简介
Pandas是目前Python生态圈最常用的数据分析工具库。
该库以NumPy为基础,增加了标签支持,整合了对数据集的读取、清洗、转换、分析、统计、绘图等一系列工作流程,能够高效地处理和分析结构化数据。
Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。Pandas适合处理数值和字符串混杂数据,numpy适合处理统一的数值数据。
安装 pip install pandas # anaconda中无需再安装
引入pandas的惯例
import numpy as np
import pandas as pd
from pandas import DataFrame, Series
Pandas的基本数据结构
Pandas提供了三种基本数据结构
Series:带标签的一维数组
DataFrame:带标签的二维数组(即表格)
Panel:带标签的三维数组(若干表格的叠加面板)
主要使用Series和DataFrame。与NumPy数组相比,Pandas最重要的改进是增加了标签(也称轴索引),可以实现自动的按索引对齐运算。
序列(Series)
import pandas as pd
from pandas import DataFrame, Series
pd.__version__ # 版本号 0.25.1
s1=Series([10,20,30]) # 创建Series,默认整数索引0~2
s2=Series([10,20,30], index=['a','b','c']) # 创建并指定索引

s2 = Series([10, 20, 30], index=['a', 'b', 'c']) # 创建并指定索引
Out:
a 10
b 20
c 30
s2['a'] # 按标签访问,10
s2[0] # 按整数下标访问,10
s2['a':'c'] # 标签切片,3个数据
Out:
a 10
b 20
c 30
s2[0:2] # 按整数索引切片,2个数据
Out:
a 10
b 20
# 求和,均值,中位数
s2.sum(), s2.mean(), s2.median()
s2['a']=100 # 修改'a'标签对应的值
s2['d']=200 # 通过赋值创建新标签
s2
Out:
a 100
b 20
c 30
d 200
标签自动对齐运算
s1 = Series([1, 2, 3], index=list('axb'))
s2 = Series({
'a':10, 'b':20, 'c':30})
s1 + s2
Series具有标签,运算时自动对齐标签进行计算,这是Pandas相比NumPy的重要改进。
s1的标签为['a','x','b'], s2的标签为['a','b','c'],执行s1 + s2 时,
两者都有的'a'、'b'标签自动对齐,对应的数值相加;
两者互不匹配的'c'、'x'标签相加后的值为NaN。
NaN(not a number)是Pandas中表示非数值或缺失值的符号。

series对象具有values和index属性
s2.values
Out: array([10, 20, 30], dtype=int64)
s2.index
Out: Index(['a', 'b', 'c'], dtype='object')
s2.index[0]='d' # 将报错, 标签不能单个修改
s2.index=['d', 'd','e'] # 但允许对标签一次性全部赋值修改
s2.index.value_counts() # 统计每个索引出现的次数
Out:
d 2 # 索引'd' 有2个
e 1
s2.groupby(level=0).sum() # Series按0级索引分组求和
Series对象的常用属性和方法
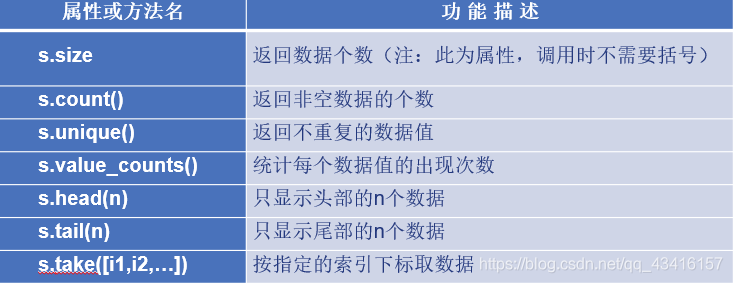
s = Series([0, 1, 1, 3, 3, 3, np.nan, np.nan]) # 构造Series,含2个np.nan
s.size, s.count() # 共8个数据,有6个非空数据, (8, 6)
s.unique() # 返回不重复的数据值 array([ 0., 1., 3., nan])
s.value_counts() # 统计每个数据值的频次
s.head(2) # 显示头部的2个数据
s.take([0, 2]) # 取第0, 2 个数据
数据框(DataFrame)
DataFrame(数据框)是Pandas最重要的数据结构。数据框可视为由行和列构成的二维表格,每行或每列都可视为一个Series。DataFrame既有行索引(index)又有列索引(columns)。
data = {
'apple': [1100,1050,1200], 'huawei': [1250,1300,1328], 'oppo': [800,850,750]}
df = DataFrame(data, index=['一月', '二月', '三月']) # index行标签
df['apple'] # 访问一列
df.loc['一月'] # 访问一行,不能写为df['一月']
df.loc['一月', 'apple'] # [行标签,列标签] 1100

