目标检测系列(五):R-FCN
References:
《R-FCN:ObjectDetectionvia Region-basedFullyConvolutionalNetworks》
STAR
S: 图片分类任务与目标检测任务性质是有所差异的:分类任务想要的是对于变换的不变性(Translation invariance),也就是说不管这个类别的东西在图片的那个位置,对分类的结果不应该产生影响。检测任务想要的是对于变换的敏感性(Translation variance),因为需要知道物体到底在哪里。 但是卷积的层数越深,不变性就越强,敏感性就会变弱。所以Faster R-CNN的结构并不适合新形态的CNN。
T: 如何适应全卷积化的CNN结构?解决目标检测中位置敏感性问题。
A: 位置敏感分值图(Position-sensitive score maps) + 位置敏感池化(Position-sensitive RoI pooling)
R: 解决了“分类网络的位置不敏感性(translation-invariance in image classification)”与“检测网络的位置敏感性(translation-variance in object detection)”之间的矛盾,在提升精度的同时利用“位置敏感得分图(position-sensitive score maps)”提升了检测速度。
补充:
用于图像分类的基础CNN模型,有一个旧形态与新形态的区分,基于旧形态的CNN结构如AlexNet,VGG,Network-in-Network,ZF-Net等等,它们都有一个特点是卷积之后保留了几层用于逻辑判断的全连接网络(参数量巨大)。所以新形态的CNN呈现全卷积化的趋势,比如ResNet,GoogleNet,DenseNet等等,而且最后一层一般采用全局池化而不是全尺寸卷积,这样一来可以在尽量减少参数的情况下增加网络的深度。
现在问题是网络越深,越会位置不敏感。而且在faster 系列中,位置敏感性体现在ROI对应的特征图自己进行的全连接。所以在新形态的CNN中,如果将所有的卷积层用于卷积共享提取特征,那就会导致位置不敏感性,这样精度就会比较低。但是如果将一部分卷积挪到ROI pooling 后, 又会使测试速度大大增加(因为卷积最耗时), 所以怎么平衡精度和速度是急需解决的问题。
