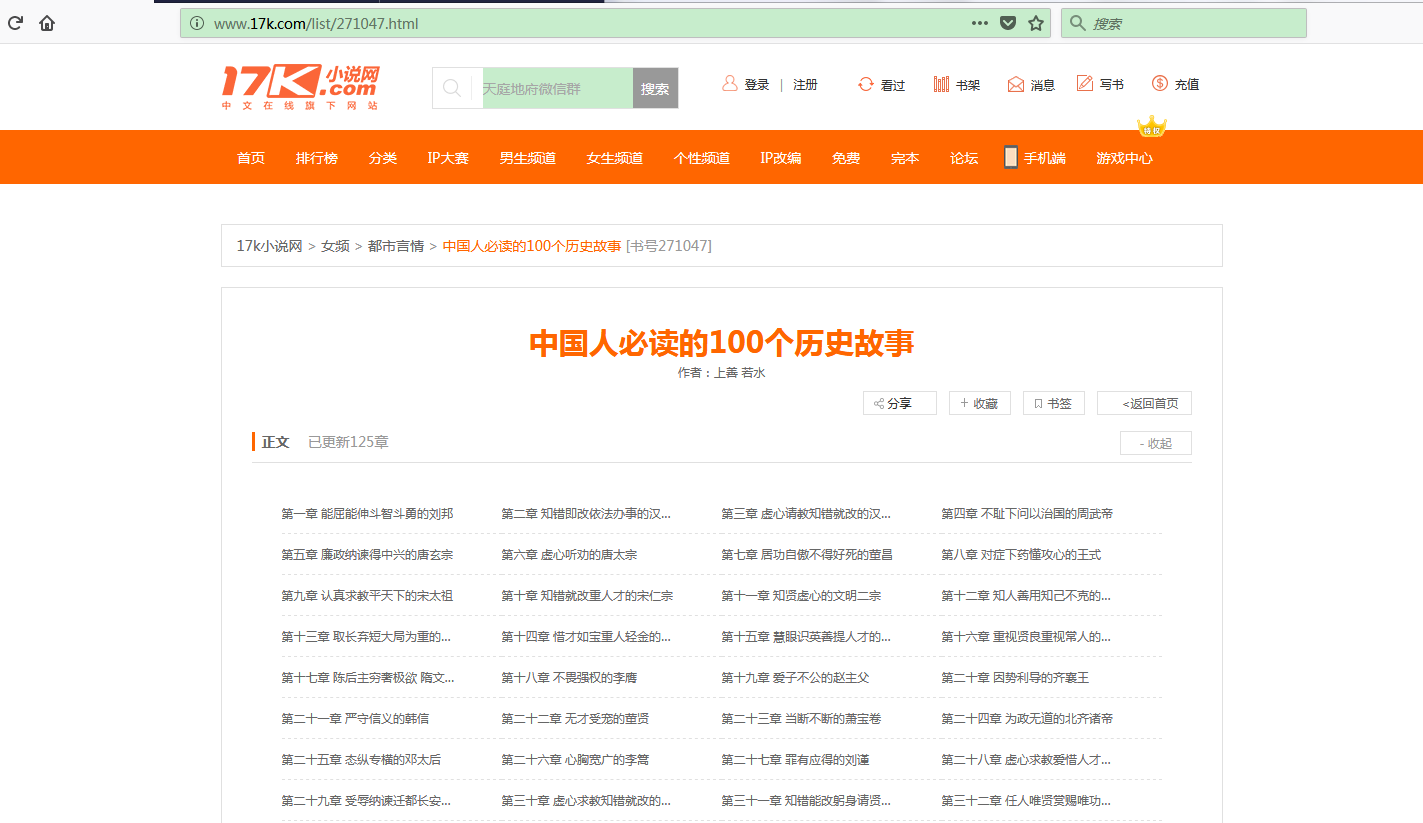
意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源。
 a
a
这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示
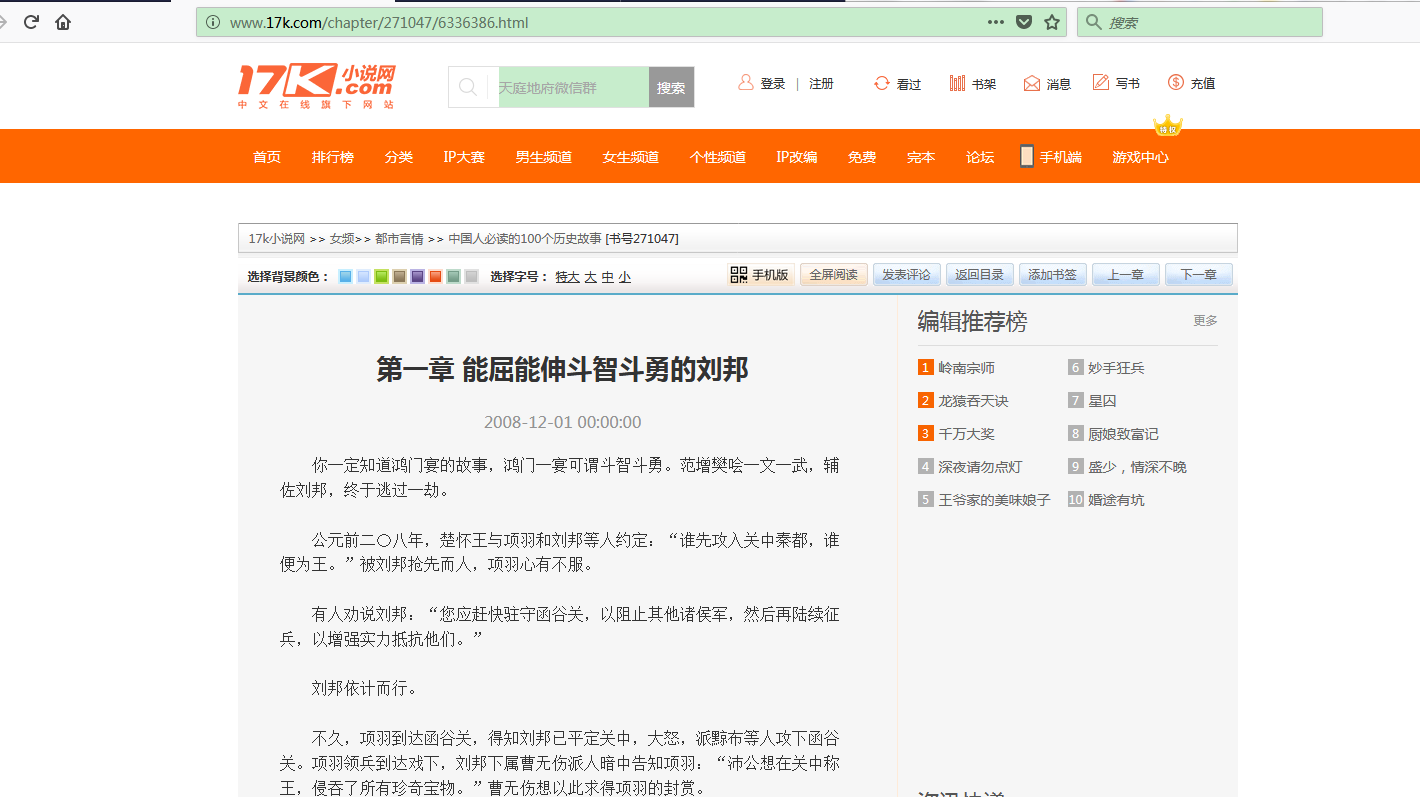
下面直接看代码,有疑问的可以直接留言联系我
# -*- coding: utf-8 -*-
import scrapy
from k17.items import K17Item
import json
class A17kSpider(scrapy.Spider):
name = '17k'
allowed_domains = ['17k.com']
start_urls = ['http://www.17k.com/list/271047.html']
def parse(self, response):
old_url='http://www.17k.com'
#for bb in response.xpath('//div[@class="Main List"]/dl[@class="Volume"]/dd/a/span/text()'):
#print(bb.extract()) #得到题目了(第一章 能屈能伸斗智斗勇的刘邦。。。第一百二十五章 敢于创新的秦孝公)
for bb in response.xpath('//div[@class="Main List"]/dl[@class="Volume"]/dd'):
##把xpath表达式作为normalize-space()函数的参数 此方法可以去除数据的值有\r\n\t
link=bb.xpath("a/@href").extract() ### 得到每一章的链接
#print(type(link)) #这里的link得到是一个list集合
# print(link)
for newurl in link:
#print(old_url+newurl,123334)
new_url=old_url+newurl
yield scrapy.Request(new_url, callback=self.parse_item)
def parse_item(self,response):
#print(response)
for aa in response.xpath('//div[@class="readArea"]/div[@class="readAreaBox content"]'):
#print(aa.xpath("h1/text()").extract(),110) #得到每一章的详细内容
#
item=K17Item()
title=aa.xpath("h1/text()").extract()###得到每一章的标题
#print(title,456)
new_title=(''.join(title).replace('\n','')).strip()
item['title']=new_title
#print(item['title'])
dec= aa.xpath("div[@class='p']/text()").extract()###得到每一章的详细内容
# print(type(dec))
dec_new=((''.join(dec).replace('\n','')).replace('\u3000','')).strip() ###去除内容中的\n 和\u3000和空格的问题
#print(type(dec_new))
item['describe'] = dec_new
#print(dec_new,123)
yield item