Fully-Convolutional Siamese Networks for Object Tracking論文研讀與問題討論
前言
本篇是目標跟蹤領域SiamRPN系列的首篇論文。
online-only method->模型的表現能力不足。
利用DNN來學習更豐富的特徵->需在線更新網路權重,速度會受到嚴重影響。
本篇用fully-convolutional siamese network + 基礎的目標跟蹤算法,可以得到SOTA的結果。
(1)背景介紹
- online-only method:TLC,Struck,KCF。
- deep conv-net + shallow methods(如:correlation filter):無法進行端到端的訓練。
- 微調DNN的後面幾層:無法實時運行。
本篇的作法為線下similarity learning+線上目標跟蹤。
線下:訓練一個孿生網路,用來從一張大的search image裡找出exemplar image。
線上:“在search image上使用滑動視窗尋找exemplar image”的步驟被“一個計算兩輸入間互相關(cross-correlation)的雙線性層(bilinear layer)”所取代。
模型泛化能力好:在ImageNet上訓練好的模型在其它數據集,如:ALOV/OTB/VOC上一樣適用。
(2)使用DNN學習相似度並用於目標跟蹤
線下相似度學習的目標是要學習一個函數 。
其輸入是一對相同大小的圖片。z表示exemplar image,x表示candidate image。這個函數用來衡量它們的相似程度。
寫得更具體一點, ,其中 代表某種embedding方式,而 則代表一種similarity metric。