数据框保存为csv文件

df.to_csv('mobile.csv', encoding='GBK') # GBK也可写为cp936编码
!type mobile.csv # csv默认逗号分隔, 显示数据文件内容

上例如不指定编码,Pandas保存时默认使用utf-8编码,Python文件编码默认和操作系统编码一致。当用!type命令显示文件内容时,Windows系统用GBK编码解析,中文将显示为乱码,所以在涉及中文文件时应视编码情况指定encoding='GBK’或’utf-8’参数。
# 将mobile.csv读入数据框df2,index_col=0指定第0列作为标签
df2 = pd.read_csv('mobile.csv', index_col=0, encoding='GBK') # 读取
#使用嵌套字典创建df,外层字典的键作为列名,内层的键作为行索引
df3 = DataFrame({
'apple': {
'一月':1100, '二月':1050, '三月':1200},\
'huawei': {
'一月':1250, '二月':1300, '三月':1328},\
'oppo' : {
'一月':800, '二月':850, '三月':750}})
数据框可视为二维表格,有index(行)和columns(列)两个重要属性。
在创建数据框时,可以指定index和columns。
frame=DataFrame(np.arange(12).reshape(3, 4), index=['a','b','c'],
columns=['c1', 'c2','c3','c4'])
frame.columns # 显示列名(列索引)
Out:Index(['c1', 'c2', 'c3', 'c4'], dtype='object')
frame.index # 显示行索引
Out: Index(['a', 'b', 'c'], dtype='object')
frame.index = [0, 1, 2] # 修改行索引
frame.columns = ['x1', 'x2', 'x3', 'x4'] # 修改列名
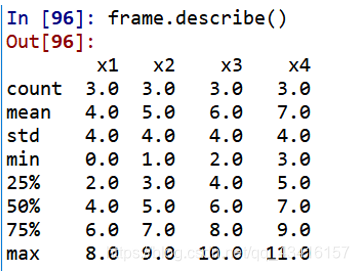
frame.describe() # 显示统计信息

访问数据
df = DataFrame(np.arange(12).reshape(3,4), index=['a','b','c'], columns=['c1','c2', 'c3','c4'])
df.info() # 显示列名及数据类型
df.head(2) # 显示头两行
df.tail(2) # 显示末尾两行

loc[ ]、iloc[ ]访问
按列访问
访问列数据时使用object['列名']或object.列名的形式。
df['c1'] # 访问c1列,也可写为df.c1
df[‘c1’] 和 df[ ‘a’: ‘c’ ] 对比
df[单值] # 按单列访问
df[切片] # 按行索引切片
df[ ['c1', 'c3'] ] # 访问c1, c3两列,注意多个列名要放入[ ]
df[df.c1 > 3] # 按条件访问,只显示c1列>3的行
df[(df.c1 > 3) & (df.c2 > 5)] # 按条件访问,c1列>3且c2列>5
[ ]内的逻辑运算符要使用 &(与)、|(或)、~(非),不能使用Python的and、or、not运算符。[ ]内的逻辑表达式要用小括号括起来,如上例中的(df.c1>3)&(df.c2>5)。

按行访问
loc和iloc存取器
访问行或块数据时常用loc[ ]和iloc[ ]存取器,loc基于标签,iloc基于整数索引下标。loc[ ]中可以是[单行]、[单行, 单列]、[行切片]、[行切片, 列切片]等多种表达形式。取出的是 Series 或 DataFrame。
loc[ ]和iloc[ ]格式示例表
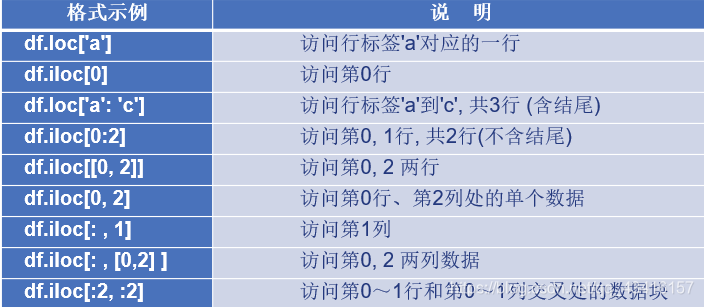
loc[]基于标签而iloc[]基于整数下标,所以不能出现loc[1]、iloc[‘a’]这样的写法。
另外,loc[‘a’:‘c’]将包含结尾的’c’标签,而iloc[0:2]不包含结尾的第2行。
修改数据
df.iloc[:2, :2] =99
df.iloc[:2, :2] =np.array(([3,4],[5,6]))

