文章目录
概念
概览表
| 名词 | 解释 |
|---|---|
| 句型 | 从文法开始符号S开始,每步推导(包括0步推导)所得到的字符串 |
| 句子 | 仅含终结符的句型 |
| 语言 | 由S推导所得的句子的集合 ,G为文法 |
推导和规约
- 推导:使用产生式的右部取代左部的过程, 最左推导和最右推导称为规范推导。

- 归约:推导的逆过程,用产生式的左部取代右部的过程 -,最左归约和最右归约称为规范归约

Chomsky 0型文法: 短语文法或无限制文法
- ,其中 并至少含有一个非终结符, .
- 是对产生式限制最少的文法;
- 对0型文法的产生式作某些限制,可以得到其他类型的 文法
- 识别0型语言的自动机称为图灵机 ™
Chomsky 1型文法: 长度增加文法/上下文有关文法)
- ,除可能有 外均有 ;若有 ,规定S不 得出现在产生式右部。或
- P中产生式 ,除可能有 外均有 ,其中 , ,
- 1型文法对非终结符进行替换时必须考虑上下文
- 除文法开始符号外不允许将其它的非终结符替换成
- 识别1型语言的自动机称为线性界限自动机(LBA)
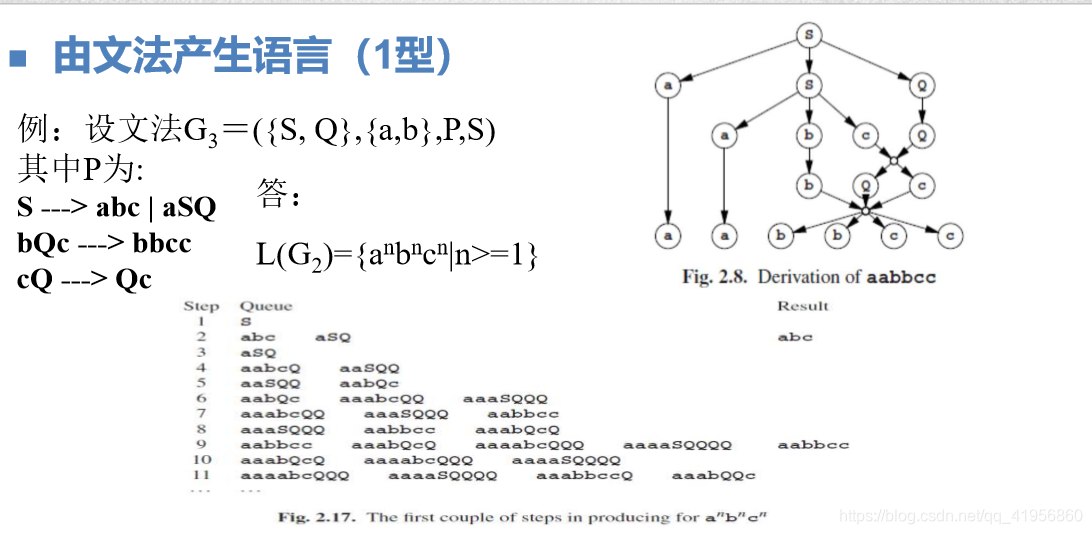
Chomsky 2型文法: content-free grammer(CFG )
特点:
- ,其中 , 。
- 所有的产生式左边只有一个非终结符,产生式右部可以是VN 、VT或
- 非终结符的替换不必考虑上下文,故也称作上下文无关文法。
- 识别2型语言的自动机称为下推自动机(PDA)。
从推导的角度看,语法分析的任务是
- 接受一个终结符号串作为输入,找出从文法的开始符号推导出这 个串的方法
Chomsky 3型文法:正则文法 (FSG)
- 定义
- P中产生式具有形式 , (右线性),或者 , (左 线性), 其中 。
- 也称为正规文法RG、线性文法:若所有产生式均是左线性,则称为左线 性文法;若所有产生式均是右线性,则称为右线性文法。
- 产生式要么均是右线性产生式,要么是左线性产生式,不能既有左线性 产生式,又有右线性产生式
-
正则表达式(regular expressions, RE) 是 定义正则语言(regular languages, RL)的标准工具 ,正则表达式和正则文法等价,可以互相转化
-
其定义的集合叫做正则集合(regular set) , 是词法单元的规约
-
识别3型语言的自动机称为有限状态自动机(FA)。
例:
- L(a(a|b)*) = {a,aa,ab,aaa, aab,aba,abb,aaaa, aaab,…}
语法分析器
- 输入:词法分析器输出的词法单元序列
- 输出:语法树表示 -
- 功能:
- 验证输入源程序的合法性,输出良构程序的语法结构
- 对于病构的程序,能够报告语法错误,进行错误恢复
- 类型:
- 通用型
- 自顶向下:通常处理LL文法
- 自底向上:通常处理LR文法
解析树(Parsing Tree),即语法分析树(syntax analysis tree)
子问题
从起始符通过推导变成句子
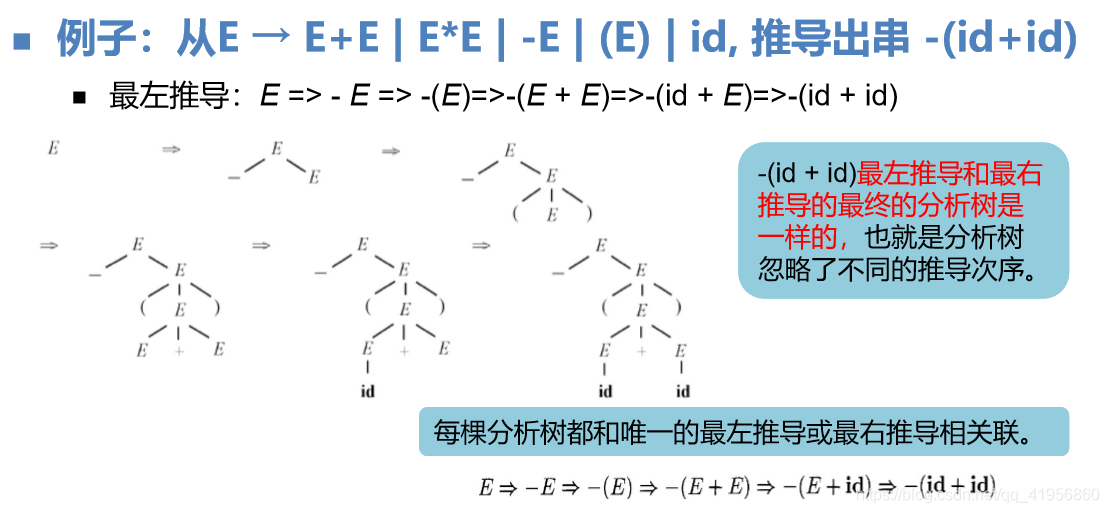
判断二义性
- 如果一个文法可以为一个句子生成多棵不同的语法分析树, 则该文法为二义性文法
- 若最左推导和最右推导语法分析树不同,则有二义性
消除二义性
- 规定符号的优先级
- 规定符号的结合性
例1:

