本地搭建spark环境,安装与详细配置
安装包下载地址:
JDK: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Hadoop2.6.5:http://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/
Scala2.11.8:https://www.scala-lang.org/download/all.html
Spark2.2.0:http://archive.apache.org/dist/spark/spark-2.2.0/

安装测试
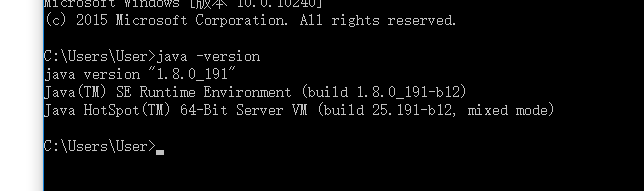
java -version
出现如下图代表安装成功。
其他环境变量设置:
PATH:C:\Program Files\Java\jdk1.8.0_191\bin;
CLASS_PATH :C:\Program Files\Java\jdk1.8.0_191\lib\dt.jar;C:\Program Files\Java\jdk1.8.0_191\lib\tools.jar;
JAVA_HOME :C:\Program Files\Java\jdk1.8.0_191 #这里后面不能有任何一个符号,我找错找了一下午,重装了 这几个包 又重新配置环境变量 真的是心累!!!!! hadoop会一直报JAVA_HOME不正确
JRE_HOME :C:\Program Files\Java\jdk1.8.0_191\jre
点开scala安装下载地址,下载windows版本即可,进行解压,将他放到 你自己的文件路径下。
环境变量设置
PATH : C:\Program Files\scala-2.12.0\bin;
SCALA_HOME :C:\Program Files\scala-2.12.0
安装测试:

点开spark安装下载地址,下载需要版本即可,进行解压,将他放到 你自己的文件路径下。
环境变量设置
HADOOP_PATH:C:\Program Files\hadoop-2.7.6
PATH:C:\Program Files\hadoop-2.7.6\bin;
安装测试

点开spark安装下载地址,下载需要版本即可,进行解压,将他放到 你自己的文件路径下。
环境变量设置
SPARK_HOME:C:\Program Files\spark-2.4.0-bin-hadoop2.7
PATH:C:\Program Files\spark-2.4.0-bin-hadoop2.7\bin;
安装测试

千万注意环境变量中的逗号 要不要打 这个错找了一天!!!!!
这里报错了,根据报错显示:我们去下载相应文件。
那么请找到你的hadoop\bin目录找下里面有没有winutils.exe文件,如果没有的话,我们需要去下载。
下载地址为:https://github.com/steveloughran/winutils
将下载的文件放入到你的hadoop安装路径下的bin下即可,重新运行

这里又报异常,我们还需要一个文件,hadoop.dll文件,就在前面的地址里,跟winutils 在同一目录下,下载相应版本的hadoop.dll.
再重新运行:

在你运行pyspark时。没有任何错误 ,可是当你输入脚本运行的时候,就会报异常。如下所示:

这是因为pyspark的版本过高的问题,我们可以再去网站上重新下一个2.2或者2.3版本即可。