x=df.iloc[:2, :2] # 视图
x.iloc[:, :] =100 # 修改了x, df 也随之修改
x=df.iloc[:2, :2].copy() # 复制, x 和 df 分离
at[ ]、iat[ ]、query()访问
at[ ]和iat[ ]取数器
取单个数据可使用at[ ]或iat[ ]。at[ ]基于标签,iat[ ]基于整数索引,格式均为[单行,单列],取出的是单个数据而不是Series。
df.iat[1, 2] # iat基于行/列的整数索引,行/列都从0开始编号
df.at['b', 'c3'] # at基于行/列的标签
df.iat[0,2]=100 # 修改
query() 查询取数
数据框支持query()查询,语法类似数据库中的SQL查询,根据列名条件进行数据筛选,复制返回新DataFrame对象。
SQL查询: select * from 表 where c1>2 and c2>6
df.query('c1 > 2') # 查询c1>2
x=df.query('c1 > 2 and c2 > 6') # 查询c1>2 and c2>6,复制

算术运算和对齐
nan缺失值处理
有时原始数据中含有缺失值。NumPy用np.nan表示缺失值,Pandas用NaN(Not a Number)表示缺失值。两者对nan值的默认处理不同。NumPy运算时若有np.nan则返回nan。Pandas运算时若有np.nan则忽略nan,用其他非nan数据进行运算并返回结果。
b = np.array([1, 5, np.nan, np.nan, 10])
b.sum(), b.mean() # 有nan值时NumPy运算返回nan, np.isnan(b)
Out: (nan, nan)
s = Series(b) # 生成Series,含有nan
s.sum(), s.mean() # Series默认忽略nan值
Out: (16.0, 5.333)
s.mean(skipna=False) # 表示不能忽略nan
Out: nan
1.isnull()和notnull()函数:判断每个值是否是nan值,返回布尔数组
s.isnull().sum() # 统计缺失值个数 , 2
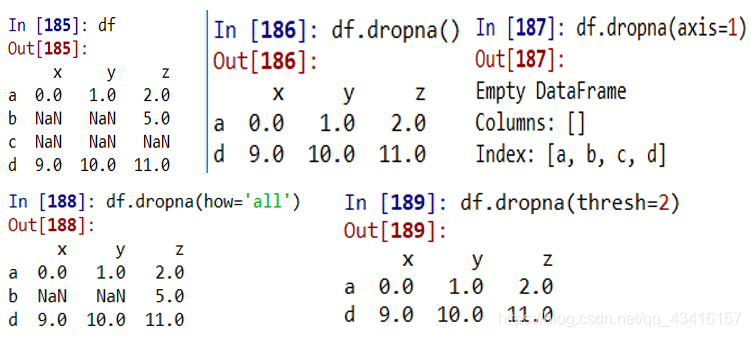
2.dropna()函数:返回删除nan值后的新数据框,df不变
df = pd.DataFrame(np.arange(12).reshape(4, 3), index=list('abcd'), columns= list('xyz'))
df.iloc[1:3, 0:2] = np.nan # 特意设置几个nan值
df.iloc[2, 2] = np.nan
axis=1 按列,含有nan值的列被删除。默认是axis=0, 按行
how='all' 表示某行的所有数据都为nan才删除
thresh=2 nan值个数>=2才删除
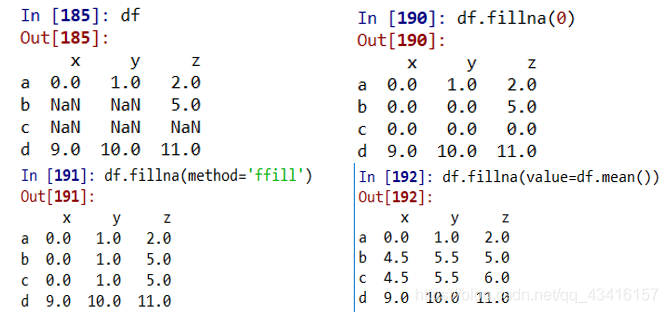
3.fillna()函数:将nan值用特定的值填充
df.fillna(0) # 缺失值都用0填充
df.fillna(method='ffill') # 缺失值用其前面的非nan值填充
df.fillna(method='bfill') # 缺失值用其后面的非nan值填充
df.fillna(value=df.mean()) # 用计算得到的平均值填充
对齐处理
Pandas支持标签访问数据,运算时会自动基于标签对齐进行计算。运算数据若是Series则只有行标签,若是DataFrame则会在行、列两个方向上对齐标签再计算,标签不匹配的数据元素默认标记为NaN值。
df = pd.DataFrame(np.arange(9).reshape(3, 3), index=list('abc'), columns=list('xyz'))
s = pd.Series([1, 2, 3], index=list('xyz'))
df + s
DataFrame和Series之间的运算默认将Series的索引匹配到DataFrame的列,
然后沿着行方向一直向下广播。