- 左结合:让它只能往左拓展,
- 消除优先级(*优先):引入T承担*的任务。
例2:

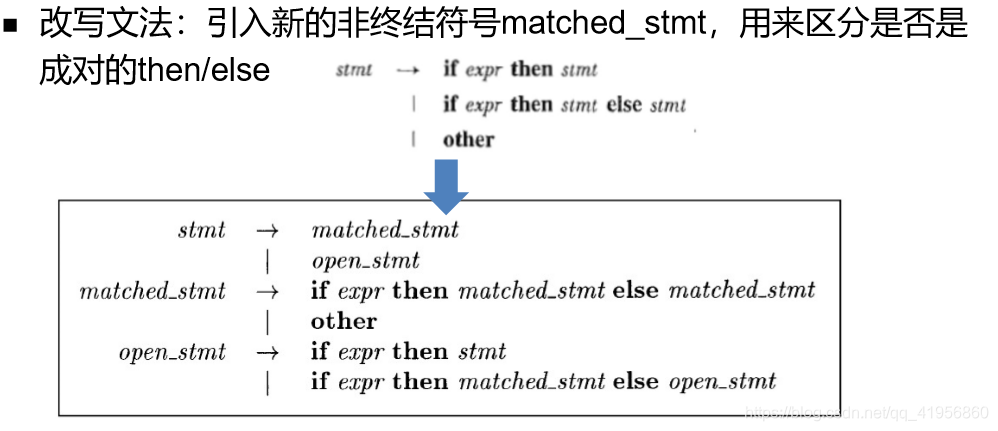
语法错误处理
- Panic Mode
当检测到一个语法错误时, 丢掉一些token,直到遇到一些具有清晰分隔作用的符号; 然后从该符号处开始分析。 这些符号称为“同步符号”,一般地为语句或表达式的结束符,如c语言中的分号。
例:
对于下面错误的表达式
Panic mode 恢复:
- 当语法分析遇到第二个“+”时,跳到下一整数2处继续分析。
- 这种恢复方式可以通过在文法中增加一个特殊的终极符error实现: , 这样,当识别到错误,可以跳过错误继续往下分析。
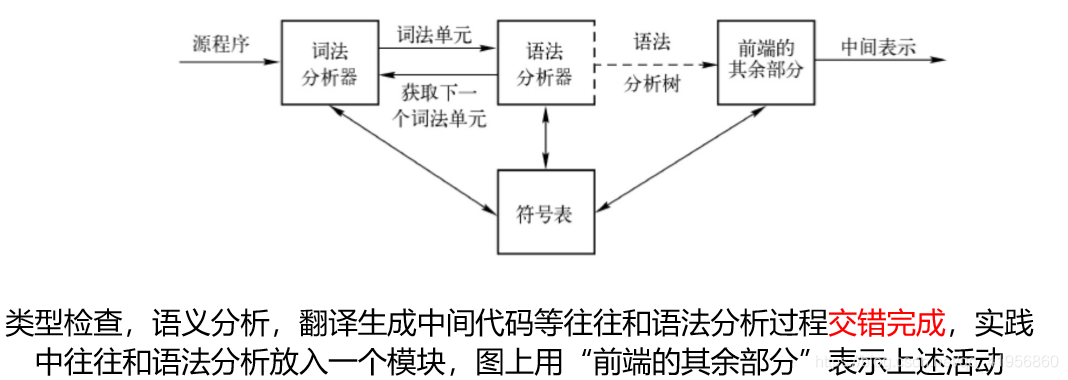
工作流