1.数据抽取
本案列抽取的是2014-10-01到2014-11-16财务管理系统中某台服务器的磁盘的相关数据。在此要检验discdata.xls是否符合提取的要求。
import pandas as pd
import datetime
from pandas import Series
data=pd.read_excel(r'D:\file\book_pythonDADM\chapter11\demo\data\discdata.xls')
((data['COLLECTTIME']>=datetime.datetime.strptime('2014-10-01','%Y-%m-%d'))&(data['COLLECTTIME']<=datetime.datetime.strptime('2014-11-16','%Y-%m-%d'))).value_counts()
(data['SYS_NAME']=='财务管理系统').value_counts() #计数值从结果可以看出数据是符合要求的。
2.数据探索分析
由于本案例是采用时间序列分析法进行建模的,故可以通过时序图来观测序列的平稳性。
data_c=data[(data['DESCRIPTION']=='磁盘已使用大小')&(data['ENTITY']=='C:\\')]['VALUE']
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文标签
plt.plot(data_c,'b-o')
plt.title(u'C盘使用情况')
plt.show()
data_d=data[(data['DESCRIPTION']=='磁盘已使用大小')&(data['ENTITY']=='D:\\')][['VALUE','COLLECTTIME']]
plt.plot(data_d['VALUE'],'b-o')
plt.title(u'D盘使用情况')
plt.show()得到如下结果图。
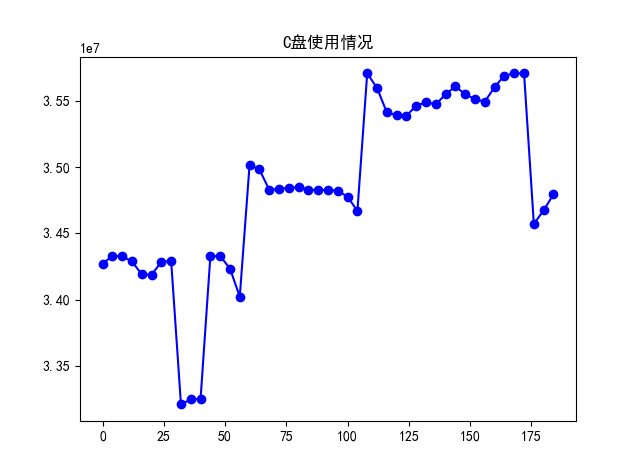
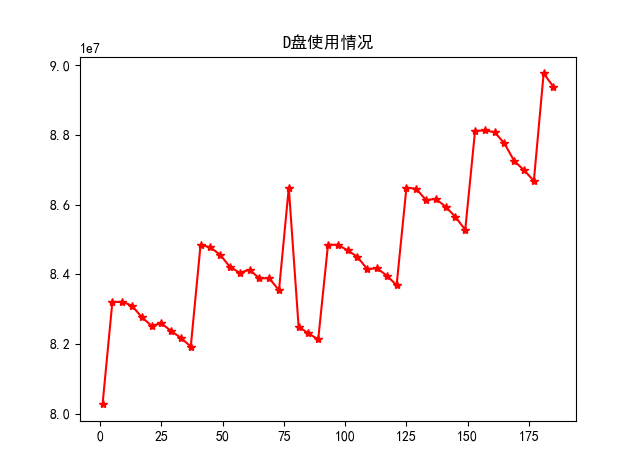
因此,可以初步确认数据是平稳的。
3.数据预处理
3.1数据清理
from pandas import DataFrame
cipan=DataFrame([['财务管理系统','CWXT_DB',183,'磁盘容量','C:\\',data[(data['DESCRIPTION']=='磁盘容量')&(data['ENTITY']=='C:\\')].iloc[0,-2]],
['财务管理系统','CWXT_DB',183,'磁盘容量','D:\\',data[(data['DESCRIPTION']=='磁盘容量')&(data['ENTITY']=='D:\\')].iloc[0,-2]]],
columns=['SYS_NAME','NAME','TARGET_ID','DESCRIPTION','ENTITY','VALUE']) #磁盘容量表3.2属性构造
import pandas as pd
from pandas import DataFrame
import numpy as np
data=pd.read_excel(r'D:\file\book_pythonDADM\chapter11\demo\data\discdata.xls')
data1=data[~(data['TARGET_ID']==183)] #删除属性号为183的数据
import datetime
delta2=data.iloc[-1,-1]-data.iloc[0,-1]
delta2.days #delta2的取值是时间间隔Timedelta,而我们所需要的是天数的具体值
data3=DataFrame({'CWXT_DB:184:C:\\':np.arange(1.0,1.0+delta2.days*0.2+0.1,0.2),
'CWXT_DB:184:D:\\':np.arange(1.0,1.0+delta2.days*0.3+0.1,0.3),
'COLLECTTIME': pd.date_range(start=data.iloc[0, -1], periods=47)})
data3['SYS_NAME']='财务管理系统'
for i in range(0,47):
data3.loc[i, 'CWXT_DB:184:C:\\'] = list(data1[(data1['NAME'] == 'CWXT_DB')&(data1['TARGET_ID'] == 184)&(data1['ENTITY'] == 'C:\\')
&( data1['COLLECTTIME'] == datetime.datetime.strptime('2014-10-01','%Y-%m-%d')+datetime.timedelta(i))]['VALUE'])[0]
data3.loc[i, 'CWXT_DB:184:D:\\'] = list(data1[(data1['NAME'] == 'CWXT_DB')&(data1['TARGET_ID'] == 184)&(data1['ENTITY'] == 'D:\\')
&( data1['COLLECTTIME'] == datetime.datetime.strptime('2014-10-01','%Y-%m-%d')+datetime.timedelta(i))]['VALUE'])[0]
data3.to_excel(r'D:\file\book_pythonDADM\chapter11\demo\data\discdata_processed_ly.xls')4.模型构建
4.1平稳性检验
import pandas as pd
data=pd.read_excel(r'D:\file\book_pythonDADM\chapter11\demo\data\discdata_processed_ly.xls')
data=data.iloc[:len(data)-5] #不使用最后5个数据
#平稳性检测
from statsmodels.tsa.stattools import adfuller as ADF
diff=0
adf=ADF(data['CWXT_DB:184:D:\\'])
while adf[1]>=0.05:
diff=diff+1