上例是按axis=1对齐,下面的例子指定按axis=0方向对齐。
df = pd.DataFrame(np.arange(9).reshape(3, 3), index=list('abc'), columns=list('xyz'))
s = pd.Series([1, 2, 3], index=list('abc'))
df.sub(s, axis=0) # 也可写为 axis='index'

两个数据框运算时,在行、列索引上都要对齐。
df2 = pd.DataFrame(np.arange(9,18).reshape(3,3), index=list('abd'), columns= list('wxy'))
df + df2
df.add(df2, fill_value=0) # 缺失的Nan值用0替代
df和df2在行标签上只有'a'、'b'匹配,列标签上只有'x'、'y'匹配,
所以只有对应位置上的4个数据值相加,其余位置上都为NaN。
结果的行、列标签是两个数据集标签的并集。

通用函数
Pandas基于NumPy,所以NumPy的通用函数都可以在Pandas中使用。
df = pd.DataFrame(np.arange(9).reshape(3,3), index=list('abc'), columns=list('xyz'))
df.sum() # 默认按axis=0 行求和
df.sum(axis=1) # axis=1,按列求和
df.sum().sum() # 对所有数据求和, 和为36
df.mean(), df.var() # 均值 / 方差

另一类常见的操作是将自定义的函数应用到各行或各列上,
以对整行或整列进行统计。
DataFrame的apply()方法可以实现这一功能。
np.random.seed(7)
ar=np.random.randint(0,11,size=(3,3))
df = pd.DataFrame(ar, index=list('abc'), columns=list('xyz'))
f = lambda x: x.max() - x.min() # 定义函数f,参数x将代表整行、整列
df.apply(f) # 在axis=0(纵向)求 最大值-最小值
df.apply(f, axis=1) # 在axis=1(横向)求 最大值-最小值
df.apply(lambda x:x-x.mean()) # 计算每列数据与均值的差

apply()方法应用到整行、整列上,数据框还有一个applymap()方法应用到单个数据上。
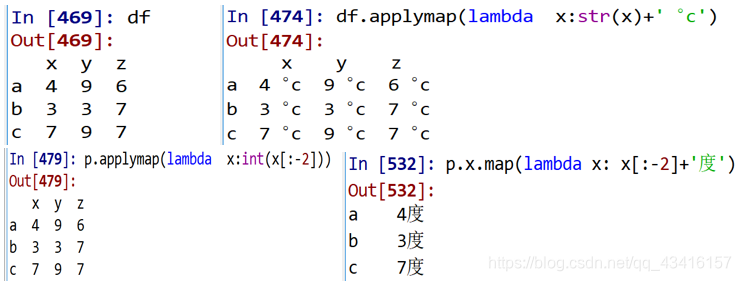
下面定义一个匿名函数lambda x:str(x) +’︒c’ ,其中的x代表每个数据,str(x)将其转换为字符串,然后加上’︒c’ 。
p = df.applymap(lambda x:str(x)+'︒c') # 在每个数据上变换
p.applymap(lambda x:int(x[:-2])) # 去掉︒c, 转为整数
p.x.map(lambda x: x[:-2]+'度') # Series有类似的map方法