基于深度学习的目标检测算法综述(一):https://blog.csdn.net/weixin_36835368/article/details/82687919
目录
1.1 R-FCN:Object Detection via Region-based Fully Convolutional Networks
1.2-FCN-3000 at 30fps: Decoupling Detection and Classification
1、Two stage
Faster R-CNN 网络包括两个步骤:
1. 使用RPN(region proposal network)提取 proposal 信息;
2. 使用 R-CNN 对候选框位置进行预测和物体类别识别。
这里主要介绍在 Faster R-CNN 基础上改进的几篇论文:R-FCN、R-FCN3000 和 Mask R-CNN。R-FCN 系列提出了 Position Sensitive(ps)的概念,提升了检测效果。另外需要注明的是,虽然 Mask R-CNN 主要应用在分割上,但该论文和 Faster R-CNN 一脉相承,而且论文提出了 RoI Align 的思想,对物体检测回归框的精度提升有一定效果,故本篇综述也介绍了这篇论文。
1.1 R-FCN:Object Detection via Region-based Fully Convolutional Networks
论文链接:arxiv.org/abs/1605.06409
开源代码:github.com/daijifeng001/R-FCN
录用信息:CVPR2017
论文目标
对预测特征图引入位置敏感分数图提增强征位置信息,提高检测精度。
核心思想
背景
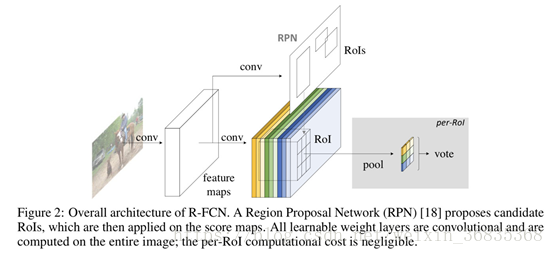
Faster R-CNN 是首个利用 CNN 来完成 proposals 的预测的,之后的很多目标检测网络都是借助了 Faster R-CNN 的思想。而 Faster R-CNN 系列的网络都可以分成 2 个部分:
1.Fully Convolutional subnetwork before RoI Layer
2.RoI-wise subnetwork
第 1 部分就是直接用普通分类网络的卷积层来提取共享特征,后接一个 RoI Pooling Layer 在第 1 部分的最后一张特征图上进行提取针对各个 RoIs 的特征图,最后将所有 RoIs 的特征图都交由第 2 部分来处理(分类和回归)。第二部分通常由全连接层组层,最后接 2 个并行的 loss 函数:Softmax 和 smoothL1,分别用来对每一个 RoI 进行分类和回归。由此得到每个 RoI 的类别和归回结果。其中第 1 部分的基础分类网络计算是所有 RoIs 共享的,只需要进行一次前向计算即可得到所有 RoIs 所对应的特征图。
第 2 部分的 RoI-wise subnetwork 不是所有 RoIs 共享的,这一部分的作用就是给每个 RoI 进行分类和回归。在模型进行预测时基础网络不能有效感知位置信息,因为常见的 CNN 结构是根据分类任务进行设计的,并没有针对性的保留图片中物体的位置信息。而第 2 部分的全连阶层更是一种对于位置信息非常不友好的网络结构。由于检测任务中物体的位置信息是一个很重要的特征,R-FCN 通过提出的位置敏感分数图(position sensitive score maps)来增强网络对于位置信息的表达能力,提高检测效果。
网络设计
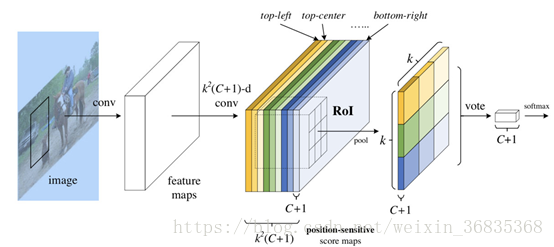
position-sensitive score map
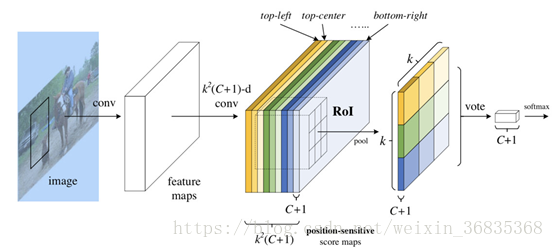
图中展示的是 R-FCN 的网络结构图,展示了位置敏感得分图(position-sensitive score map)的主要设计思想。如果一个 RoI 含有一个类别 c 的物体,则将该 RoI 划分为 k x k 个区域,分别表示该物体的各个相应部位。其每个相应的部位都由特定的特征图对其进行特征提取。R-FCN在 、共享卷积层的最后再接上一层卷积层,而该卷积层就是位置敏感得分图 position-sensitive score map。其通道数 channels=k x k x (C+1)。C 表示物体类别种数再加上 1 个背景类别,每个类别都有 k x k 个 score maps 分别对应每个类别的不同位置。每个通道分别负责某一类的特定位置的特征提取工作。
