一,SVM(Support Vector Machine)支持向量机
a. SVM算法是介于简单算法和神经网络之间的最好的算法。
b. 只通过几个支持向量就确定了超平面,说明它不在乎细枝末节,所以不容易过拟合,但不能确保一定不会过拟合。可以处理复杂的非线性问题。
c. 高斯核函数
d. 缺点:计算量大
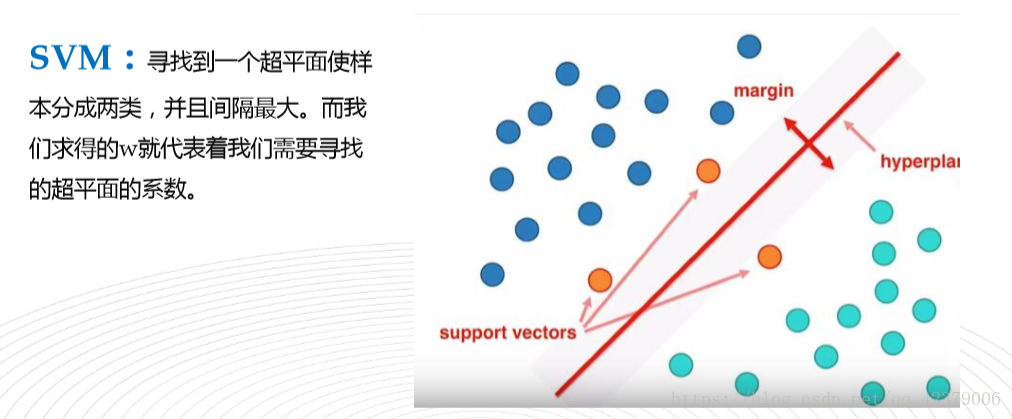
二,决策树(有监督算法,概率算法)
a. 只接受离散特征,属于分类决策树。
b. 条件熵的计算 H(Label |某个特征) 这个条件熵反映了在知道该特征时,标签的混乱程度,可以帮助我们选择特征,选择下一步的决策树的节点。
c. Gini和entropy的效果没有大的差别,在scikit learn中默认用Gini是因为Gini指数不需要求对数,计算量少。
d. 把熵用到了集合上,把集合看成随机变量。
e. 决策树:贪心算法,无法从全局的观点来观察决策树,从而难以调优。
f. 叶子节点上的最小样本数,太少,缺乏统计意义。从叶子节点的情况,可以看出决策树的质量,发现有问题也束手无策。
优点:可解释性强,可视化。缺点:容易过拟合(通过剪枝避免过拟合),很难调优,准确率不高
g. 二分类,正负样本数目相差是否悬殊,投票机制
h. 决策树算法可以看成是把多个逻辑回归算法集成起来。
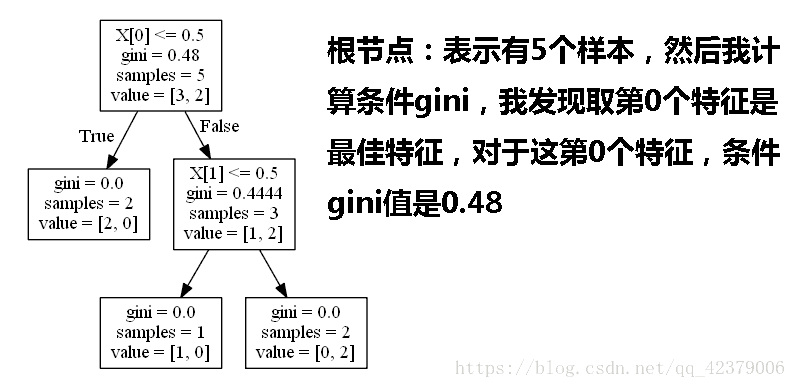
三,随机森林(集成算法中最简单的,模型融合算法)
随机森林如何缓解决策树的过拟合问题,又能提高精度?
