哈希表
红黑树实现的符号表可以保证对数级别的性能,但我们可以做得更好。哈希表实现的符号表提供了新的数据访问方式,插入和搜索操作可以在常数时间内完成(不支持和顺序有关的操作)。所以,在很多情况下的简单符号表,用哈希表实现是最好的选择。
hash functions
如果键是小整数,那么我们可以直接使用数组来实现符号表,把键当做数组索引,于是键 i 对应的值放在数组位置 i 上。哈希(散列)是这个简单方法的拓展,可以处理类型更复杂的键。通过数学计算把键转为数组索引,我们就可以用数组来查询(reference)键值对。
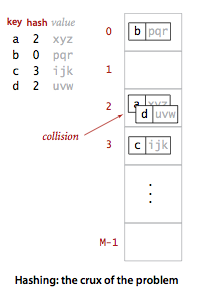
使用哈希的算法由两部分组成。第一,用哈希函数把搜索键转化为数组索引。理想情况下,不同的键会映射成不同的数组索引。但一般来说是不可能的,我们要考虑到会有两个或者更多的键映射到同一数组索引上。因此,哈希搜索的第二部分就是针对这一情况的碰撞解决过程。
如果我们有一个可以容纳 M 个键值对的数组,那么我们需要一个函数,可以把任意给定的键映射到数组索引上,也就是 [0, M-1] 的整数序列。而且,我们希望这个函数易于计算,还能把键均匀地分开。接着,我们简略讨论一些数据类型的哈希函数。
positive integers
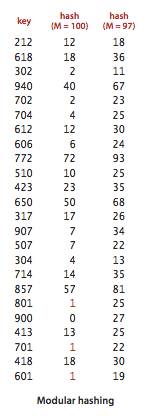
将正整数散列的最常见方法就是取模法(modular hashing)。我们让数组的大小为素数 M,对于任意正整数 k,计算 k 除以 M 的余数。这个函数的计算非常容易并且能够有效地将键散布在 0 到 M-1 之间。如果 M 不是素数,我们可能无法利用键中包含的所有信息,这可能导致我们无法均匀分布键。例如,如果键是十进制数而 M 为 \(10^{k}\),那么我们只能利用键的后 k 位,这可能产生一些问题。举个简单的例子,假设键为电话号码的区号且 M=100。由于历史原因,美国的大部分区号中间位都是 0 或者 1,因此这种方法会将大量的键散列为小于 20 的索引,但如果使用素数 97,散列值的分布显然会更好(一个离 100 更远的素数会更好),如下图所示。与之类似,互联网中使用的 IP 地址也不是随机的,所以如果我们想用取模法将其散列就需要用素数(2 的幂除外)大小的数组。
floating-point numbers
如果键是 0 到 1 之间的实数,我们可以将它乘以 M 并四舍五入得到一个 0 至 M-1 之间的索引值。尽管这个方法很容易理解,但它是有缺陷的,因为这种情况下键的高位起的作用更大,最低位对散列的结果没有影响。修正这个问题的办法是键表示为二进制数然后再使用取模法(Java 就是这么做的)。
public final class Double {
private final double value;
...
public int hashCode() {
long bits = doubleToLongBits(value);
// convert to IEEE 64-bit representation
// xor most significant 32-bits with least significant 32-bits
return (int) (bits ^ (bit >>> 32));
}
}注:>>> 移位之后在高位补零,>>的话,负数会补一。例如说 a = -3(用 3 的补码表示为 1111 1111 ... 1111 1101 总共 32 位),a >> 1 的输出为 -2(1111 1111 ... 1111 1110),a >>> 1 的值为 2147483646(0111 1111 ... 1111 1110),\(2^{31} = 2147483648\)。
Strings
取模法对像字符串这样较长的键也同样适用,只要把其当作较大的整数就好。举例来说,下面的代码就能计算字符串 s 的散列值,其中 R 是一个较小的素数(Java 用 31)。
int hash = 0;
for (int i = 0; i < s.length(); i++)
hash = (R * hash + s.charAt(i)) % M;关于 Java 为什么使用 31,booksite 上 Q+A 部分是这么解释的:
It's prime, so that when the user mods out by another number, they have no common factors (unless it's a multiple of 31). 31 is also a Mersenne prime (like 127 or 8191) which is a prime number that is one less than a power of 2. This means that the mod can be done with one shift and one subtract if the machine's multiply instruction is slow.
