业务峰值')
plt.show()
#求业务总量一阶差分序列自相关,偏自相关滞后系数图
def acf_pacf_diff1_total(self):
dta = pd.Series(self.total)
dta = dta.diff(1) #求一阶差分
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(dta, lags=40, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(dta, lags=40, ax=ax2)
fig.suptitle('业务总量')
plt.show()
def main(self):
self.getData()
self.acf_pacf_diff1_peek()
self.acf_pacf_diff1_total()
if __name__ == '__main__':
path = '集中交易容量数据.xlsx'
tsa(path).main()
运行结果如下:


从图中可以看出业务峰值一阶差分序列与业务总量一阶差分序列的自相关与偏自相关系数均为0,意味着业务峰值一阶差分序列与业务总量一阶差分序是稳定的白噪声序列。因此,不能对业务峰值和业务总量进行差分分析,其本身就已经是一个弱平稳序列。
5.4 运用现存算法库分析
经过以上的分析,可以知道业务峰值序列与业务总量序列均是具有弱平稳性的序列。
5.4.1 自相关与偏自相关图
业务峰值序列与业务总量序列的自相关与偏自相关图的代码如下:
class tsa:
#求业务峰值序列自相关,偏自相关滞后系数图
def acf_pacf_peek(self):
dta = pd.Series(self.peek)
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(dta, lags=40, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(dta, lags=40, ax=ax2)
fig.suptitle('业务峰值')
plt.show()
#求业务总量一阶差分序列自相关,偏自相关滞后系数图
def acf_pacf_total(self):
dta = pd.Series(self.total)
fig = plt.figure(figsize=(12, 8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(dta, lags=40, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(dta, lags=40, ax=ax2)
fig.suptitle('业务总量')
plt.show()
def main(self):
self.getData()
self.acf_pacf_peek()
self.acf_pacf_total()
if __name__ == '__main__':
path = '集中交易容量数据.xlsx'
tsa(path).main()
运行如下:


从上图中,可以看出业务峰值序列自相关系数14阶拖尾,偏自相关系数4阶拖尾;业务总量序列自相关系数20阶拖尾,偏自相关系数5阶拖尾。
5.4.2 运用算法库模块分析业务峰值序列
使用现有的ARMA算法库来观察预测效果,该算法集成在 statsmodels.api 中,先进行对业务峰值序列的分析,具体实施如下:
classtsa:
def predict_ARMA_peek(self):
pred = [] #保存预测值
real = [] #保存对应实际值
resid = [] #保存残差
resid_abs = [] #保存平均误差率
#确定数据源
data = self.peek
#设定ARMA(p,q)的开始值,最大值
start_p = 0
start_q = 0
max_p = 15
max_q = 5
for p in range(start_p,max_p):
for q in range(start_q,max_q):
pred.clear()
real.clear()
resid.clear()
resid_abs.clear()
#表示从第350个数据开始进行预测
for i in range(350,len(data)):
l = data[:i]
dta = pd.Series(l)
dta.index = pd.Series(range(len(l)))
try:
arma_mod20 = sm.tsa.ARMA(dta, (p, q)).fit()
predict_sunspots = arma_mod20.predict(i , i, dynamic=True)
pred.append(predict_sunspots[i])
real.append(data[i])
resid.append(data[i] - predict_sunspots[i])
resid_abs.append(abs(data[i] - predict_sunspots[i]) / data[i])
except Exception:
break
else:
pass
#求平均误差率和均方误差
if len(resid) < 15:
continue
mean_square_error = 0
for element in resid:
mean_square_error = mean_square_error + element * element
mean_square_error = sqrt(mean_square_error / len(resid))
avr_err_rate = sum(resid_abs) / len(resid_abs)
#绘制相应的预测实际值对比图
x = range(len(pred))
y1 = real
y2 = pred
y3 = resid