a. Random Forest, 本质上是多个算法平等的聚集在一起。每个单个的决策树,都是随机生成的训练集(行),随机生成的特征集(列),来进行训练而得到的。
b. 随机性的引入使得随机森林不容易陷入过拟合,具有很好的抗噪能力,有效的缓解了单棵决策树的过拟合问题。
c. 每一颗决策树训练样本是随机的有样本的放回抽样。
四,逻辑回归(线性算法)
它是广义线性模型GLM的一种,可以看成是一个最简单的神经网络,损失函数是一个对数似然函数,损失函数的值越大越好。(梯度上升法)
a. 多次训练,多次测试,目的是看逻辑回归这个算法适不适合这个应用场景。
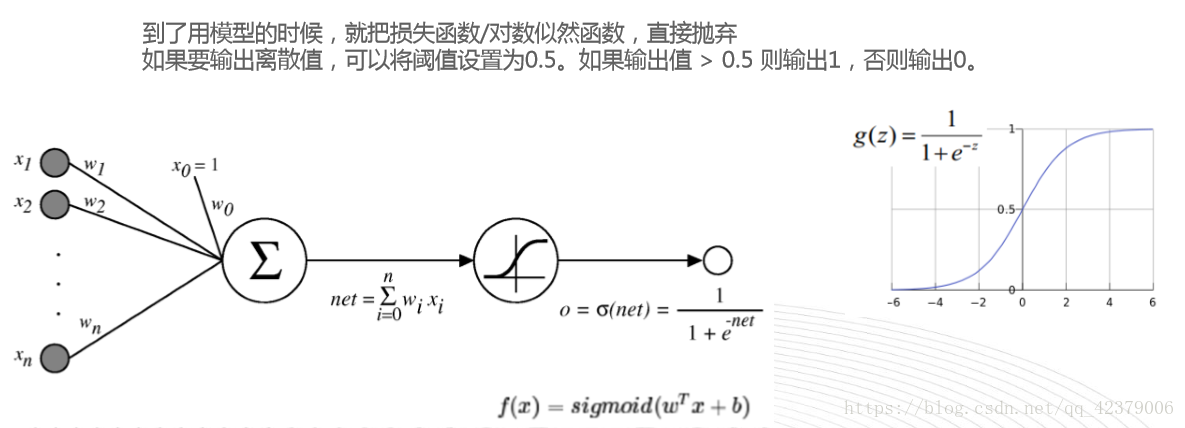
五,朴素贝叶斯
应用场景:源于推理的需要,例如:通过商品的描述(特征X)来推理商品的类别(Y)。
“朴素”:特征与特征之间是独立的,互不干扰。如果特征比较多时,往往独立性的条件不重要(互相抵消),可以用朴素贝叶斯。
训练的时候:得出条件概率表
推理的时候:比较条件概率的大小
特点:训练容易,推理难
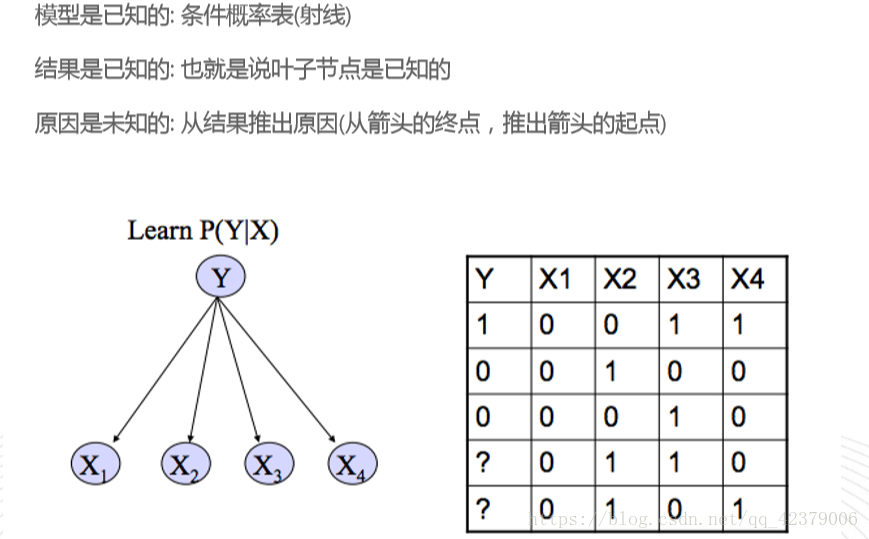
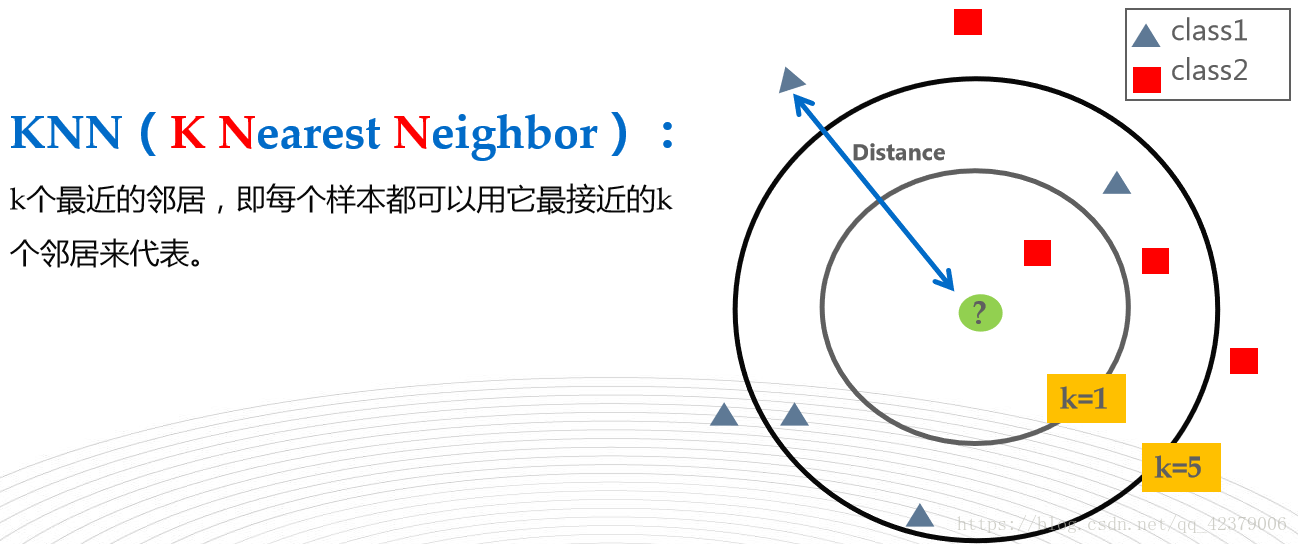
六,KNN(K Nearest Neighbor) K近邻(有监督算法,分类算法)
K表示K个邻居,不表示距离,因为需要求所有邻居的距离,所以效率低下。
优点:可以用来填充缺失值,可以处理非线性问题
调优方法:K值的选择,k值太小,容易过拟合
应用:样本数少,特征个数较少,kNN更适合处理一些分类规则相对复杂的问题,在推荐系统大量使用
KNN算法和贝叶斯算法有某种神秘的联系,用贝叶斯算法估算KNN的误差。
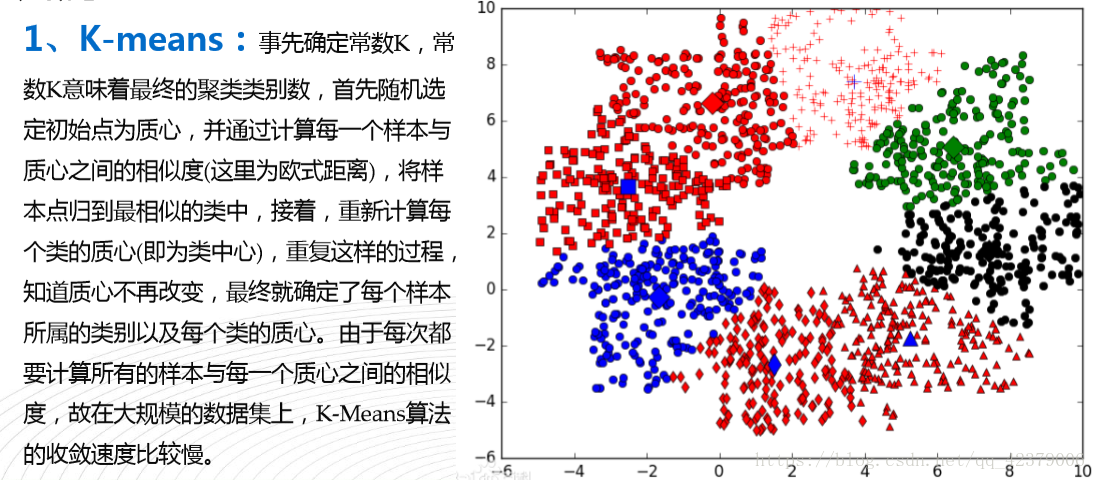
七,K-means K均值(无监督算法,聚类算法,随机算法)
a. 最常用的无监督算法
b. 计算距离方法:欧式距离,曼哈顿距离
c. 应用:去除孤立点,离群点(只针对度量算法);可以离散化
d. 最常用归一化预处理方法
f. k-means设置超参数k时,只需要设置最大的k值。
g. k-means算法最终肯定会得到稳定的k个中心点,可以用EM(Expectation Maximum)算法解释