Compound keys
对于组合键,我们采取和字符串一样的处理方式。比如说,键的类型是 Date,含有几个整型的域:day,month 和 year,我们可以这样计算 Date 的散列值:
int hash = (((day * R + month) % M) * R + year) % M;Java conventions
每种数据类型都需要相应的哈希函数,于是 Java 令所有数据类型都继承了一个返回 32 位整数的方法 hashCode()。每一种数据类型的 hashCode() 方法都必须和 equals() 方法一致。也就是说,如果 a.equals(b) 返回 true,那么 a.hashCode() 的返回值必然和 b.hashCode() 的返回值相同。反过来说,如果两个对象的 hashCode() 方法的返回值不同,那么我们就知道这两个对象是不同。但是,如果两个对象的 hashCode() 方法的返回值相同,这两个对象也有可能不同,我们需要用 equals() 方法进行判断。默认哈希函数会返回对象的内存地址,但这只适用于很少的情况。Java 为很多常用的数据类型重写了 hashCode() 方法(包括 String、Integer、Double、File 和 URL)。
Converting a hashCode() to an array index
把 hashCode() 方法返回的 32 位整数变成我们需要的数组索引:
private int hash(Key x) {
return (x.hashCode() & 0x7fffffff) % M;
}这会将符号位屏蔽(将一个 32 位整数变成一个 31 为非负整数),然后用取模法计算它除以 M 的余数。
booksite 上 Q+A 部分也有关于上面转正成索引的讨论:
Q. What's wrong with using (s.hashCode() % M) or Math.abs(s.hashCode()) % M to hash to a value between 0 and M-1?
A. The % operator returns a non-positive integer if its first argument is negative, and this would create an array index out-of-bounds error. Surprisingly, the absolute value function can even return a negative integer. This happens if its argument is Integer.MIN_VALUE because the resulting positive integer cannot be represented using a 32-bit two's complement integer. This kind of bug would be excruciatingly difficult to track down because it would only occur one time in 4 billion! [ The String hash code of "polygenelubricants" is -2^31. ]
Java 文档 abs(int) 里说:
Note that if the argument is equal to the value of Integer.MIN_VALUE, the most negative representable int value, the result is that same value, which is negative.
众所周知 int 的表示范围是 \(2^{31}-1\) 到 \(-2^{31}\),负数多一位转正后又绕回去了吧(没找到内部怎么实现,姑且这么理解吧)。
User-defined hashCode()
散列表的用例希望 hashCode() 方法能够将键平均地散布在所有可能的 32 位整数上。也就是说,对于任意对象 x,你可以调用 x.hashCode() 并认为有均等的机会得到 \(2^{32}\) 中的任意一个 32 位整数值。Java 中的 String、Integer、Double、File 和 URL 对象的 hashCode() 方法都能实现这一点。面对自己定义的数据类型,你必须试着自己实现这一点。可以像 PhoneNumber.java 用实例变量的整数值和取模法来得到散列这,或是 Transaction.java 这样将对象中的每个变量的 hashCode() 返回值转化为 32 位整数并计算得到散列值(系数的具体值,这里是 31,并不是很重要)。
对于给定的数据类型,实现一个好的哈希函数要满足下面三个条件:
- 一致性(deterministic):等价的键必然产生相等的散列值;
- 高效性(efficient):计算简便;
- 均匀性(uniform):均匀地散列所有的键。
为了分析哈希算法以及讨论它们的性能,我们作出下面这个理想化的假设。
uniform hashing assumption
均匀散列假设:我们使用的哈希函数能够均匀并独立地将所有的键散布于 0 到 M-1 之间。
尽管验证这个假设很困难,但它仍然是考察散列函数的重要方式,原因有两点。首先,设计散列函数时应尽量避免随意指定参数以防止大量的碰撞,这是我们的重要目标;其次,尽管我们无法验证假设本身,它提示我们使用数学分析来预测散列算法的性能并在实验中进行验证。
separate chaining
基于分离链法的散列表。哈希函数把键转化为数组索引,接着哈希算法的第二步是碰撞处理(collision resolution):一种当两个或者更多待插入的键哈希出同样索引的处理策略。碰撞处理的一个很直接的方法是,给 M 个数组索引都对应一个链表,用来存放哈希出这个索引的键的键值对。基础思想是要选择足够大的 M,使得所有链表都尽可能短以保证高效地查找。查找分两步:首先根据散列值找到对应的链表,然后沿着链表顺序查找相应的键。
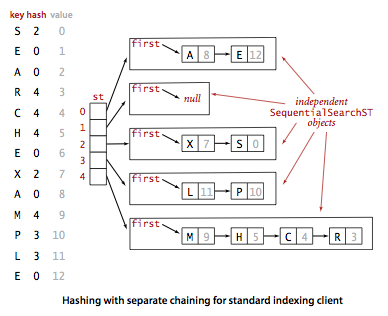
代码:
public class SeparateChainingHashST<Key, Value> {
private int M = 97; // number of chains
private Node[] st = new Node[M]; // array of chains
private static class Node {
private Object key;
private Object val;
private Node next;
...
