1 有哪些你熟悉的监督学习和无监督学习算法?
监督学习:线性回归、逻辑回归、支持向量机、神经网络、决策树、贝叶斯
无监督学习:K-均值聚类、PCA
2 生成模型和判别模型的区别?
1、判别式模型评估对象是最大化条件概率p(y|x)并直接对其建模,生成式模型评估对象是最大化联合概率p(x,y)并对其建模。
2、生成式模型可以根据贝叶斯公式得到判别式模型,但反过来不行。
3 线性分类器与非线性分类器的区别以及优劣
线性分类器就是用一个超平面将正负样本分开,
非线性分类器就是用一个“超曲面”将政府样本分开。
优劣:
线性分类器速度快,编程方便,便于理解,拟合能力低。
非线性分类器编程复杂,但拟合效果好。
4 什么是交叉验证,交叉验证如何使用在时间序列上?
交叉验证分为k-hold交叉验证和留一验证。
k-hold验证:
将全部样本划分为k个大小相同的样本子集,依次遍历这k个子集,每次把当前子集作为验证集,其余子集作为训练集。k次评估指标的平均值作为最终的评估指标。
留一验证:
每次留下一个样本作为验证集,其余所有样本作为测试集。
对于时间序列,因为数据的先后是具备相关性的,所以不能随机打乱数据,也就不能使用K-kold验证和留一验证。
可以使用前向链接策略的方法,比如:连续时间的股价为:x_1,x_2,x_3,x_4,x_5,x_6。
fold1:训练数据x_1,测试数据x_2;
fold2:训练数据x_1,x_2,测试数据x_3;
fold1:训练数据x_1,x_2,x_3,测试数据x_4;
……
每个fold的测试数据可以是训练数据之后紧挨的一个,也可以是后边的某一个。
5 分类和回归里有哪些你熟悉的评估准则,分别是什么样的含义
分类指的是训练好的模型将新输入的数据映射到某一标签。
其评估准则有如下几种:
(1) 混淆矩阵
混淆矩阵(confusion matrix)是一个评估分类问题常用的工具,对于 k 元分类,其实它就是一个k x k的表格,用来记录分类器的预测结果
(2) 准确度
准确率(accuracy)是指模型预测正确(包括预测为真正确和预测为假正确)的样本数量占总样本数量的比例。
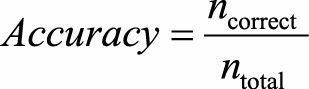
其中n_correct代表的是正确分类的样本个数,n_total表示所有的样本个数。
(3) 精确率
精确率(precision)是指模型预测为真,实际也为真的样本数量占模型预测所有为真的样本数量的比例。
(4) 召回率
召回率(recall)有时候也叫查全率,是指模型预测为真,实际也为真的样本数量占实际所有为真的样本数量的比例。
(5) F1值
精确率和召回率是互斥的,也就是说精确率高的话,召回率会变低;召回率高的话,精确率会变低。F1值是精确率和召回率的调和平均,即
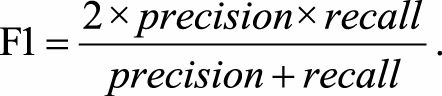
(6)AUC
AUC(Area Under Curve)被定义为ROC曲线下的面积,其物理意义是任取一对样本,正样本score大于负样本的概率。其中ROC曲线将假阳性率(FPR)和真阳性率(TPR)画在同一个坐标轴。
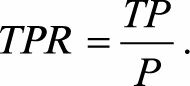
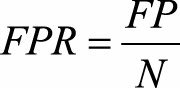
P代表真实的正样本的数量,N代表真实的负样本的数量。
TP代表P个正样本中被分类器预测为正样本的个数,等价于recall。
FP是N个负样本中预测为正样本的个数。
也可以通过Score排序求得AUC。
我们首先把所有样本按照score排序,依次用rank表示他们,如最大score的样本,rank=n (n=n0+n1,其中n0为负样本个数,n1为正样本个数),其次为n-1。那么对于正样本中rank最大的样本,rank_max,有n1-1个其他正样本比他score小,那么就有(rank_max-1)-(n1-1)个负样本比他score小。其次为(rank_second-1)-(n1-2)。最后我们得到正样本大于负样本的概率为
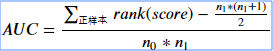
时间复杂度是O(N+M)。
(7) 对数损失
对数损失(Logistic Loss,logloss)是对预测概率的似然估计。
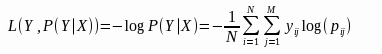
其中, Y 为输出变量, X为输入变量, L 为损失函数. N为输入样本量, M为可能的类别数, yij 是一个二值指标, 表示类别 j 是否是输入实例 xi 的真实类别. pij 为模型或分类器预测输入实例 xi 属于类别 j 的概率。
回归
(1)平均绝对误差(Mean Absolute Error,MAE)
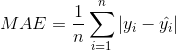
(2)均方误差(Mean Squared Error,MSE)
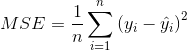
(3)均方根误差(Root Mean Squared Error)
标准差,也称均方差,定义为方差的算术平方根,反映组内个体间的离散程度。
6 对于不均衡的数据分类,我们如何处理
(1)基于数据的方法
对数据进行重采样,使其从不平衡的数据集变成平衡的数据集。
采样分为上采样(Oversampling)和下采样(Undersampling),上采样是把小众类复制多份,下采样是从大众类中剔除一些样本,或者说只从大众类中选取部分样本。
(2)基于算法的方法
通过改变模型训练时的目标函数(如代价敏感学习中不同类别有不同的权重)来矫正这种不平衡性。当样本数据极不均衡时,也可将问题转化为单类学习、异常检测。
7 如何检测异常值?
(1)基于模型的技术
许多异常检测技术首先建立一个模型,异常是那些同模型不能完美拟合的对象。比如,数据分布的模型可以通过估计概率分布的参数创建,如果一个对象不服从该分布,则认定为异常值。
(2)基于邻近度的技术
通常在对象之间定义邻近性度量,异常对象是那些远离大部分其他对象的对象。
(3)基于密度的技术
对象的密度估计可以相对直接计算,特别是当对象之间存在邻近性度量。低密度区域中的对象相对远离近邻,可能被看做为异常。
8 遇到缺失值,我们有哪些处理方法?
(1)删除法
简单删除法:此方法将存在缺失值的数据条目(对象,元组,记录)进行删除
权重法:当缺失值的类型为非完全随机缺失的时候,可以通过对完整的数据加权来减小偏差。把数据不完全的个案标记后,将完整的数据个案赋予不同的权重
(2)填补法:
特殊值填写
均值填写
出现次数最多的值填写等
9 你了解哪些特征工程的处理?
(1)归一化将数据归一化到一个数量级范围内,消除数据之间不同量纲的影响。
(2)类别性特征转换成编码形式
(3)图像数据不足时的处理方法,比如图像平移、变换、旋转、特征空间变换等。
(4)特征提取,比如降维算法PCA。
10 逻辑回归中为何选择sigmoid函数,这个函数有什么特点?
函数图像如下:

(1)将数据压缩到[0,1]之间。
(2)导数形式良好,方便计算。
对于分类问题,经过sigmoid函数的值,如果大于等于0.5,判为类别1,如果小于0.5,判为类别0,适用于分类任务。
11 逻辑回归中用到的损失函数是什么函数,能求一下它的梯度吗?
交叉熵损失函数,定义如下:

求解梯度过程如下:

12 讲解一下决策树的建模方法,对于连续值属性它是如何处理的?
建模方法
(1)基于最大增益比
(2)基于最大增益率
(3)基于最大基尼指数
连续值处理
因为连续属性的可取值数目不再有限,因此不能像处理离散属性枚举离散属性取值来对结点进行划分。因此需要连续属性离散化,常用的离散化策略是二分法。

13 随机森林是一个什么模型?
随机森林是bagging的一个扩展,也是并行训练的模型。
随机森林采用多个决策树的投票机制来改善决策树,我们假设随机森林使用了m棵决策树,那么就需要产生m个一定数量的样本集来训练每一棵树,如果用全样本去训练m棵决策树显然是不可取的,全样本训练忽视了局部样本的规律,对于模型的泛化能力是有害的。
产生n个样本的方法采用Bootstraping法,这是一种有放回的抽样方法,产生n个样本,
而最终结果采用Bagging的策略来获得,即多数投票机制。
(1)从样本集中通过重采样的方式产生n个样本。
(2)假设样本特征数目为a,对n个样本选择a中的k个特征,用建立决策树的方式获得最佳分割点。
(3)重复m次,产生m棵决策树。
(4)多数投票机制来进行预测。
14 你了解哪些boosting的模型,Xgboost的原理是什么?
Adaboost
GBDT
XGBoost
XGBoost原理
在函数空间内利用牛顿法最优化损失函数(待补充,不太懂)
15 Xgboost和GBDT的主要区别是什么?
(1)使用CART作为基分类器时,XGBoost加入了正则项来控制模型的复杂度,利于防止过拟合。
(2)GBDT在模型训练时只使用了代价函数的一阶导数信息,XGBoost对代价函数做二阶泰勒展开,同时使用了一阶和二阶导数。
(3)GBDT采用CART作为基分类器,XGBoost支持多种类型的基分类器,比如线性分类器。
(4)GBDT在每次迭代时使用全部的数据,XGBoost采用了与随机森林相似的策略,支持对数据进行采样。
(5)GBDT没有涉及对缺失值进行处理,XGBoost能自动学习出缺失值的处理策略。
16 Xgboost如何处理多分类问题?
应用softmax回归方法,
对于k分类问题,每一轮迭代中,是构建了k个树,每一颗树的预测值代表对每个分类的打分,记为fk(x),那么其loss就是对应的softmax的loss。
17 Xgboost的缺失值处理逻辑是什么样的?
在寻找split point的时候,不会对该特征为missing的样本进行遍历统计,只对该列特征值为non-missing的样本上对应的特征值进行遍历,通过这个技巧来减少了为稀疏离散特征寻找split point的时间开销。
在逻辑实现上,为了保证完备性,会分别处理将missing该特征值的样本分配到左叶子结点和右叶子结点的两种情形,计算增益后选择增益大的方向进行分裂即可。
如果在训练中没有缺失值而在预测中出现缺失,那么会自动将缺失值的划分方向放到右子树。