fig = plt.figure(figsize=(12, 8))
plt.plot(x, y1, 'b', label='真实值')
plt.plot(x, y2, 'y', label='预测值')
plt.plot(x, y3, 'r', label='残差')
plt.legend()
name = '业务峰值-真实值/预测值对比图(ARMA(' + str(p) + ',' + str(q) + '))'
plt.title(name)
plt.text(10, 11000, r'平均误差率 = {:.4f}'.format(avr_err_rate))
plt.text(10, 8000, r'均方误差 = {:.1f}'.format(mean_square_error))
savepath = '基于ARMA(' + str(p) + ',' + str(q) + ')峰值预测'
plt.savefig(savepath)
def main(self):
self.getData()
self.predict_ARMA_peek()
if __name__ == '__main__':
path = '集中交易容量数据.xlsx'
tsa(path).main()
由于产生的图片会很多,这里只选取比较有意义的具有代表性的图片:





从上图中可以看出 ARMA(p,q)模型对业务峰值序列的预测平均误差率只能达到 18% 左右。p在9阶以后,平均误差率 基本上没有变过了,而且从平均误差率表现形式来看,与参数q无关。对于业务峰值序列来说,自相关性站主导地位。
5.4.3 运用算法库模块分析业务总量序列
具体实施如下:
class tsa:
def predict_ARMA_total(self):
pred = [] #保存预测值
real = [] #保存对应实际值
resid = [] #保存残差
resid_abs = [] #保存平均误差率
#确定数据源
data = self.total
#设定ARMA(p,q)的开始值,最大值
start_p = 0
start_q = 0
max_p = 21
max_q = 6
for p in range(start_p,max_p):
for q in range(start_q,max_q):
pred.clear()
real.clear()
resid.clear()
resid_abs.clear()
#表示从第350个数据开始进行预测
for i in range(350,len(data)):
l = data[:i]
dta = pd.Series(l)
dta.index = pd.Series(range(len(l)))
try:
arma_mod20 = sm.tsa.ARMA(dta, (p, q)).fit()
predict_sunspots = arma_mod20.predict(i , i, dynamic=True)
pred.append(predict_sunspots[i])
real.append(data[i])
resid.append(data[i] - predict_sunspots[i])
resid_abs.append(abs(data[i] - predict_sunspots[i]) / data[i])
except Exception:
break
else:
pass
#求平均误差率和均方误差
if len(resid) < 15:
continue
mean_square_error = 0
for element in resid:
mean_square_error = mean_square_error + element * element
mean_square_error = sqrt(mean_square_error / len(resid))
avr_err_rate = sum(resid_abs) / len(resid_abs)
#绘制相应的预测实际值对比图
x = range(len(pred))
y1 = real
y2 = pred
fig = plt.figure(figsize=(12, 8))
plt.plot(x, y1, 'b', label='真实值')
plt.plot(x, y2, 'y', label='预测值')
plt.legend()
name = '业务总量-真实值/预测值对比图(ARMA(' + str(p) + ',' + str(q) + '))'
plt.title(name)
plt.text(15, 4600000, r'平均误差率 = {:.4f}'.format(avr_err_rate))
plt.text(15, 4500000, r'均方误差 = {:.1f}'.format(mean_square_error))
savepath = '基于ARMA(' + str(p) + ',' + str(q) + ')总量预测'
plt.savefig(savepath)
def main(self):
self.getData()
self.predict_ARMA_total()
if __name__ == '__main__':
path = '集中交易容量数据.xlsx'
tsa(path).main()
运行结果图有很多,这里只展现几张比较具有代表性的对比图:



从图中可以看出,ARMA(p,q)模型参数p、q对业务总量序列都有不同程度的影响,说明业务总量数据既受自身变化影响,也受外部扰动影响,可以朝向将影响业务总量变化的因子量化,综合加权法对其进行建模。从ARMA(3,4) 以后,平均误差率收敛 9% ,以后几乎不怎么变动。
6 自定义模型
6.1 模型确定
依然采用自回归的思想,但与 ARMA 算法模块不同,假设有时间序列 { x_t } ,给出模型
可变形为
令 矩阵化有
其中
6.2 模型实现
TSA.py 文件具体实现了该算法。可以通过两个接口获取数据,即输入指定格式的 Excel 文件与列表形式。可以按参照选择最佳滞后期,可以预测下一个值。具体详尽解析见附录。
