Spark作为一个基于内存的开源计算框架,在这个大数据时代背景下,受到越来越多的开发者的喜爱,相对于Hadoop,Spark拥有对大量数据更快的处理速度,并且易于使用(支持多种开发语言)。比Hadoop具有更多的优点,怎能不让人想去尝试一下Spark的魅力呢? 了解Spark的都知道Spark是用Scala写的,那么要想在windows下来运行Spark少不了的就要先安装Scala。 首先的在一个大前提下就是我们本机已经安装并配置好JDk环境变量了。 那么,我们就可以安装Scala了
- 1
- 2
- 3
- 4
一、安装Scala
下载地址:http://www.scala-lang.org/download/all.html
这是官方的下载,不嫌弃可以直接用我这个,已经下好保存在百度盘里了:
scala下载请点击这里
进入页面后选择一个Scala版本进行下载,我选择的是Scala2.12.0版本。特别注意的是看帖子又的说Scala版本与Spark版本之间是有一定关联的,比如说你的Scala版本是2.12.0,那么就应该下载Spark版本为从1.3.0到Spark 1.6.2之间的各个版本。这种说法不知道准不准确,但是还是注意一下比较好。
Scala安装好之后呢,它会自动在环境变量PATH里面配置。我们不需要进行手动配置了。下面就打开cmd输入Scala看下安装后控制台的输出效果。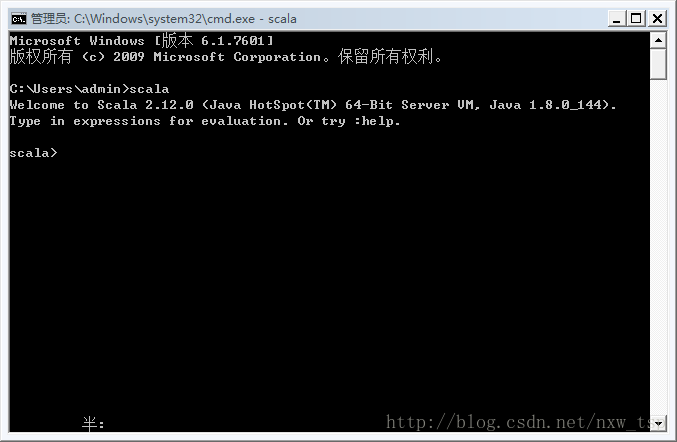
如果出现一下信息,那么就证明Scala已经安装成功了。
需要注意的是:如果在控制台输入scala之后输出没有出现版本信息,那么就需要你手动替换掉安装Scala时自动配置的变量。
既然Scala已经安装成功了, 那么我们就可以继续安装我们的主角Spark了
二、安装Spark
当然下面的也是官方的,如果想方便点,我这也有已经搞好的,直接百度云下载:
spark点击这里百度云下载
同样的我会附上Spark下载地址:http://spark.apache.org/downloads.html
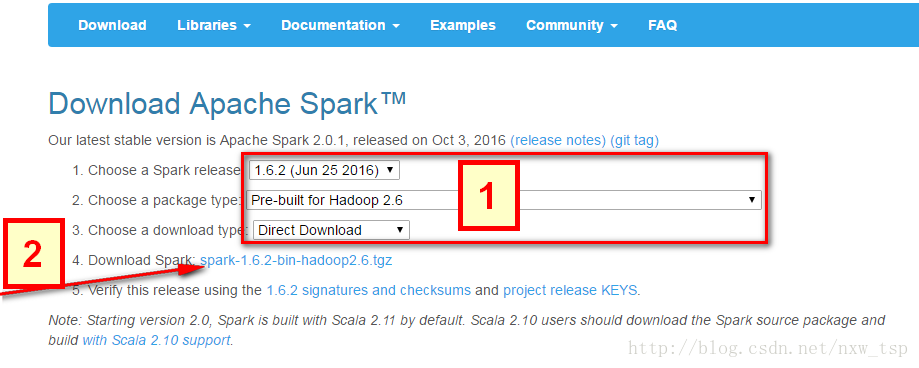
这里引用了别人的一张图片,因为公司网络有限制,导致访问页面布局错误,所以网上找了一张图片来给大家展示一下。
那么,当我们下载好之后,Spark是不需要进行安装的,直接解压到Spark目录,然后配置一下Path环境变量就可以了
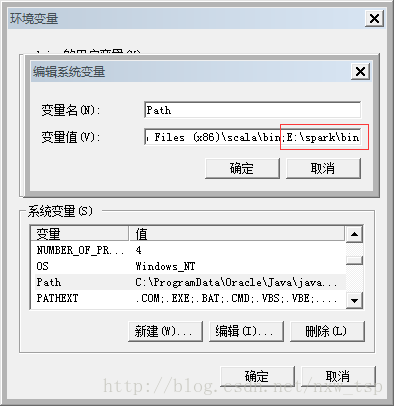
我的Spark目录为E:\spark\bin
下面我们来验证一下看spark是否能正常启动。
在控制台输入一下命令:spark-shell
注意spark-shell之间是没有空格的,千万不要输错了。
情况看图片
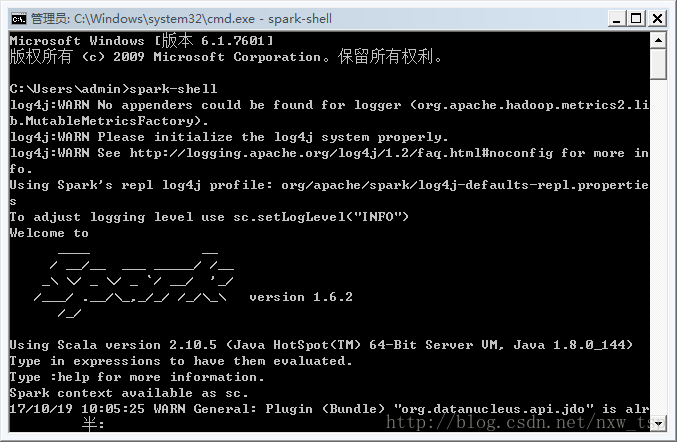
到这里就说明我们的准备工作已经做完了吗?显然不是,虽然控制台已经输出了Spark信息,但是并不是已经完全ok的,等待10秒钟左右控制台会继续输出信息。如下
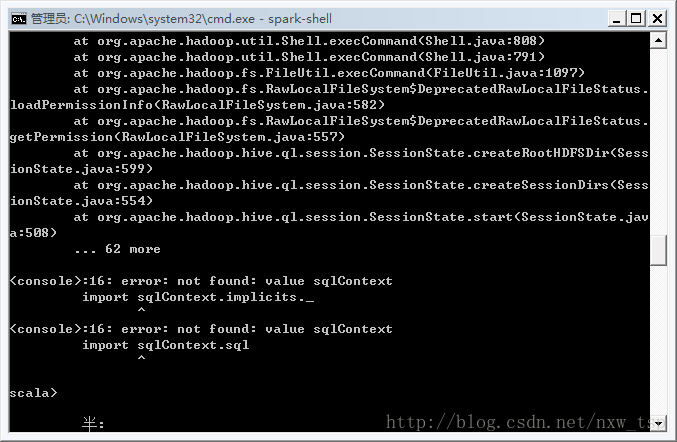
看到图中报错信息是不是快要崩溃了?别着急,听我慢慢道来
这里主要是因为Spark是基于Hadoop的,所以这里也有必要配置一个Hadoop的运行环境。
没关系,至于hadoop的安装,可以看我的另一篇博客,简单到就两步的事,因为那份我已经帮你们都配好了,下载完再配一下path系统路径就行。
