搭建的环境:
- windows10-1607
- spark-2.1.0
- python-3.5.2
安装Java/Jdk
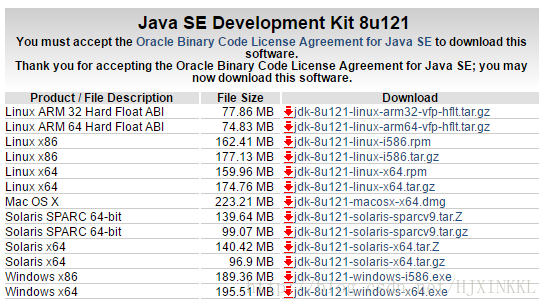
官网下载Java,这里我下的是8u121-windows-x64版本
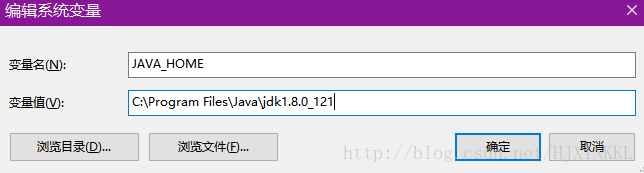
安装完设置环境变量,添加JAVA_HOME和CLASSPATH
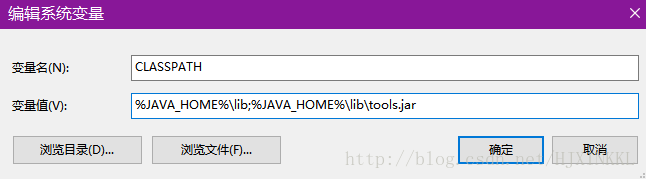
并在Path中添加
%JAVA_HOME%\bin
配置完毕,打开cmd,执行
java -version
可以查看Java的版本信息。若机器装有多个Java,只要修改JAVA_HOME地址即可。
安装Spark
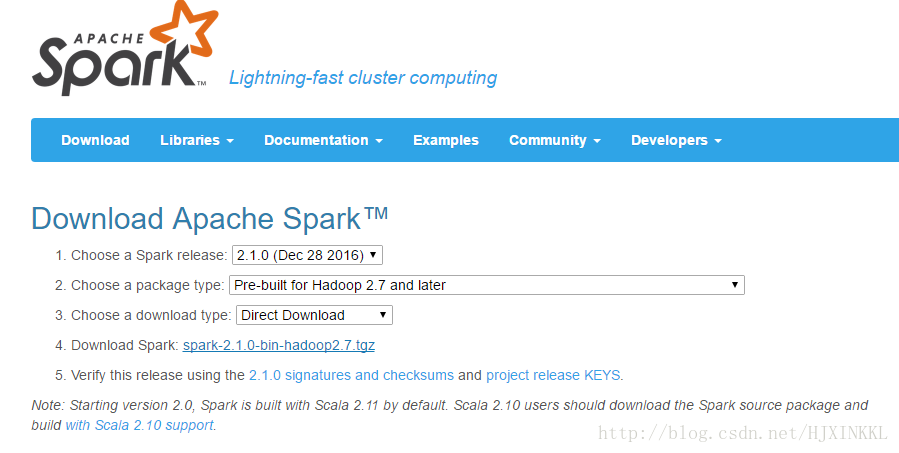
官网下载Spark,这里我下的是spark-2.1.0-bin-hadoop2.7.tar
解压,注意存放的路径一定不能带空格,例如放到C:\Program Files就不行。这里我放到了D:\spark
添加环境变量
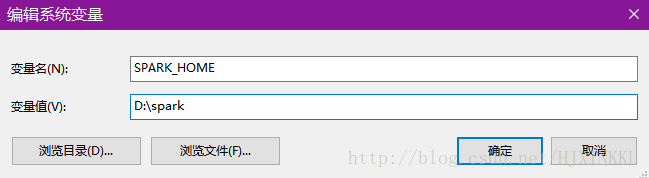
并在Path中添加
%SPARK_HOME%\bin
%SPARK_HOME%\sbin
安装Python
由于我很早之前就安装了Anaconda,这里就直接设置环境变量吧,添加PYTHONPATH

然后将spark\python\pyspark整个文件夹复制到Anaconda3\Lib\site-packages文件夹中。
安装Hadoop
无需安装完整的Hadoop,但需要hadoop.dll,winutils.exe等。根据下载的Spark版本,下载相应版本的hadoop2.7.1。
解压,添加环境变量HADOOP_HOME
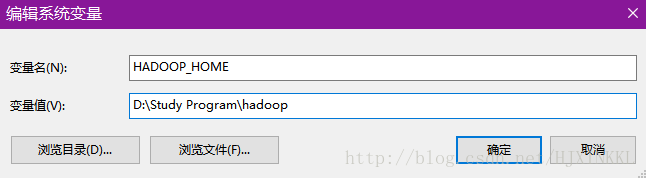
并在Path中添加
%HADOOP_HOME%\bin
验证
至此已经部署完毕,下面打开Spyder进行验证(若无安装Anaconda,用Python自带的IDLE或其他的python编辑工具都行)
注意setAppName、setMaster中千万不要带空格,否则会出现“Java gateway process exited before sending the driver its port number”的报错。之前就因为这个一直报错,网上查了很久都没揪出来,偶然才发现是空格的锅。
# pip install py4j
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("First_App")
sc = SparkContext(conf=conf)正常无报错的话,此时应该会弹出一个dos窗口。
# 计算0到9的总和
data = sc.parallelize(range(10))
ans = data.reduce(lambda x, y: x + y)
print (ans)
>>> 45
# README.md的行数和第一行
lines = sc.textFile("D:\spark\README.md")
print (lines.count())
print (lines.first())
>>>104
>>># Apache Spark验证成功,按Ctrl+D退出Spark shell