6.3 运用模型分析业务峰值序列
这里先实施一个测试用法,来测试这个模型。接前文,代码如下:
class tsa:
def mytrain_peek(self):
#设定滞后期的开始、最大值
lag_start = 1
lag_max = 21
for lag in range(lag_start,lag_max):
i = 0
real = [] #记录真实值
pred = [] #记录预测值
resid = [] #记录残差
err_rate = [] #记录预测误差
while i < len(self.peek) - 2 * lag:
x = [] #记录X矩阵
y = [] #记录Y矩阵
#生成X矩阵
for k in range(i,i+lag):
print('i:'+ str(i) + ' k:' +str(k))
x_k = self.peek[k:k+lag]
mean = sum(x_k)/len(x_k)
y.append(self.peek[k+lag] - mean)
x.append(x_k)
x = np.mat(x)
#求参数
x = np.linalg.inv(x)
y = np.mat(y).T
para = x * y
accu = 0
#参数归一化
for index in range(0,lag):
accu = accu + abs(para[index,0])
for index in range(0,lag):
para[index,0] = para[index,0] / accu
#求预测值
vec = self.peek[i+lag:i+2*lag]
u = sum(vec)/len(vec)
vec = np.mat(vec)
y = vec * para + u
y = y[0,0]
#从序列的第50个数据点开始进行预测
if (i+2*lag) >= 50:
real.append(self.peek[i+2*lag])
pred.append(y)
print('real: '+str(self.peek[i+ 2* lag]))
print('pred: '+str( y))
remain = self.peek[i+2*lag] - y
err = abs(remain) / self.peek[i+2*lag]
err_rate.append(err)
resid.append(remain)
i = i + 1
#求平均误差率、均方误差
mean_square_error = 0
for element in resid:
mean_square_error = mean_square_error + element * element
mean_square_error = sqrt(mean_square_error / len(resid))
avr_err_rate = sum(err_rate) / len(err_rate)
#绘制对比图
x = range(len(pred))
y1 = real
y2 = pred
y3 = resid
fig = plt.figure(figsize=(12, 8))
plt.plot(x, y1, 'b', label='真实值')
plt.plot(x, y2, 'y', label='预测值')
plt.plot(x, y3, 'r', label='残差')
plt.legend()
name = '真实值/预测值对比图(AR滞后' + str(lag)+ '阶)'
plt.title(name)
plt.text(150, 38000, r'平均误差率 = {:.4f}'.format(avr_err_rate))
plt.text(150, 35000, r'均方误差 = {:.1f}'.format( mean_square_error))
savepath = './基于AR预测图/' + '基于AR滞后' + str(lag)+ '阶预测'
plt.savefig(savepath)
def main(self):
self.getData()
self.mytrain_peek()
if __name__ == '__main__':
path = '集中交易容量数据.xlsx'
tsa(path).main()
抽出几张比较有代表性的结果图:




从图中可以看出,平均误差率从滞后数为9阶时开始收敛在 11% 左右,随着滞后数的增大,预测序列的波动性降低,逐渐变得平滑,这种情况应采取早停,即保证误差率的前提下,选取最小的滞后阶数。
6.4 运用模型分析业务总量序列
实施如下:
class tsa:
def mytrain_total(self):
#设定滞后期的开始、最大值
lag_start = 1
lag_max = 23
for lag in range(lag_start,lag_max):
i = 0
real = []
pred = []
resid = []
err_rate = []
while i < len(self.total) - 2 * lag:
x = []
y = []
for k in range(i,i+lag):
print('i:'+ str(i) + ' k:' +str(k))
x_k = self.total[k:k+lag]
mean = sum(x_k)/len(x_k)
y.append(self.total[k+lag] - mean)
x.append(x_k)
x = np.mat(x)
x = np.linalg.inv(x)
y = np.mat(y).T
para = x * y
accu = 0
for index in range(0,lag):
accu = accu + abs(para[index,0])
for index in range(0,lag):
para[index,0] = para[index,0] / accu