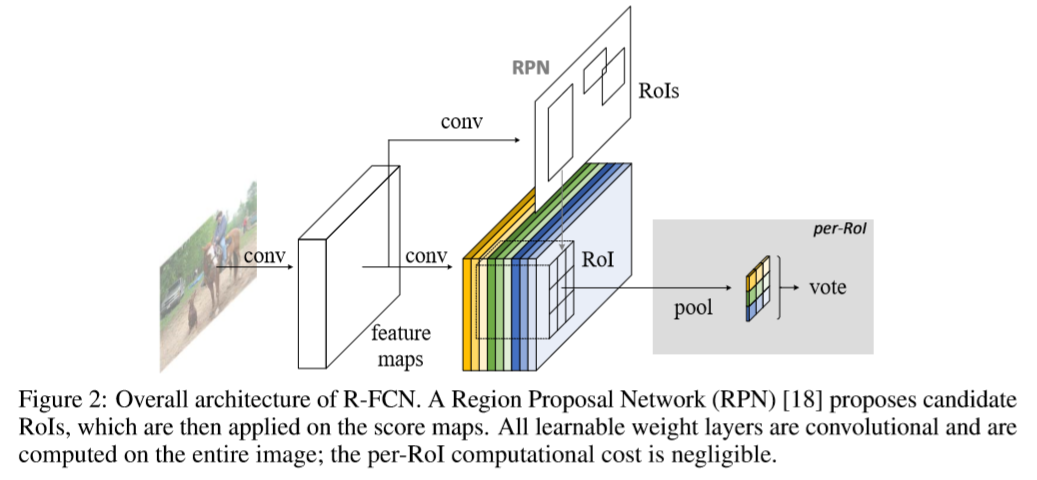
1. R-FCN 网络
2. 位置敏感得分图
3. 位置敏感池化
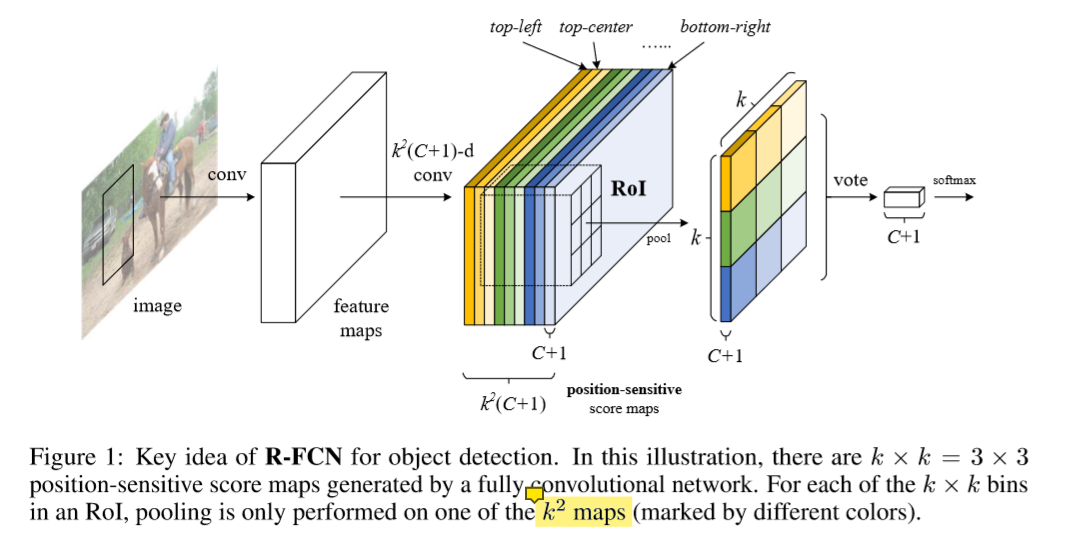
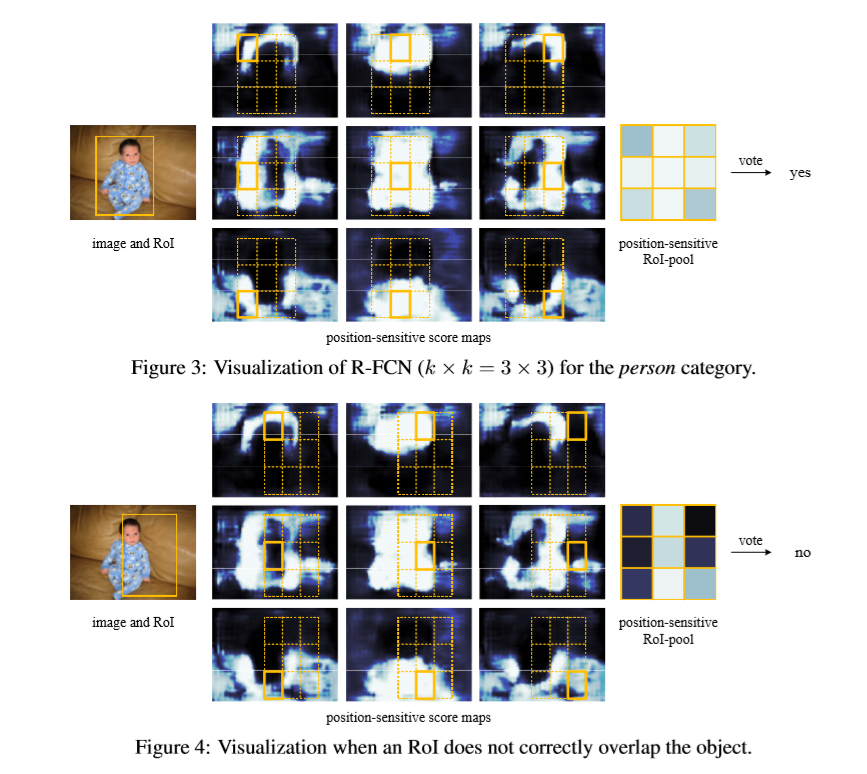
C+1 个类别代表有一个是背景类。其中每一个类都可以有k^2个特征图。当k=3时,分别代表上左,上中,上右,中左,中中,中右,下左,下中,下右。以人为例,对于上中特征图来说,应该头部对应位置响应值最高,其他部位对应位置响应值应该接近为0, 对于下左特征图来说,应该左脚对应位置响应值最高,其他部位对应位置响应值应该接近为0。现在有一个ROI区域,为了得到k^2 个对应区域,就会将此RoI会分成 k * k 个bins(也就是子区域。每个子区域bin的长宽分别是 h/k和 w/k ),每个bin都对应到score map上的某一个区域(上图已经很明显的画出来了)。因此,当我找上左这个bin 对应的相应值时,我就要上左这个特征图去找,然后这个bin 对应的区域进行平均池化,得到的值就是我上左这个bin 的值(代表着bin 只根据其位置在对应特征图的对应位置找,然后平均池化),这样我每一类都可以得到 k * k 个分数,将这k * k 个分数想加,就是这个ROI在这一类得到的分数。因此我共得到C+1个分数,此时将这 C+1 个数使用简单的softmax函数就可以得到属于各个类别的概率了。
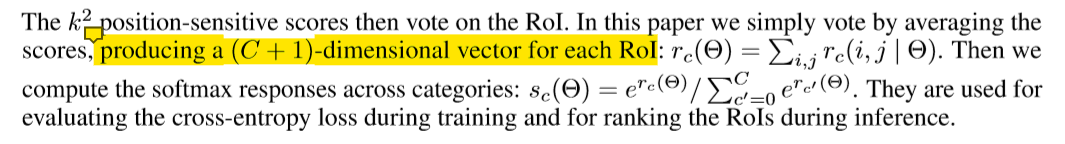
4. 位置敏感回归
按照“position-sensitive score map”+“Position-sensitive RoI pooling”思路,其会让每一个RoI得到 C+1 个数作为每个类别的score,那么现在每个RoI还需要 4 个数作为“回归的偏移量”,也就是“坐标和长宽”的偏移量,所以仿照分类设计的思想,还需要一个类似于position-sensitive score map的用于回归的score map。