adf=ADF(data['CWXT_DB:184:D:\\'].diff(diff).dropna())
print(u'原始序列经过%s阶差分后归于平稳,p值为%s'%(diff,adf[1])) #adf[1]为p值,p值小于0.05认为是平稳的。4.2白噪声检验
import pandas as pd
data=pd.read_excel(r'D:\file\book_pythonDADM\chapter11\demo\data\discdata_processed_ly.xls')
data=data.iloc[:len(data)-5]
#白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
[[lb],[p]]=acorr_ljungbox(data['CWXT_DB:184:D:\\'],lags=1)
if p<0.05:
print(u'原始序列为非白噪声序列,对应的p值为:%s'%p)
else:
print(u'原始序列为白噪声序列,对应的p值为:%s'%p)
[[lb],[p]]=acorr_ljungbox(data['CWXT_DB:184:D:\\'].diff().dropna(),lags=1)
if p<0.05:
print(u'原始序列为非白噪声序列,对应的p值为:%s'%p)
else:
print(u'原始序列为白噪声序列,对应的p值为:%s'%p)4.3模型识别
import pandas as pd
import numpy as np
data=pd.read_excel(r'D:\file\book_pythonDADM\chapter11\demo\data\discdata_processed_ly.xls')
data=data.iloc[:len(data)-5]
xdata=data['CWXT_DB:184:D:\\']
xdata.index=data['COLLECTTIME']
from statsmodels.tsa.arima_model import ARIMA
#定阶
pmax=int(len(xdata)/10) #一般阶数不超过length/10
qmax=int(len(xdata)/10) #一般阶数不超过length/10
bic_matrix=[] #bic矩阵
for p in range(pmax+1):
tmp=[]
for q in range(qmax+1):
try: #存在部分报错,所以用try来跳过报错
tmp.append(ARIMA(xdata,(p,1,q)).fit().bic)
except:
tmp.append(None)
bic_matrix.append(tmp)
#print('bic_matrix的输出结果为:',bic_matrix)
bic_matrix=pd.DataFrame(bic_matrix) #从中可以找出最小值
p,q=bic_matrix.replace(np.NaN,99999).stack().idxmin() #先用stack展平,然后用idxmin找出最小值的索引位置%%%stack将数据的列“旋转”为行
print(u'BIC最小的p值和q值为:%s %s'%(p,q))4.4模型检验
import pandas as pd
data=pd.read_excel(r'D:\file\book_pythonDADM\chapter11\demo\data\discdata_processed_ly.xls',index_col=0) #index_col的作用是,选取文件中的第1列作为DataFrame的索引值
#help(函数名),可以查看函数的定义,如help(pd.read_excel),可知参数index_col只能取整,或者是整数列表。
data2=data[:len(data)-5]
xdata=data2['CWXT_DB:184:D:\\']
lagnum=12 #残差延迟个数
from statsmodels.tsa.arima_model import ARIMA #建立ARIMA(0,1,1)模型
arima=ARIMA(xdata,order=(1,1,1)).fit() #建立并训练模型
xdata_pred=arima.predict(typ='levels') #预测
pred_corr=(xdata_pred-xdata).dropna() #计算残差
from statsmodels.stats.diagnostic import acorr_ljungbox #白噪声检验
lb,p=acorr_ljungbox(pred_corr,lags=lagnum)
h=(p<0.05).sum() #p值小于0.05,认为是非白噪声
if h>0:
print(u'模型ARIMA(1,1,1)不符合白噪声检验')
else:
print(u'模型ARIMA(1,1,1)符合白噪声检验')4.5模型预测
y_pred=arima.forecast(5)[0]/(1024**2)
XPredict=pd.DataFrame([],columns=['y_pred','y'],index=data.index[-5:])
XPredict['y_pred']=y_pred
XPredict['y']=data.iloc[len(data)-5:,1]/(1024**2)
XPredict.to_excel(r'D:\file\book_pythonDADM\chapter11\demo\data\predictdata_ly.xls')
4.6模型评价(平均绝对误差,均方根误差,平均绝对百分误差)
import pandas as pd
data=pd.read_excel(r'D:\file\book_pythonDADM\chapter11\demo\data\predictdata_ly.xls')
abs_=(data['y_pred']-data['y']).abs()
mae_=abs_.mean() #平均绝对误差
rmse_=((abs_**2).mean())**0.5 #均方根误差
mape_=(abs_/data['y']).mean() #平均绝对百分误差
print(u'平均绝对误差:%0.4f,\n均方根误差:%0.4f,\n平均绝对百分比误差:%0.6f'%(mae_,rmse_,mape_))5模型应用
将预测值与磁盘的总容量进行比较,预测磁盘的使用率,进行预警设置。