vec = self.total[i+lag:i+2*lag]
u = sum(vec)/len(vec)
vec = np.mat(vec)
y = vec * para + u
y = y[0,0]
if (i+2*lag) >= 50:
real.append(self.total[i+2*lag])
pred.append(y)
print('real: '+str(self.total[i+ 2* lag]))
print('pred: '+str( y))
remain = self.total[i+2*lag] - y
err = abs(remain) / self.total[i+2*lag]
err_rate.append(err)
resid.append(remain)
i = i + 1
mean_square_error = 0
for element in resid:
mean_square_error = mean_square_error + element * element
mean_square_error = sqrt(mean_square_error / len(resid))
avr_err_rate = sum(err_rate) / len(err_rate)
x = range(len(pred))
y1 = real
y2 = pred
y3 = resid
fig = plt.figure(figsize=(12, 8))
plt.plot(x, y1, 'b', label='真实值')
plt.plot(x, y2, 'y', label='预测值')
plt.plot(x, y3, 'r', label='残差')
plt.legend()
name = '真实值/预测值对比图(AR滞后' + str(lag)+ '阶)'
plt.title(name)
plt.text( 150,2500000,r'平均误差率 = {:.4f}'.format(avr_err_rate))
plt.text(150,3000000, r'均方误差 = {:.1f}'.format( mean_square_error))
savepath = './基于AR预测总量图/' + '基于AR滞后' + str(lag)+ '阶预测'
plt.savefig(savepath)
def main(self):
self.getData()
self.mytrain_total()
if __name__ == '__main__':
path = '集中交易容量数据.xlsx'
tsa(path).main()
运行结果如下:




业务总量序列应用该模型,可以发现,滞后阶数为20时,效果是最好的。平均误差率能达到 13% 。可以发现效果没有 ARMA 好。
6.5 小结
用同一个模型分析不同的时间序列,结果又很大不同,尽管业务峰值序列与业务总量序列都是弱平稳性的序列,适用的算法也不同。业务峰值序列的自相关性很强,即主要受本身的变化影响。业务总量数据既受自身变化影响,也受外部扰动影响。
7 展望
目前没有一种算法能够完美的适用任何一个时间序列,在时间序列分析中,需要多加尝试,针对不同的序列训练出合适的模型。以业务峰值序列和业务总量序列实验数据为例,可以尝试着对序列的方差进行建模,或者加入别的影响因素。
附录
自己写了个 AR_MODEL 算法,源码及用法详解如下:
# -*- coding=utf8 -*-
import numpy as np
import xlwt
import xlrd
from pylab import *
#自定义分析,回归模型:Y = c + βX + φ
'''
数据可以Excel表中获取,这个需要文件路径;也可以输入list
表格形式:
A B
业务峰值时间 业务量峰值
2017/1/3 9:38 27251
... ...
或者,
A B
数据入库时间 业务总量
2017/1/3 16:00 5376472
... ...
用法:
第一步:
xls_file_path = '' #给出文件路径名
或者,
raw = [](输入list)
//调用相应函数
data = AR_MODEL().get_data_by_list(raw)
或者,
data = AR_MODEL().get_data_by_xls_file(xls_file_path)
第二步:
//寻找最优滞后期,optimum_lag()需要三个参数,
*第一个参数,是一个数据列表
*第二个参数,lag开始值,默认为1
*第三个参数,lag最大值,默认为23
//输出
*是一个值,lag,即最佳滞后期
//可以设置参数指定滞后期的范围,如optimum_lag(data,1,15)
lag = AR_MODEL().optimum_lag(data,1,23) #
第三步:
#fit()是预测函数,有两个参数
*第一个参数,是一个数据列表
*第二个参数,滞后期lag,默认为5
//输出
*第一个输出值,预测值
*第二个输出值,波动范围
//可以指定一个滞后期,不指定默认为5,如fit(data,lag)
average_err_rate,scope = AR_MODEL().fit(lag,14)
'''
class AR_MODEL:
rawdata = [] #原始数据,list形式
time_stamp = [] #记录对应的时间点
#lag = 5 默认为5,建议5-20之间
def __init__(self):
self.rawdata = []
#通过外部list传入数据
def get_data_by_list(self,raw):
self.rawdata = raw
return raw
#从Excel文件获取,Excel格式如下
'''
A B
业务峰值时间 业务量峰值
2017/1/3 9:38 27251
... ...
'''
#或者如下形式
'''
A B
数据入库时间 业务总值
2017/1/3 16:00 5376472
... ...
