第一次接触python,原本C语言的习惯使得我还不是很适应python的语法风格。希望读者能够给出建议。
相关的入门指导来自以下的网址:https://blog.csdn.net/c406495762/article/details/78123502编者的文章很用心,好评。
下面是本次自学的详细说明:
----->确认目标:我选择一个不是很出名的小说网,之所以这么做,是因为一些大网站上一般都有一些反爬虫机制,作为一只弱鸡,还是选个容易上手的小网站。
->穿越小说网->《妖界之门》:http://www.15kxs.com/cbbook_22000/->这是章节汇总
点开第一章:http://www.15kxs.com/cbbook_22000/1.html 对比两个网址再多点开几个网页就很容易发现URL中的规律。但是这里为了更好的熟悉相关代码,我决定进行如下操作:
在章节汇总的网页上提取各个章节的网址并逐一请求,清洗网页源代码得到文章,并将文章汇总到本地的txt文件中。
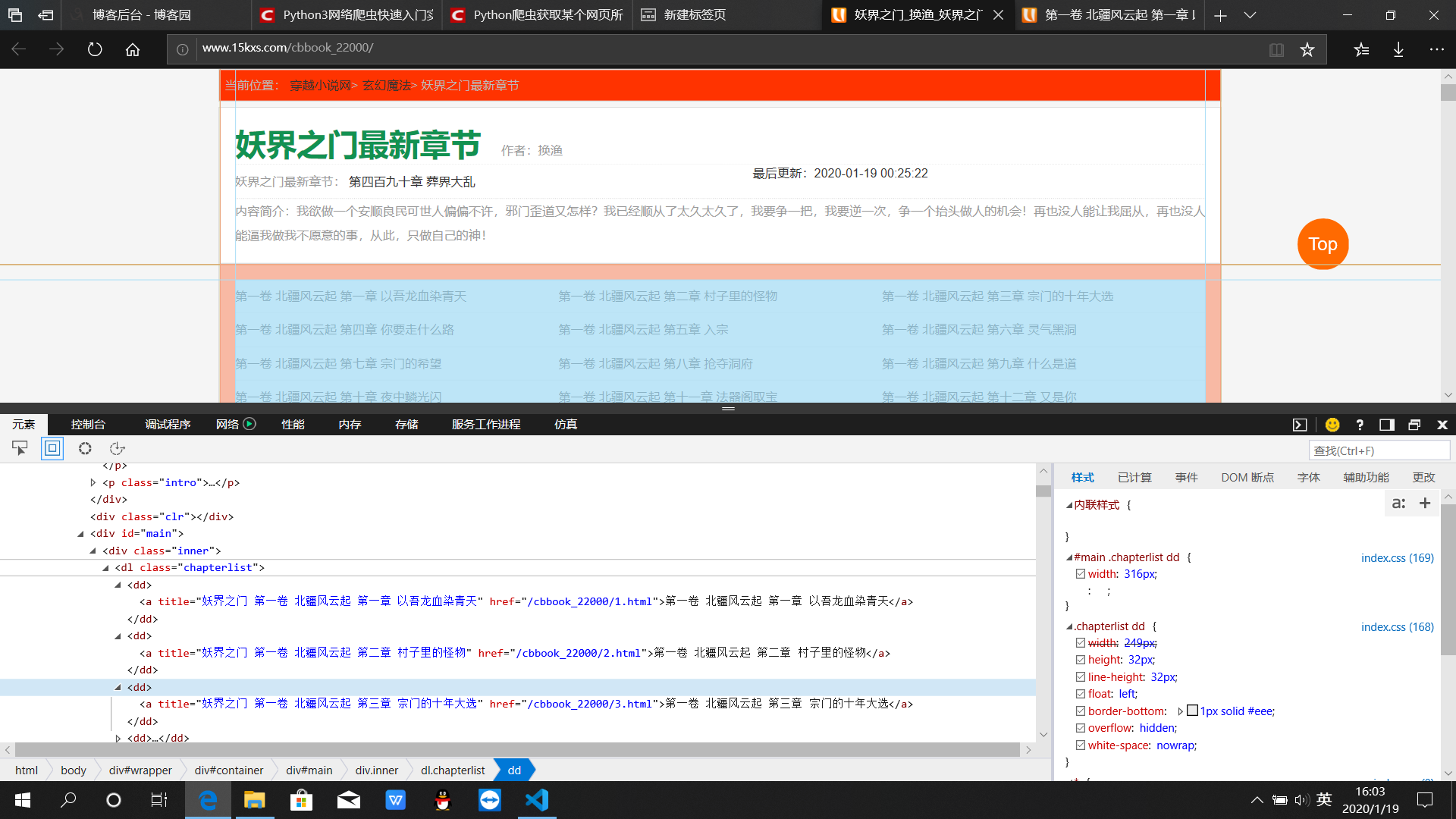
目标是提取<a>中的“href=”的地址
下面是Python代码
1 # -*- coding:UTF-8 -*- 2 from bs4 import BeautifulSoup 3 import requests 4 filename = 'novel.txt' 5 6 if __name__ == "__main__": 7 aim = "http://www.15kxs.com/cbbook_22000/" 8 cyc = requests.get(aim) 9 psd = cyc.text 10 cnt = BeautifulSoup(psd,features="html.parser") 