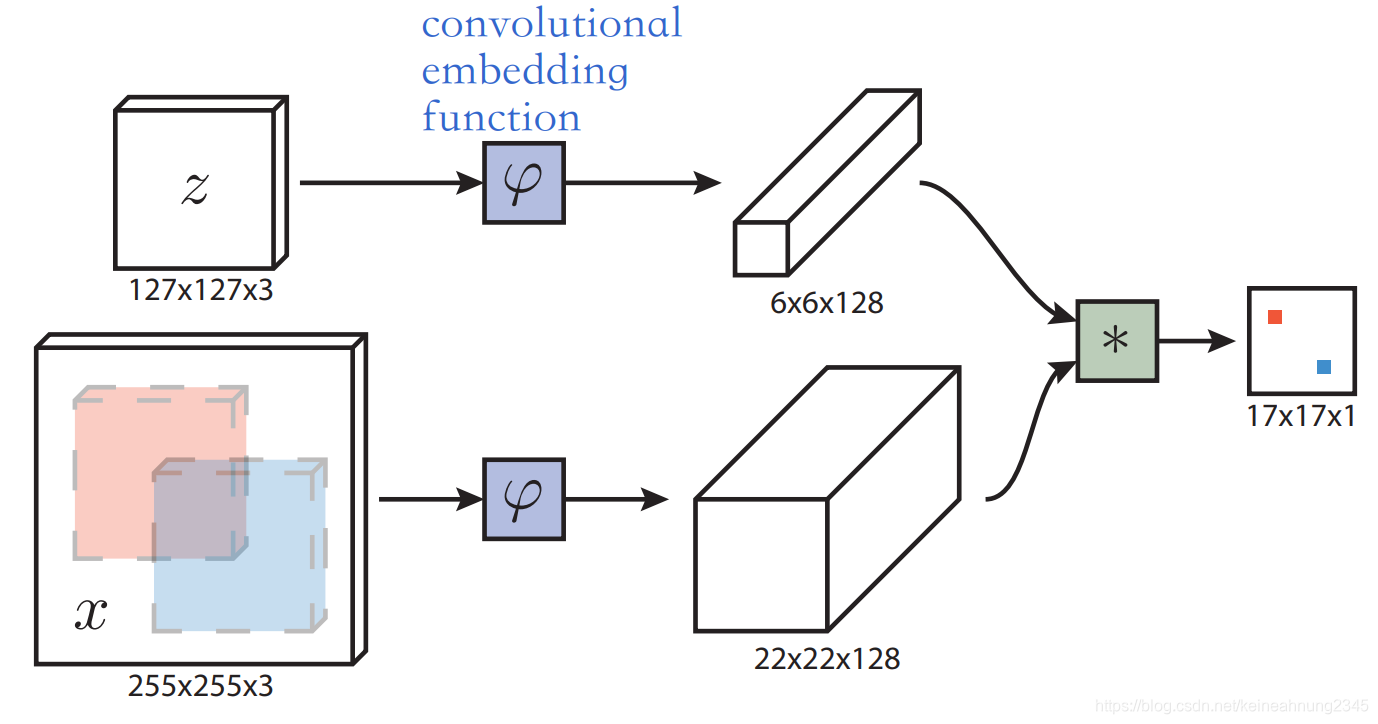
製作資料集
如上圖,模型的輸入是一對一對的exemplar image和search image。
其中exemplar image的大小為
,它是在bounding box周圍加上
的margin後縮放成
的大小。
search image的大小則為
。
fully-convolutional
為了學習兩個輸入間的相似度,本作使用了全卷積的孿生網路結構,此處先從數學的角度來看看全卷積是什麼意思。
如果一個函數與平移函數滿足交換律,則稱該函數是全卷積(fully-convolutional)的。用另一種話說就是translation invariance,平移不變性。
首先定義一個平移函數
:
。
即,經平移後的
的第
個像素與原來的
上的第
個像素相等。
是 外的另一個函數,如果 滿足以下條件: ,則稱 是fully-convolutional with stride for any translation 。
為什麼這裡會多出一個
呢?這是因為函數
可能會改變輸入的大小。
假設在通過
後輸入的長跟寬都會變成
,那麼將輸入平移
再通過
的結果,將會等於先將輸入通過
再平移
的結果。
網路結構
上面提到本作是用全卷積的孿生網路來學習兩個輸入間的相似度。
以下便是孿生網路中單個網路的結構,其模仿了AlexNet,沒有使用padding。
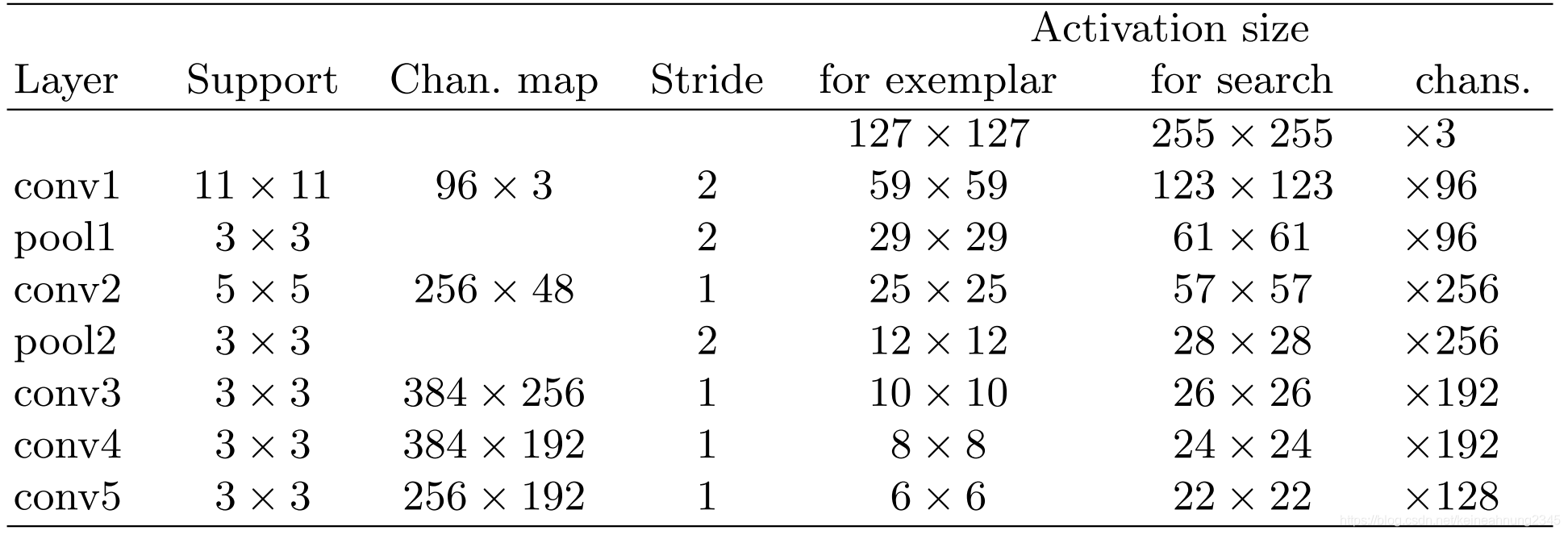
採用此種結構的主要原因是它不包含padding,因此在數學上是遵守fully-convolutional property的。
為何不惜使用如此簡單的網路也要保留網路的fully-convolutional property呢?