'''
def get_data_by_xls_file(self,xls_file_path):
data = xlrd.open_workbook(xls_file_path)#打开Excel
table = data.sheets()[0] #获取Excel第一个表
rawdata = [] #取Excel数据值
time = [] #取Excel时间值
nrows = table.nrows
#读取Excel表中数据
for i in range(1, nrows):
#取第二列值,即数据值
rawdata.append(table.col_values(1)[i])
#取时间戳
date = xlrd.xldate_as_tuple(table.col_values(0)[i], 0)
date0 = str(date[0]) + '-'
if date[1] < 10:
date0 = date0 + '0' + str(date[1]) + '-'
else:
date0 = date0 + str(date[1]) + '-'
if date[2] < 10:
date0 = date0 + '0' + str(date[2]) + ' '
else:
date0 = date0 + str(date[2]) + ' '
if date[3] < 10:
date0 = date0 + '0' + str(date[3]) + ':'
else:
date0 = date0 + str(date[3]) + ':'
if date[4] < 10:
date0 = date0 + '0' + str(date[4]) + ':'
else:
date0 = date0 + str(date[4]) + ':'
if date[5] < 10:
date0 = date0 + '0' + str(date[5])
else:
date0 = date0 + str(date[5])
time.append(date0)
self.rawdata = rawdata
self.time_stamp = time
return rawdata
#寻找最佳滞后期,这里是给出个建议,默认是从1到23
def optimum_lag(self,data,start_lag = 1,end_lag = 23):
data = data #获取要分析的日志
#默认lag 起止
start_lag = start_lag
end_lag = end_lag
#从共同的一个起点开始预测
threshold = end_lag * 2
#记录平均误差率,均方误差
average_error = []
standard_deviation = []
#保证数据充足,用来训练最佳滞后期lag
if len(data) < 60:
print("请保证数据充足:长度至少60...")
return
#分别测试每个lag取值
for lag in range(start_lag, end_lag):
i = 0
real = [] #记录真实值
pred = [] #记录预测值
resid = [] #记录残差
err_rate = [] #记录预测误差
#数据从0开始,总共 len(data) - 2 * lag 轮,每一轮可以得到一个预测值,
# 从第threshold个数据点开始记录预测值,残差,误差率
while i < len(data) - 2 * lag:
x = [] #记录X矩阵
y = [] #记录Y矩阵
#生成X矩阵
for k in range(i, i + lag):
x_k = data[k:k + lag] #截取每一轮中,长度为lag的列表,作为x矩阵中的一行,
mean = sum(x_k) / len(x_k) #计算均值
y.append(data[k + lag] - mean) #生成y
x.append(x_k)
x = np.mat(x) #得到X矩阵
x = np.linalg.inv(x) #得到X的逆矩阵
y = np.mat(y).T #得到Y矩阵
para = x * y #得到参数β矩阵
#将β矩阵归一化,约束β范围
accu = 0
for index in range(0, lag):
accu = accu + abs(para[index, 0])
for index in range(0, lag):
para[index, 0] = para[index, 0] / accu
vec = data[i + lag:i + 2 * lag] #取下一组序列,用于预测data[i+2*lag]
u = sum(vec) / len(vec) #得到该序列均值
vec = np.mat(vec) #将序列矩阵化
y = vec * para + u #得到data[i+2*lag]对应的预测值
y = y[0, 0] #转化为实数形式
#预测评估,这里threshold保证所有lag都能以一个共同的时间点来进行预测,方便分析
if (i + 2 * lag) >= threshold:
real.append(data[i + 2 * lag])
pred.append(y)
remain = data[i + 2 * lag] - y
err = abs(remain) / data[i + 2 * lag]
err_rate.append(err)
resid.append(remain)
i = i + 1 #进行下一轮
#计算误差率,均方误差
mean_square_error = 0
#统计误差和
for element in resid:
mean_square_error = mean_square_error + element * element
mean_square_error = int(sqrt(mean_square_error / len(resid))) #记录标准差
avr_err_rate = sum(err_rate) / len(err_rate) #记录平均误差率
avr_err_rate = float('%.4f' % avr_err_rate) #平均误差率保留4位小数
average_error.append(avr_err_rate) #加入每个lag对应的误差率
standard_deviation.append(mean_square_error) #加入每个lag对应的均方误差
min_err = max(average_error) #记录最小平均误差率
min_std_deviation = max(standard_deviation) #记录最小偏差
lag = 5 # 默认为5
print("滞后期----平均误差率----均方误差")
#寻找最小平均误差率
for i in range(0,len(average_error)):
print(str(i+1) + " ---- " + str(average_error[i]) + " ---- " + str(standard_deviation[i]))
if min_err > average_error[i] and min_std_deviation > standard_deviation[i]:
min_err = average_error[i]
min_std_deviation = standard_deviation[i]
lag = i+1 #记录对应的滞后期,默认输出5
return lag
#根据给定的数据和滞后期lag,预测下一日峰值或业务总量
def fit(self,data,lag=5):
#获取lag
lag = lag
#获取rawdata
raw = data
if len(raw) < lag * 2 :
print("索引错误:原始训练数据不充足!")
