输入数据集,分析数据维度,可以看到共有0,1,2,3四个类别。
import pandas as pddf=pd.DataFrame({‘math’:[98,78,54,89,24,60,98,44,96,90],‘english’:[92,56,90,57,46,75,76,87,91,88],‘chinese’:[95,69,91,52,60,80,78,81,96,82],‘rank’:[0,3,2,3,1,1,2,2,0,0]})

导入svm工具包。没有安装sklearn的要先安装svm。
from sklearn import svm
数据准备。本例中数据都是数值型变量,且没有空值,直接取X,y变量。
X=df.ix[:,[‘math’,‘english’,‘chinese’]]
y=df[‘rank’]

建立模型,并进行训练。
clf = svm.SVC()
clf.fit(X, y)

模型预测。有一组新的数据,根据模型预测它的分类,结果为rank=2。
new=[[60,51,98]]
clf.predict(new)

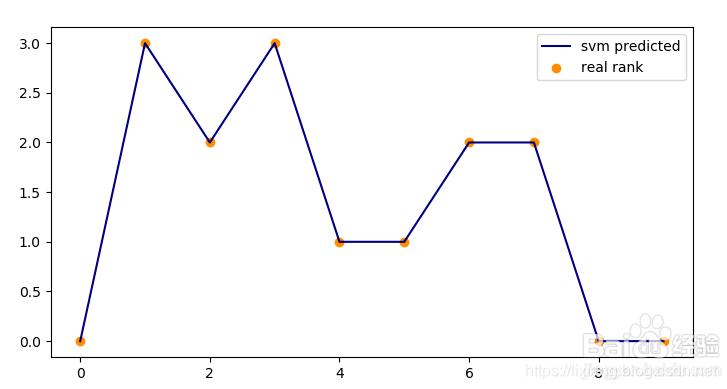
绘制预测效果图。
y_pred=clf.predict(X)
import matplotlib.pyplot as plt
plt.figure()
plt.scatter(range(len(y)),y, color=‘darkorange’, label=‘real rank’)
plt.plot(y_pred, color=‘navy’, label=‘svm predicted’)
plt.legend()
plt.show()
也可以预测数据属于每个类别的概率值。
重新建立模型。
clf = svm.SVC(probability=True)
clf.fit(X,y)
clf.predict_proba(X)