11 clc = cnt.find_all('a') 12 first = 0#在实验过程中发现章节网页中<a>的所有选项中提出的网址不仅仅包括着小说页面,对于其他页面进行筛选 13 for haim in clc: 14 link = haim.get('href') 15 lenth = len(link) 16 if first>2 and lenth!=0 and link[0]=='/': 17 """拿到了每一个章节的链接尾地址""" 18 urlaim="http://www.15kxs.com"+link 19 request_get = requests.get(urlaim) 20 html = request_get.text 21 ctm = BeautifulSoup(html,features="html.parser") 22 tex = ctm.find_all('div',id='BookText') 23 result = tex[0].text.replace('\xa0','')#编码格式是一个难点,能够打印到屏幕上的字符不一定能写入文件 24 with open(filename,'a',encoding='utf-8') as file_object: 25 file_object.write(result) 26 first = first+1#用于计算数量 27 print(str(first)+" is ok") 28 print("all above is ok")
效果如下:
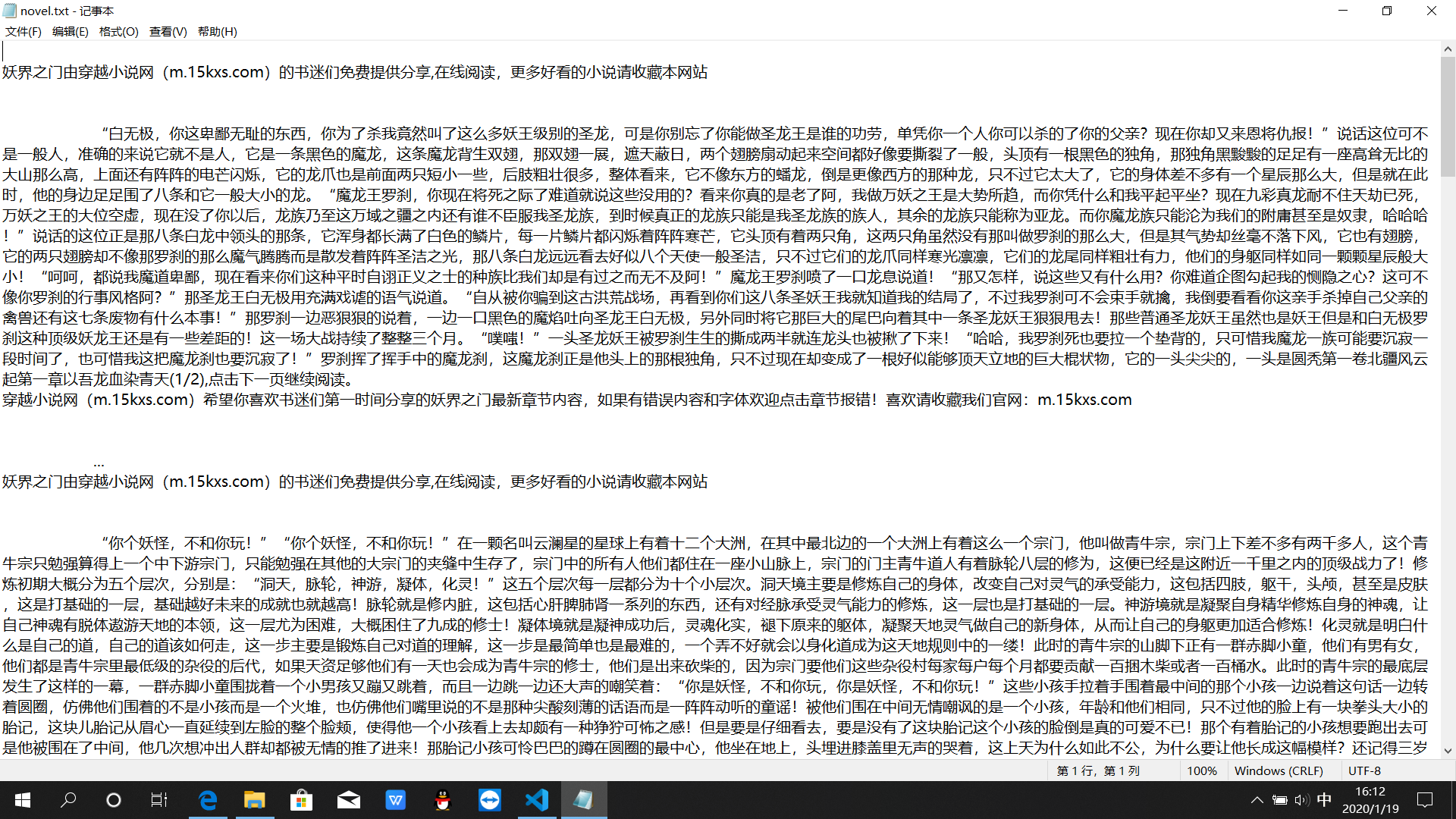
表示效果还可以
唯一不足的是:抽取速度有些慢,5分钟内只能整理110章节左右