return
#截取所需的训练集
data = raw[len(raw)-2*lag:]
#Y = c + βX + φ
x = [] #记录X矩阵
y = [] #记录Y矩阵
# 生成X矩阵
for k in range(0,lag):
x_k = data[k:k+lag] #截取每一轮中,长度为lag的列表,作为x矩阵中的一行,
mean = sum(x_k)/len(x_k) #计算均值
y.append(data[k+lag] - mean) #记录y
x.append(x_k)
x = np.mat(x) #转化成X矩阵
x = np.linalg.inv(x) # 求取X的逆矩阵
y = np.mat(y).T #生成Y
#求参数
para = x * y
# 约束参数值,使得β的所有值的绝对值之和为1
accu = 0
for index in range(0,lag):
accu = accu + abs(para[index,0])
for index in range(0,lag):
para[index,0] = para[index,0] / accu
#预测
vec = data[len(data)-lag:] #截取带预测日期前lag值
u = sum(vec)/len(vec) #计算均值
vec = np.mat(vec) #转化成矩阵
pred = vec * para + u #得到预测值
pred = pred[0,0]
pred = int(round(pred)) #转化成整数形式
print("预测值: "+str(pred))
#计算标准差
mean_square = 0
for i in range(0,lag):
mean_square = mean_square + (data[i] - u) * (data[i] - u)
mean_square = int(sqrt(mean_square / 5)) #标准误差取整
print("波动范围: "+ str(mean_square))
return pred,mean_square
#测试用法
if __name__ == '__main__':
xls_file_path = '集中交易容量数据.xlsx' #给出文件路径名
#2017-1-3 到 2018-7-24,每日峰值量,已去除节假日、周末,做测试用
raw = [27251.0, 26717.0, 30245.0, 27963.0, 25697.0, 27731.0, 26374.0, 26900.0, 24413.0, 26560.0, 22009.0, 22238.0,
24487.0, 22987.0, 22571.0, 22767.0, 21310.0, 21463.0, 23148.0, 22485.0, 26172.0, 25914.0, 28646.0, 30707.0,
29215.0, 27863.0, 26525.0, 24021.0, 24725.0, 23209.0, 31023.0, 28265.0, 31189.0, 29609.0, 29322.0, 28209.0,
28344.0, 31319.0, 30494.0, 31863.0, 31665.0, 32085.0, 30374.0, 28671.0, 27498.0, 26802.0, 27704.0, 31611.0,
28917.0, 31877.0, 29527.0, 27971.0, 32085.0, 29144.0, 31287.0, 28530.0, 29110.0, 29968.0, 31056.0, 36020.0,
35933.0, 27879.0, 32470.0, 32549.0, 38254.0, 34091.0, 33464.0, 33187.0, 30227.0, 28731.0, 27622.0, 28050.0,
28389.0, 21466.0, 27375.0, 27296.0, 27152.0, 28726.0, 27052.0, 27507.0, 26946.0, 27448.0, 26414.0, 23424.0,
27197.0, 24679.0, 28341.0, 23654.0, 31066.0, 31734.0, 25228.0, 24870.0, 26118.0, 24124.0, 26486.0, 21144.0,
32012.0, 23694.0, 24055.0, 26495.0, 19063.0, 25417.0, 24833.0, 29465.0, 28380.0, 23439.0, 21338.0, 25189.0,
23053.0, 26135.0, 27562.0, 29062.0, 27840.0, 26344.0, 22162.0, 21110.0, 24984.0, 18730.0, 23413.0, 23039.0,
23359.0, 26367.0, 28051.0, 25927.0, 24013.0, 24553.0, 24013.0, 26191.0, 27051.0, 28646.0, 26791.0, 24547.0,
23995.0, 25408.0, 29586.0, 26554.0, 28918.0, 28863.0, 27462.0, 28765.0, 30800.0, 27581.0, 30731.0, 28984.0,