h. k-means算法k个随机初始值怎么选? 多选几次,比较,找出最好的那个
i. 调优的方法:1. bi-kmeans 方法(依次“补刀”)
j. 调优的方法:2. 层次聚类(逐步聚拢法)k=5 找到5个中心点,把中心点喂给k-means。初始中心点不同,收敛的结果也可能不一致。
k. 聚类效果怎么判断?用SSE误差平方和指标判断,SSE越小越好,也就是肘部法则的拐点处。也可以用轮廓系数法判断,值越大,表示聚类效果越好,簇与簇之间距离越远越好,簇内越紧越好。
l. k-means算法最大弱点:只能处理球形的簇(理论)
八,集成算法
为什么使用集成算法
简单算法一般复杂度低,速度快,易展示结果,但预测效果往往不是特别好。每种算法好像一种专家,集成就是把简单的算法(后文称基算法/基模型)组织起来,即多个专家共同决定结果。
如何组织算法和数据
这里我们的着眼点不是某个算法,某个函数,而是对数据和算法整体的规划。
从数据拆分的角度看:可以按行拆分数据,也可以按列给属性分组。
从算法组合的成份看:可以集成不同算法,也可以集成同一算法不同参数,还可以集成同一算法使用不同数据集(结合数据拆分)。
从组合的方式看:可以选择少数服从多数,或加权求合(可根据正确率分配权重)。
从组合的结构看:可以是并行,串行,树型或者更复杂。
综上,我们看到了各种构造集成的方法,这里面可选的组合太多,不可能一一尝试,目前拼的还是人的经验:对数据的理解,对算法的组织,以及对工具的驾驶能力。在使用集成算法的过程中,除了调库,调参,更重要的是领会精神。也可以自己编写一些集成算法。
三个臭皮匠顶个诸葛亮
三个臭皮匠是否能顶诸葛亮,这还得具体问题,具体分析。如果基算法选错了,即使再怎么组合,再怎么调参也没用。但有些问题确实可以拆开看,达到1+1>2的效果,比如说,用线性函数去拟合曲线,效果不好,但是如果用分段线性函数,效果还不错。分段线性函数就可看作线性函数的集成(把数据横着拆开了),只不过这种集成要比直接调集成函数复杂一些。
分段线性拟合
一般来说集成的会比不集成效果好,但集成的过程也会增加复杂度。
常用的集成算法
集成算法一般分为三类:Bagging,Boosting,Stacking(我们可以把它简单地看成并行,串行和树型)。Bagging是把各个基模型的结果组织起来,取一个折中的结果;Boosting是根据旧模型中的错误来训练新模型,层层改进;Stacking是把基模型组织起来,注意不是组织结果,而是组织基模型本身,该方法看起来更灵活,也更复杂。