}
private int hash(Key key) {
return (key.hashCode() & 0xfffffff0) % M;
}
public Value get(Key key) {
int i = hash(key);
for (Node x = st[i]; x != null; x = x.next) {
if (key.equals(x.key)) {
return (Value) x.val;
}
}
return null;
}
public void put(Key key, Value val) {
int i = hash(key);
// update the value if key-value pair already in the linked-list
for (node x = st[i]; x != null; x = x.next) {
if (key.equals(x.key)) {
x.val = val;
return;
}
}
// put the new key-value pair in the first place
st[i] = new Node(key, val, st[i]);
}
}在一张含有 M 条链表和 N 个键的散列表中,(在均匀散列假设成立的情况下)任意一条链表中的键的数量均在 N/M 的常数因子范围内的概率无限趋向于 1。
在一张含有 M 条链表和 N 个键的散列表中,未命中查找和插入操作所需的比较次数为 ~N/M。
linear probing
实现散列表的另一种方式就是用大小为 M 的数组保存 N 个键值对,其中 M>N。我们需要依靠数组中的空位解决碰撞冲突。基于这种策略的所有方法被统称为开放地址(open address)散列表。
开放地址散列表中最简单的方法叫做线性探测法:当碰撞发生时(当一个键的散列值已经被另一个不同的键占用),我们直接检查散列表中的下一个位置(将索引值加 1)。这样的线性探测可能会产生三种结果:
- 命中,该位置的键和被查找的键相同;
- 未命中,键为空(该位置没有键);
- 继续查找,该位置的键和被查找的键不同。
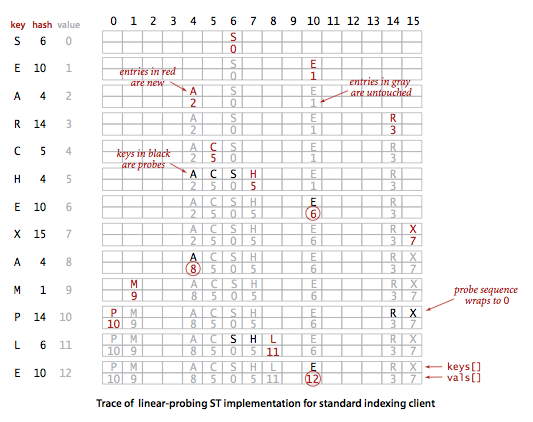
代码:
public class LinearProbingHashST<Key, Value> {
private int N = 30001;
private Value[] vals = (Value[]) new Object[M];
private Key[] keys = (Key[]) new Object[M];
private int hash(Key key) {
return (key.hashCode() & 0x7fffffff) % M;
}
public void put(Key keym Value val) {
int i;
for (i = hash(key); keys[i] != null; i = (i+1) % M)
if (keys[i].equals(key))
break;
keys[i] = key;
vals[i] = val;
}
public Value get(Key key) {
for (int i = hash(key); keys[i] != null; i = (i+1) % M)
if (key.equals(keys[i]))
return vals[i];
return null;
}
}类似的,开放地址类的散列表的性能也依赖于 \(\alpha = N/M\) 的比值,但意义有所不同。我们将 \(\alpha\) 称为散列表的使用率。对于基于分离链法的散列表,\(\alpha\) 是每条链表的长度,因此一般大于 1;对于基于线性探测的散列表,\(\alpha\) 是表中已被占用的空间的比例,它是不可能大于 1 的。事实上,我们不允许 \(\alpha\) 达到 1(散列表被占满),因为此时未命中的查找会导致无限循环。为了保证性能,我们会动态调整数组的大小来保证使用率在 1/8 到 1/2 之间。
尽管最后的结果的形式相对简单,准确分析线性探测法的性能是非常有难度的。Knuth 在 1962 年作出的以下推导式算法分析史上的一个里程碑:在一张大小为 M 并含有 \(N=\alpha M\) 个键的基于线性探测的散列表中,基于均匀散列假设,命中和未命中的查找所需的探测次数分别为:~\(\frac{1}{2}(1+\frac{1}{1-\alpha})\) 和 ~\(\frac{1}{2}(1+\frac{1}{{1-\alpha}^{2}})\)。
context
分离链法和线性探测法的详细比较取决于实现的细节和用例对空间和时间的要求。及时基于性能考虑,选择分离链法而非线性探测法也不一定是合理的。在实践中,两种方法的性能差别主要是因为分离链法为每个键值对都分配了一小块内存而线性探测则为整张表使用了两个很大的数组。对于非常大的散列表,这些做法对内存管理系统的要求也很不相同。在现代系统中,在性能优先的情景下,最好由专家去把握这种平衡。
相对二叉查找树,散列表的优点在于代码更简单,且查找时间最优(常熟级别,只要键的数据类型是标准的或者简单到我们可以为它写出满足(或者近似满足)均匀性假设的高效散列函数即可)。二叉查找树相对于散列表的优点在于抽象结构更简单(不需要设计散列函数),红黑树可以保证最坏情况下的性能且它能够支持的操作更多(如排名、选择、排序和范围查找)。在后面的课程我们会遇到另一种情况:当键都是长字符串是,我们可以构造出比红黑树更灵活而又比散列表更加高效的数据结构。
Java 的 java.util.TreeMap 和 java.util.HashMap 分别是基于红黑树和分离链法的散列表的符号表实现。TreeMap 没有直接支持 rank()、select() 和我们的有序符号表 API 中的一些其他方法,但它支持一些能够高效实现这些方法的操作。HashMap 会动态调整数组的大小来保持使用率大约不超过 75%。