Position-sensitive RoI pooling
位置敏感RoI池化操作了(Position-sensitive RoI pooling)如下图所示:
该操作将每个 RoIs 分为 k x k 个小块。之后提取其不同位置的小块相应特征图上的特征执行池化操作,下图展示了池化操作的计算方式。
得到池化后的特征后,每个 RoIs 的特征都包含每个类别各个位置上的特征信息。对于每个单独类别来讲,将不同位置的特征信息相加即可得到特征图对于该类别的响应,后面即可对该特征进行相应的分类。
position-sensitive regression
在位置框回归阶段仿照分类的思路,将特征通道数组合为 4 x k x k 的形式,其中每个小块的位置都对应了相应的通道对其进行位置回归的特征提取。最后将不同小块位置的四个回归值融合之后即可得到位置回归的响应,进行后续的位置回归工作。
网络训练
position-sensitive score map高响应值区域
在训练的过程中,当 RoIs 包涵物体属于某类别时,损失函数即会使得该 RoIs 不同区域块所对应的响应通道相应位置的特征响应尽可能的大,下图展示了这一过程,可以明显的看出不同位置的特征图都只对目标相应位置的区域有明显的响应,其特征提取能力是对位置敏感的。

训练和测试过程
使用如上的损失函数,对于任意一个 RoI,计算它的 Softmax 损失,和当其不属于背景时的回归损失。因为每个RoI都被指定属于某一个 GT box 或者属于背景,即先让 GT box 选择与其 IoU 最大的那个 RoI,再对剩余 RoI 选择与 GT box 的 IoU>0.5 的进行匹配,而剩下的 RoI 全部为背景类别。当 RoI 有了 label 后 loss 就可以计算出来。这里唯一不同的就是为了减少计算量,作者将所有 RoIs 的 loss 值都计算出来后,对其进行排序,并只对最大的 128 个损失值对应的RoIs进行反向传播操作,其它的则忽略。并且训练策略也是采用的 Faster R-CNN 中的 4-step alternating training 进行训练。在测试的时候,为了减少 RoIs 的数量,作者在 RPN 提取阶段就将 RPN 提取的大约 2W 个 proposals 进行过滤:
1.去除超过图像边界的proposals
2.使用基于类别概率且阈值IoU=0.3的NMS过滤
3.按照类别概率选择top-N个proposals
在测试的时候,一般只剩下300个RoIs。并且在R-FCN的输出300个预测框之后,仍然要对其使用NMS去除冗余的预测框。
算法效果
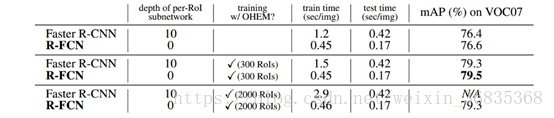
该图比较了 Faster-R-CNN 和 R-FCN 的 mAP 值和监测速度,采用的基础网络为 ResNet-101,测评显卡为 Tesla K40。
1.2-FCN-3000 at 30fps: Decoupling Detection and Classification
论文链接:arxiv.org/abs/1712.01802
开源代码:/
录用信息:/
论文目标
YOLO9000 将检测数据集和分类数据集合并训练检测模型,但 r-fcn-3000 仅采用具有辅助候选框信息的 ImageNet 数据集训练检测分类器。
如果使用包含标注辅助信息(候选框)的大规模分类数据集,如 ImageNet 数据集,进行物体检测模型训练,然后将其应用于实际场景时,检测效果会是怎样呢?how would an object detector perform on "detection"datasets if it were trained on classification datasets with bounding-box supervision?