那么现在就这样设计:在ResNet的共享卷积层的最后一层上,接上一个与position-sensitive score map并行的(sibling)score maps,该score maps用于regression,暂且命名为“regression score map”,而该regression score map的维度应当是 4k^2 ,那么在经过Position-sensitive RoI pooling操作后,每一个RoI就会得到 4 个数作为“该RoI的坐标和长宽的偏移量”了。
5. R-FCN 损失函数
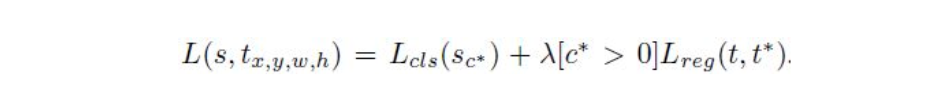
6. R-FCN 训练和测试过程
- 训练过程:
R-FCN训练的步骤与Faster R-CNN相同,同样是分步训练法,只是把Fast R-CNN换成了R-FCN。
此外,文章提出了一个叫做OHEM(Online Hard Example Mining)的训练技巧:
当一个图片生成N个区域建议后,会使用当前的网络一次计算所有N个区域的loss,并根据loss从大到小排序建议区域,并从这N个排序后的区域中取前Batch-size个。这是因为,如何某区域的loss更大,那么说明网络中的参数并没有照顾到这种特征,而这种特征应该是被学习到的,如果把本来loss就很小的特征在送入网络中参与训练,对参数的更新也没啥影响。 - 测试过程:
在测试的时候,为了减少RoIs的数量,作者在RPN提取阶段就将RPN提取的大约2W个proposals进行过滤:
- 去除超过图像边界的proposals
- 使用基于类别概率且阈值IoU=0.7的NMS过滤
- 按照类别概率选择top-N个proposals
所以在测试的时候,一般只剩下300个RoIs,当然这个数量是一个超参数。并且在R-FCN的输出300个预测框之后,仍然要对其使用NMS去除冗余的预测框。
7. R-FCN 性能评价
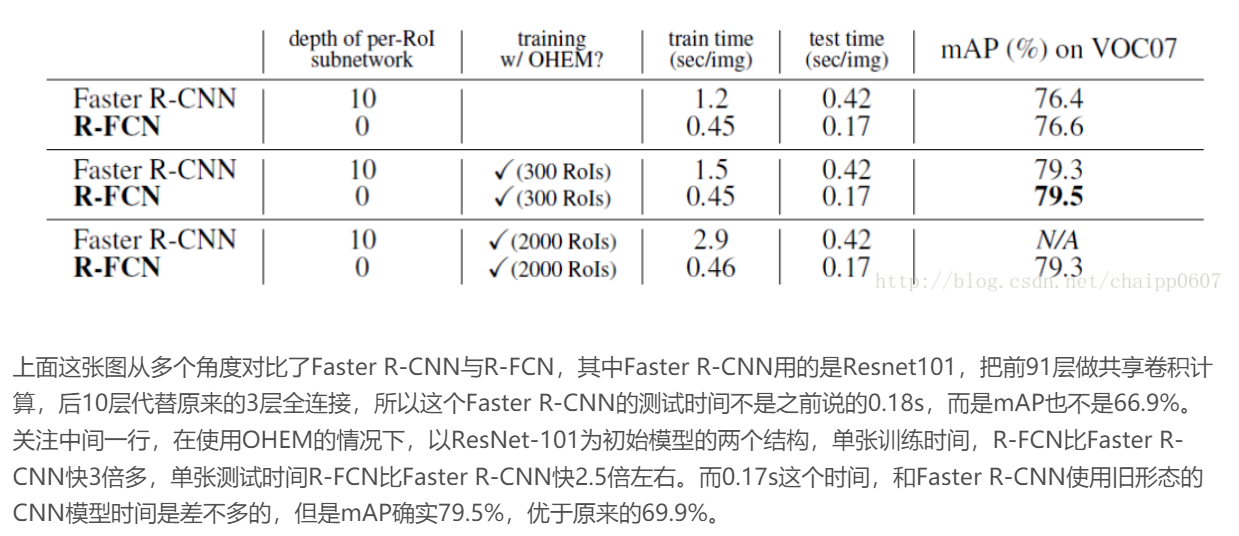
可以看到,Faster R-CNN 采用这个方法后,在提高精度的同时(原来时66.9%), 降低了速度(原来是0.18秒)。但是R-FCN很明显的既提高了精度,又提高了速度。
如需转载请注明出处, 谢谢!