18 Xgboost如何计算特征重要度?
有三种方法:
weight - 该特征在所有树中被用作分割样本的特征的次数。
gain - 在所有树中的平均增益。
cover - 在树中使用该特征时的平均覆盖范围
19 怎么判断模型过拟合,缓解模型过拟合的方法有哪些?
数据在训练数据上表现良好,在测试数据上表现差,就是过拟合。
缓解过拟合有以下几个方法:
(1)增加训练数据
(2)降低模型复杂度,比如卷积神经网络的变形-残差网络,树的剪枝。
(3)加入正则约束项,对模型复杂度进行惩罚。其本质也是降低模型复杂度
(4)集成学习方法,比如 bagging。
20 L1和L2正则化的区别是什么,如何理解?
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择。
L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
21 CNN的不同层次处理和功能介绍?
输入层:接收数据的输入,在CNN的输入层中,(图片)数据输入的格式 与 全连接神经网络的输入格式(一维向量)不太一样。CNN的输入层的输入格式保留了图片本身的结构。
卷积层:使用卷积核进行特征提取和特征映射。
激励层:激励层主要对卷积层的输出进行一个非线性映射,因为卷积层的计算还是一种线性计算。使用的激励函数一般为ReLu函数,卷积层和激励层通常合并在一起称为“卷积层”。
池化层:进行下采样,对特征图稀疏处理,减少数据运算量,起到降维的作用。
输入经过卷积层时,若感受视野比较小,布长stride比较小,得到的feature map (特征图)还是比较大,可以通过池化层来对每一个 feature map 进行降维操作,输出的深度还是不变的,依然为 feature map 的个数(通道数不变,变得是图片的长、宽)。
全连接层:通常在CNN的尾部进行重新拟合,减少特征信息的损失
输出层:用于输出结果。
22 CNN里的1*1卷积有什么作用?
(1)降维,这里降低的是图片的通道数。比如,一张500 * 500且厚度depth为100 的图片在20个filter上做11的卷积,那么结果的大小为50050020。
(2)加入非线性。卷积层之后经过激励层,11的卷积在前一层的学习表示上添加了非线性激励( non-linear activation ),提升网络的表达能力;
(3)跨通道信息交互(channal 的变换)。33,64channels的卷积核前面添加一个11,28channels的卷积核,就变成了3*3,28channels的卷积核,原来的64个channels就可以理解为跨通道线性组合变成了28channels,这就是通道间的信息交互。
23 残差网络的残差模块是什么样的?
残差模块如下:

输入x经过两个神经网络的变换得到F(x),同时也短接到两层之后,最后这个包含两层的神经网络模块输出H(x) = F(x) + x。这样结果是F(x)被设计为只需要拟合输入x与目标输出H(x)的残差H(x) - x。
24 LSTM为什么能缓解梯度弥散问题?
LSTM是RNN的变体,对于RNN来说,由于预测的误差是沿着神经网络的每一层反向传播的,因此当雅克比矩阵的最大特征值大于1时,随着离输出越来越近,每层的梯度大小会呈指数级增长,导致梯度爆炸,反之,当雅克比矩阵的最大特征值小于1时,每层的梯度大小会呈指数级减小,产生梯度消失。
LSTM就是通过引入一个叫做“门”(gating)的机制来缓解梯度消失问题。(具体公式推导还没搞清楚,待补充)
附加
25 选用TPR和FPR作为ROC/AUC的指标的原因
TPR和FPR分别是基于实际表现1和0出发的,也就是说它们分别在实际的正样本和负样本中来观察相关概率问题,所以无论样本是否平衡,都不会被影响。