28780.0, 26015.0, 29781.0, 27530.0, 30755.0, 27965.0, 27593.0, 29866.0, 30447.0, 29761.0, 29888.0, 31521.0,
29895.0, 30475.0, 29866.0, 29901.0, 29857.0, 28957.0, 28954.0, 28944.0, 32505.0, 30159.0, 33440.0, 31796.0,
32333.0, 33642.0, 29172.0, 30623.0, 26129.0, 30485.0, 30606.0, 25123.0, 28974.0, 30362.0, 29431.0, 30049.0,
29874.0, 31469.0, 30145.0, 22710.0, 29913.0, 24943.0, 21283.0, 29188.0, 28906.0, 26745.0, 27151.0, 24589.0,
25216.0, 29198.0, 29824.0, 23782.0, 27468.0, 28608.0, 26440.0, 26238.0, 24421.0, 29890.0, 29451.0, 31194.0,
27442.0, 26204.0, 28901.0, 30121.0, 24972.0, 26118.0, 25902.0, 27635.0, 29354.0, 27707.0, 22875.0, 22731.0,
23778.0, 22797.0, 27879.0, 22951.0, 25489.0, 24018.0, 23139.0, 26355.0, 19207.0, 17232.0, 18606.0, 24007.0,
22235.0, 21320.0, 22509.0, 21672.0, 21862.0, 23344.0, 18451.0, 22896.0, 25272.0, 23354.0, 25325.0, 20555.0,
21660.0, 28860.0, 30495.0, 28137.0, 27995.0, 25880.0, 27174.0, 29724.0, 29771.0, 28095.0, 29938.0, 31797.0,
21717.0, 27479.0, 26073.0, 29464.0, 30759.0, 33896.0, 32510.0, 32523.0, 28422.0, 30080.0, 26041.0, 25126.0,
27347.0, 18777.0, 36673.0, 25806.0, 31062.0, 20852.0, 24706.0, 18605.0, 24087.0, 20851.0, 29028.0, 26465.0,
22101.0, 22960.0, 28293.0, 24615.0, 24214.0, 28207.0, 21087.0, 28456.0, 30322.0, 29716.0, 35196.0, 22171.0,
27695.0, 26090.0, 25370.0, 32490.0, 31095.0, 36962.0, 27569.0, 30693.0, 32679.0, 32692.0, 31224.0, 32899.0,
33088.0, 35149.0, 32658.0, 24899.0, 32450.0, 27485.0, 24149.0, 30094.0, 29539.0, 37429.0, 29944.0, 28322.0,
28394.0, 32678.0, 29712.0, 29357.0, 28383.0, 24415.0, 23567.0, 19505.0, 30242.0, 28343.0, 29090.0, 28976.0,
27974.0, 31820.0, 26901.0, 30182.0, 24881.0, 24301.0, 29006.0, 11390.0, 27865.0, 28138.0, 26307.0, 28655.0,
25423.0, 32968.0, 29075.0, 26463.0, 28286.0, 24897.0, 19745.0, 28360.0, 23802.0, 19307.0, 26691.0, 27378.0,
20194.0, 24195.0, 18742.0, 21582.0, 25460.0, 18630.0, 28673.0, 26857.0, 20925.0, 16085.0, 26550.0, 18885.0,
14663.0, 23892.0, 21050.0, 24809.0, 21171.0, 24756.0, 19726.0, 20202.0, 25989.0, 17613.0, 24834.0, 25543.0,
21784.0, 17465.0, 23760.0, 25341.0]
#数据可以Excel表中获取,这个需要文件路径;也可以输入list,选择一个
data = AR_MODEL().get_data_by_list(raw)
#data = AR_MODEL().get_data_by_xls_file(xls_file_path)
#寻找最优滞后期,optimum_lag()可以设置参数指定滞后期的范围,如optimum_lag(data,1,15)
lag = AR_MODEL().optimum_lag(data) #
#fit()可以指定一个滞后期,不指定默认为5
average_err_rate,scope = AR_MODEL().fit(data,lag)