1. Bagging(自举汇聚法)
Bagging的全称是bootstrap averaging,它把各个基模型的结果组织起来,具体实现也有很多种类型,以sklearn中提供的Bagging集成算法为例:
BaggingClassifier/BaggingRegressor是从原始数据集抽选S次(抽取实例,抽取属性),得到S个新数据集(有的值可能重复,有的值可能不出现)。使用同一模型,训练得到S个分类器,预测时使用投票结果最多的分类。
RandomForestClassifier随机森林,它是对决策树的集成,用随机的方式建立一个决策树的森林。当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行判断,预测时使用投票结果最多的分类,也是少数服从多数的算法。
VotingClassifier,可选择多个不同的基模型,分别进行预测,以投票方式决定最终结果。
Bagging中各个基算法之间没有依赖,可以并行计算,它的结果参考了各种情况,实现的是在欠拟合和过拟合之间取折中。
2. Boosting(提升法)
Boosting不断的建立新模型,而新模型更重视上一个模型中被错误分类的样本,最终根据按成功度加权组合得到结果。
由于引入了逐步改进的思想,重要属性会被加权,这也符合人的直觉。一般来说,它的效果会比Bagging好一些。由于新模型是在旧模型的基本上建立的,因此不能使用并行方法训练,并且由于对错误样本的关注,也可能造成过拟合。常见的Boosting算法有:
AdaBoost自适应提升算法,它对分类错误属性的给予更大权重,再做下次迭代,直到收敛。AdaBoost是一个相对简单的Boosting算法,可以自己写代码实现,常见的做法是基模型用单层分类器实现(树桩),桩对应当前最适合划分的属性值位置。
Gradient Boosting Machine(简称GBM)梯度提升算法,它通过求损失函数在梯度方向下降的方法,层层改进,sklearn中也实现了该算法:GradientBoostingClassifier/GradientBoostingRegressor。GBM是目前非常流行的一类算法,在后面详细说明。
3. Stacking
