目的意义
查看自己微信好友男女比例
获取好友个性签名等分词生成词云图
好友地区分布图
数据来源
用自己的微信呗,难道还能用别人的不成。哈哈
其他数据:
链接:https://pan.baidu.com/s/1XtBFZOQDzXhj2UmCPU9rtw
提取码:ym3x
复制这段内容后打开百度网盘手机App,操作更方便哦
代码:
from pylab import mpl
import matplotlib.pyplot as plt
mpl.rcParams['font.sans-serif'] = ['SimHei']
import pandas as pd
import numpy as np
import jieba
from scipy.misc import imread
from wordcloud import WordCloud
import re
from pyecharts.charts import Map
from pyecharts import options as opts
from wxpy import *
# 登录操作
bot = Bot()
# 列举登录账号好友列表
all_friends = bot.friends()
# rint(all_friends)
# 列举登录账号所关注的公众号
Official_Accounts = bot.mps()
# print(Official_Accounts)
# 列举登录账号群聊列表
current_group_chat = bot.groups()
# print(current_group_chat)
# 根据好友的备注名称搜索好友
friend = bot.friends().search('刘虎林')[0]
print("搜索好友:",friend)
#搜索好友并发送消息
bot.friends().search("刘虎林")[0].send("hello")
#向文件助手发送信息
bot.file_helper.send("hello")
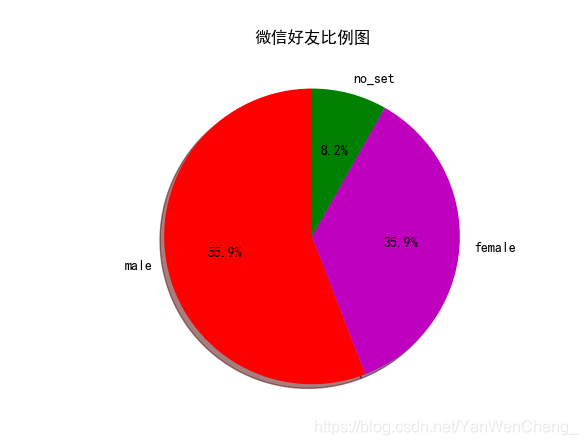
#2.1显示男女比例
sex_diet = {'male': 0 ,'female' : 0,'no_set':0}
for friend in all_friends:
#print(friend.sex)
if friend.sex == 1:
sex_diet['male'] +=1
elif friend.sex==2:
sex_diet['female'] +=1
elif friend.sex == 0:
sex_diet['no_set'] +=1
print(sex_diet)
#2.2使用matplotlib可视化
slices = [sex_diet['male'],sex_diet['female'],sex_diet['no_set']]
activities = ['male','female','no_set']
col = ['r','m','g']
#startangle:开始绘图的角度,逆时针旋转
#shadow:阴影
#%1.1f%%:格式化字符串,整数部分最小1位,小数点后保留一位,%%:转义字符
plt.pie(slices,labels=activities,colors=col,startangle=90,shadow=True,autopct="%1.1f%%")
plt.title("微信好友比例图")
plt.show()
#统计省份
province_dict = {'北京': 0, '上海': 0, '天津': 0, '重庆': 0, '河北': 0, '山西': 0, '吉林': 0, '辽宁': 0, '黑龙江': 0, '陕西': 0, '甘肃': 0,
'青海': 0, '山东': 0, '福建': 0, '浙江': 0, '台湾': 0, '河南': 0, '湖北': 0, '湖南': 0, '江西': 0, '江苏': 0, '安徽': 0,
'广东': 0, '海南': 0, '四川': 0, '贵州': 0, '云南': 0, '内蒙古': 0, '新疆': 0, '宁夏': 0, '广西': 0, '西藏': 0, '香港': 0,
'澳门': 0, }
# 统计各省好友数量
for friend in all_friends:
#print(friend,friend.province)
if(friend.province in province_dict.keys()):
province_dict[friend.province] +=1
#print(province_dict)
#为了数据方便呈现,生成json array格式数据
data = []
for key,value in province_dict.items():
data.append({'name':key,'value':value})
#print(data)
data1 = pd.DataFrame(data)
data1.columns = ['city','popu']
#print(data1)
# 绘制城市分布图
map = Map().add("微信好友城市分布图", [list(z) for z in zip(data1['city'], data1['popu'])], "china").set_global_opts(
title_opts=opts.TitleOpts(title="Map-VisualMap(连续型)"), visualmap_opts=opts.VisualMapOpts(max_=10))
map.render('ditu.html')
#写文件 with as 自动执行f.close() a为末尾追加
def write_file(path,txt):
with open(path,"a",encoding="gbk") as f:
return f.write(txt)
def read_file(path):
with open(path,"r",encoding="gbk") as f:
return f.read()
#统计登陆账号好友个性签名
for friend in all_friends:
#print(friend ,friend.signature)
#对数据进行清洗,将标点符号等对词频统计造成影响的因素剔除
pattern = re.compile(r'[一-龥]+')
#对某一个个性签名进行匹配,值匹配中文汉字,结果是列表
filterdata = re.findall(pattern,friend.signature)
#print(filterdata)
write_file("signatures.txt",''.join(filterdata))
content = read_file("signatures.txt")
#输出内容:仅汉字
#print(content)
#输出分词结果,结果为列表
segment = jieba.lcut(content)
#print(segment)
#生成数据框,有一列元素 若字典键值有相同则取最后的值
words_df = pd.DataFrame({'segment':segment})
#print(words_df)
#停止词的读取,词云图不能有这些词 index_col=False:第一列不作为索引值
stopwords = pd.read_csv('stopwords.txt', index_col=False , sep=" ", names=['stopword'],encoding='gbk')
#print(stopwords)
#查看停止词是否在分词数据框
#print(words_df.segment.isin(stopwords.stopword))
#查看过滤停止词后的数据框 segment的分词是否在stopwords中
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
#查看分词的频数
words_stat = words_df.groupby(by=['segment'])['segment'].agg({'计数':np.size})
print(words_stat)
#查看排序后的分词的频数,根据计数排序
words_stat = words_stat.reset_index().sort_values(by=["计数"],ascending = False)
#print(words_stat)
#读取背景图片
color_mask = imread('black_mask.png')
#设置词云属性 1.设置字体可以显示中文 2.背景颜色 3 词云显示的最大词数 4. 设置背景图片 5.字体最大值
wordcloud = WordCloud(font_path="Hiragino.ttf",background_color = "gary",max_words=100,
mask=color_mask,max_font_size = 100)
#生成词云字典,获取词频最高的前100个词
word_frequence = {x[0]:x[1] for x in words_stat.head(100).values}
print(word_frequence)
#绘制词云图
wordcloud.generate_from_frequencies(word_frequence)
wordcloud.to_file('ciyun_result.png')
#对图像进行处理
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
结果可视化


源码:
链接:https://pan.baidu.com/s/1GO4i-TXRBRdXyJDeApZ-2g
提取码:a7fd