這是因為有了全卷積的網路結構,我們就不必用sliding-window的方式來比較一對大小不同的圖,而可以透過下面介紹的cross-correlation layer來一次性地得到一張小圖與另一張大圖上各window的相關性。
cross-correlation layer
為了計算圖片的相似度,這裡引入了cross-correlation layer。
在search image的大小比exemplar image大的情況下,一個顯而易見的方法是使用sliding-window,計算每個窗口與exemplar image的相似度,但是這種做法效率不高。
此處利用了conv-net的fully-convolutional特性。我們可以把exemplar image:
和一張較大的search image:
當作以下函數的輸入:
,它會輸出一個score map,代表
與
上各window的相似度。
其中的 代表cross-correlation。
網路訓練
正負樣本定義
兩張圖通過上面定義的函數
後會得到一個score map,這裡定義的便是score map的標籤。
如果score map上的一個像素與中心在映射回原始圖像後的距離(變成
倍)小於
,則定義其為正樣本。
公式中的 代表score map上的一個像素, 則代表score map的中心, 則是在輸入圖片尺度上的距離。
損失函數
定義好正負樣本後,就可以接著計算loss。
以下公式用於計算兩個像素間的logistic loss:
,其中
代表模型輸出的相似度,
則為標籤。
而一張score map的loss則定義為:
,即score map的範圍
上所有像素
的loss的平均值。
正負樣本的loss會被賦予不同的權重,以此來消除類別不平衡的問題。
訓練的目標是使用SGD,找到權重
,使得error可以最小化,由下式表示:
注意式中的
即為之前提到的
。
線上跟蹤
在跟蹤過程中,搜尋範圍 被設成:以上一幀目標出現的位置為中心,大小約為上幀目標物大小4倍的部份。
在原圖尺度中定位
使用bicubic interpolation將 的score map上採樣為 ,之後便可以在原圖尺度較為準確地進行定位。
多尺度跟蹤
算法會在5種尺度( )中進行搜索。
如果要尋找多尺度的目標,這裡的做法是把一張圖縮放成多種尺度,然後放在同一個mini-batch裡面,如此一來,便可以在一次前向傳播過程中完成多尺度的目標搜索。
算法穩定性
為了保持算法的穩定性,這裡採取了幾項措施:
- 使用cosine window來懲罰過大的位移
- 懲罰尺度的變化
- 減小尺度更新的幅度:在更新尺度時使用0.35的factor進行linear interpolation
其它trick
本作未使用以下方法:
- 更新模型
- 維護關於目標物外觀的記憶
- 光流
- color histogram
- refine bb prediction
- 針對不同數據集進行微調
(3)相關方法
- RNN:預測目標在每一幀中的位置
- particle filter:訓練RBM,接著比較後面各幀與第一幀中fixation的歐式距離
- tracking-as-detector:離線訓練CNN作為特徵抽取器,線上訓練一個目標檢測器用作跟蹤
- GOTURN:用conv-net回歸出物體在第二張圖片的位置。方法不具平移不變性,所以需要大量的數據擴充。
- YCNN:結構是一個Y形的網路,缺點是在測試時無法動態調節搜索區域的大小。
- SINT:採用孿生網路,但其結構卻非全卷積的。採用Struck中的包圍框採樣法、光流、RoI Pooling等多種方法。缺點是速度極慢,只有2FPS。
問題討論
為何在網路裡加上padding就會違反fully-convolutional property?