Stacking训练一个模型用于组合(combine)其他各个基模型。具体方法是把数据分成两部分,用其中一部分训练几个基模型A1,A2,A3,用另一部分数据测试这几个基模型,把A1,A2,A3的输出作为输入,训练组合模型B。注意,它不是把模型的结果组织起来,而把模型组织起来。理论上,Stacking可以组织任何模型,实际中常使用单层logistic回归作为模型。Sklearn中也实现了stacking模型:StackingClassifier
梯度提升算法(GB**)
Gradient Boosting Machine(GBM)梯度提升算法是目前比较流行的数据挖掘模型,它是泛化能力较强的算法,常用于各种数据挖掘比赛之中。常用的工具有XGBoost,LightGBM,sklearn提供的GradientBoostingClassifier等等。GBM常把决策树作为基模型,我们常看到的GBDT梯度提升决策树,一般也是指该算法。
通常我们使用GBM都是直接调库,所以我们关注的是:什么时候用它,选用哪个GBM库,给它什么样的数据,以及具体调参。
GBM的原理是希望通过集成基模型使得模型总体的损失函数在梯度方向上下降(梯度下降具体见《深度学习——BP神经网络》篇),模型不断改进。
在调参方面,作为梯度下降算法,我们也需要在参数中指定学习率(每次迭代改进多少),误差函数(在回归问题中判断预测值与实际值的差异);是与决策树结合时,还需要指定树的大小;另外还要设置迭代的次数,每次抽取样本的比例等等。
在选库方面,sklearn中提供的GradientBoostingClassifier是GBM最基本的实现,同时还提供了图形化工具,让开发者对GBM中的各属性有直观理解。不过Sklearn是一个算法集,不是专门做GBM的。
Feature
XGBoost(eXtreme Gradient Boosting)是一个单独的工具包,对GBDT做了一些改进:比如加入线性分类器的支持,正则化,对代价函数进行了二阶泰勒展开,缺失值处理,提高了效率,支持分布式计算等等。
LightGBM(Light Gradient Boosting Machine)同样是一款基于决策树算法的分布式梯度提升框架。相对于XGBoost,速度又有提高,并且占用内存更少。
几个工具的比较详见《关于树的几个ensemble模型的比较(GBDT、xgBoost、lightGBM、RF)》