這裡來做一個小實驗,首先生成一張5x5的圖片:

先平移後padding:

先padding後平移:

可以看到padding與平移的順序的不同確實是會影響結果的。因此才說加入padding會破壞平移不變性。
cross-correlation是什麼?
卷积(convolution)与互相关(cross-correlation)的一点探讨這篇文章談到了convolution和cross-correlation,它們的公式分別是:
和
其中
代表filter,
代表原始信號(或說圖像),
則是經過操作後的信號。
從公式中可以看出來,cross-correlation就是filter經過上下+左右翻轉後的convolution。
那麼為什麼需要convolution和cross-correlation兩種操作呢?這則回答給出了解釋:
If you are performing a linear, time-invariant filtering operation, you convolve the signal with the system’s impulse response. If you are “measuring the similarity” between two signals, then you cross-correlate them.
也就是說,convolution是用來做線性,非時變的濾波操作;而cross-correlation則可以用來衡量兩個信號之間的相似程度。
cross-correlation可由卷積層實現?(需查看代碼)
cross-correlation與內積的關係
從上面的公式中,我們很容易地會將cross-correlation與內積聯想在一起,那麼它們之間的關係是什麼呢?以下是維基百科給出的定義:
In signal processing, cross-correlation is a measure of similarity of two series as a function of the displacement of one relative to the other. This is also known as a sliding dot product or sliding inner-product. It is commonly used for searching a long signal for a shorter, known feature.
果然如我們看到公式時的猜想,維基百科的定義中說明了cross-correlation又被稱為滑動的內積。
bilinear layer是什麼?
在Introduction中提到了:
dense and efficient sliding-window evaluation is achieved with a bilinear
layer that computes the cross-correlation of its two inputs
其中的bilinear layer是指什麼呢?
在維基百科中搜尋bilinear,會出現Bilinear sampling,Bilinear form,Bilinear interpolation,Bilinear map,Bilinear transform,Bilinear transformation (disambiguation)等多個候選詞,其中較接近的當屬Bilinear map。
以下是bilinear map的定義:
In mathematics, a bilinear map is a function combining elements of two vector spaces to yield an element of a third vector space, and is linear in each of its arguments. Matrix multiplication is an example.
bilinear map是一個函數,它接受來自兩個向量空間的元素當作輸入,並輸出一個在第三個向量空間裡的元素。而binlinear map對這兩個元素來說都是線性的,矩陣乘法便是其中一個例子。
根據這個解釋,我們可以猜到論文Introduction所說的bilinear layer指的就是cross-correlation layer。該函數確實是接受 及 兩個向量空間裡的元素當作輸入,經過一個線性的運算後,輸出第三個向量空間裡的元素(即score map)。
為何(2.2)裡的logistic loss與我們之前看過的不一樣?
論文(2.2)節中計算樣本對logistic loss的公式如下:
而我們在邏輯回歸看到過的logistic loss(即cross entropy loss,參考維基百科 - Cross entropy),則是:
這兩者似乎不太一樣?
後來是看到了這則回答才解決了筆者的疑感。簡單來說,這是因為兩者對負樣本的y定義不同所致(邏輯回歸負樣本的y為0;此處負樣本的y則是-1)。
首先我們知道:
,而
以上二式對不同定義的y都是有效的。
在第一種情況,也就是當y=0,1時,loss的計算如下。我們可以將loss拆成兩項,得到:
這也就是我們學過的邏輯回歸的損失函數公式。
而在第二種情況,也就是y=±1時,則可以很容易地將
及
此二式合而為一:
然後再將它代入計算loss的公式
內,並繼續簡化:
最終可以得出論文裡所用的logistic loss的公式。
總的來說,就是定義負樣本標籤的方式不同,導致同樣的 被以不同的方式簡化,才會出現兩種不同型式的logistic loss。
學到一個目標總是在中心的bias是沒有risk的?
論文中有這麼一段話:
Since our network is fully-convolutional, there is no risk that it learns a bias
for the sub-window at the centre. We believe that it is effective to consider
search images centred on the target because it is likely that the most difficult
sub-windows, and those which have the most influence on the performance of
the tracker, are those adjacent to the target.
此條論述在SiamRPN++裡被推翻?
cosine window是什麼?
在說明cosine window之前,先來看看window function是什麼,以下是維基百科的介紹:
In signal processing and statistics, a window function (also known as an apodization function or tapering function[1]) is a mathematical function that is zero-valued outside of some chosen interval, normally symmetric around the middle of the interval, usually near a maximum in the middle, and usually tapering away from the middle.
意即窗函數(window function)是一種數學函數,其在所選區域外的值為0,通常是以區間中心為軸左右對稱,通常在中央有最大值,並往兩側逐漸變小。
a cosine window is added to the score map to penalize large displacements
cosine window即為一種window function,以下是一維的cosine window:
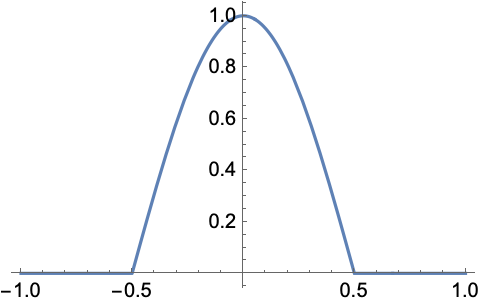
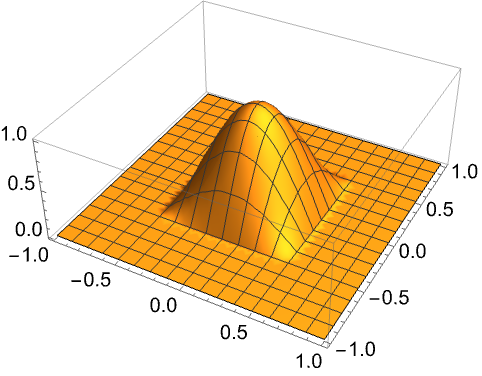
二維的cosine window:
接著來看看cosine window的作用:
 cosine window cosine window |
 原始信號 原始信號 |
 作用後信號 作用後信號 |
可以看到原始信號在經過cosine window作用過後,變得中間高、兩側低。
可以想見,如果將一個二維的cosine window作用到score map上後,score map的分數值也將變為中間高、周圍低,這也是論文中所說,用cosine window來懲罰過大位移的作法。
bicubic interpolation是什麼?
bilinear interpolation
回憶一下在Mask R-CNN中用到的bilinear interpolation。
在計算每一個輸出值時,共需要4個輸入值,如下圖(來自維基百科)的左下所示:

其步驟為:先計算上下兩條邊上的線性內插值,再用得到的兩個內插值再行一次線性內插,即可獲得位於格子中間任一點的估計值。
cubic interpolation
在進入bicubic interpolation之前,先來看一下cubic interpolation。
如右上角的小圖,圖中紅、黃、綠、藍是輸入的四個點,我們會用一個三次多項式來擬合這四個點,然後就可以得到黑色點的估計值。
bicubic interpolation
bicubic interpolation是cubic interpolation的二維版本,在計算每一個輸出值時,共需要16個輸入值。
如右下角的小圖,須先算出黑點上下四條橫線各自的三次多項式,找出對應位置的cubic interpolation內插值後,再進行一次cubic interpolation,才能得到中間黑點的bicubic interpolation內插值。
參考連結
Which loss function is correct for logistic regression?
The difference between convolution and cross-correlation from a signal-analysis point of view
維基百科 - Cross-correlation
維基百科 - Cross entropy
維基百科 - Bicubic interpolation
維基百科 - Window function
Wolfram - CosineWindow