核心思想
r-fcn-3000 是对 r-fcn 的改进。上文提到,r-fcn 的 ps 卷积核是 per class 的,假设有 C 个物体类别,有 K*K 个 ps 核,那么 ps 卷积层输出 K*K*C 个通道,导致检测的运算复杂度很高,尤其当要检测的目标物体类别数较大时,检测速度会很慢,难以满足实际应用需求。
为解决以上速度问题,r-fcn-3000 提出,将 ps 卷积核作用在超类上,每个超类包含多个物体类别,假设超类个数为 SC,那么ps卷积层输出 K*K*SC 个通道。由于 SC 远远小于 C,因此可大大降低运算复杂度。特别地,论文提出,当只使用一个超类时,检测效果依然不错。算法网络结构如下:
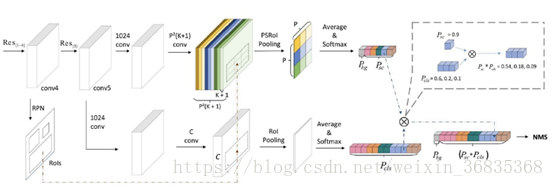
上图可以看出,与 r-fcn 类似,r-fcn-3000 也使用 RPN 网络生成候选框(上图中虚线回路);相比 r-fcn,r-fcn-3000 的网络结构做了如下改进:
1. r-fcn-3000 包含超类(上图中上半部分)和具体类(上图中下半部分)两个卷积分支。
2. 超类卷积分支用于检测超类物体,包含分类(超类检测)和回归(候选框位置改进)两个子分支;注意上图中没有画出用于候选框位置改进的 bounding-box 回归子分支;回归分支是类别无关的,即只确定是否是物体。
3. 具体类卷积分支用于分类物体的具体类别概率,包含两个普通 CNN 卷积层。
4. 最终的物体检测输出概率由超类卷积分支得到的超类类概率分别乘以具体类卷积分支输出的具体类别概率得到。引入超类和具体类两个卷积分支实现了“物体检测”和“物体分类”的解耦合。超类卷积分支使得网络可以检测出物体是否存在,由于使用了超类,而不是真实物体类别,大大降低了运算操作数。保证了检测速度;具体类分支不检测物体位置,只分类具体物体类别。
超类生成方式:对某个类别j的所有样本图像,提取 ResNet-101 最后一层 2018 维特征向量,对所有特征项向量求均值,作为该类别的特征表示。得到所有类别的特征表示进行 K-means 聚类,确定超类。
算法效果
在 imagenet 数据集上,检测 mAP 值达到了 34.9%。使用 nvidia p6000 GPU,对于 375x500 图像,检测速度可以达到每秒 30 张。在这种速度下,r-fcn-3000 号称它的检测准确率高于 YOLO 18%。
此外,论文实验表明,r-fcn-3000 进行物体检测时具有较强的通用性,当使用足够多的类别进行训练时,对未知类别的物体检测时,仍能检测出该物体位置。如下图:
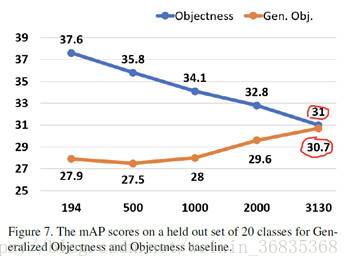
在训练类别将近 3000 时,不使用目标物体进行训练达到的通用预测 mAP 为 30.7%,只比使用目标物体进行训练达到的 mAP 值低 0.3%。
1.3 Mask R-CNN
论文链接:arxiv.org/abs/1703.06870
开源代码:github.com/TuSimple/mx-maskrcnn
录用信息:CVPR2017
论文目标
1. 解决 RoIPooling 在 Pooling 过程中对 RoI 区域产生形变,且位置信息提取不精确的问题。
2. 通过改进 Faster R-CNN 结构完成分割任务。
核心思想
1. 使用RoIAlign代替RoIPooling,得到更好的定位效果。
2. 在Faster R-CNN基础上加上mask分支,增加相应loss,完成像素级分割任务。
概述
Mask R-CNN 是基于 Faster R-CNN 的基础上演进改良而来,不同于 Faster R-CNN,Mask R-CNN 可以精确到像素级输出,完成分割任务。此外他们的输出也有所不同。Faster R-CNN 输出为种类标签和 box 坐标,而 Mask R-CNN 则会增加一个输出,即物体掩膜(object mask)。
网络结构介绍:
Mask R-CNN 结构如下图:
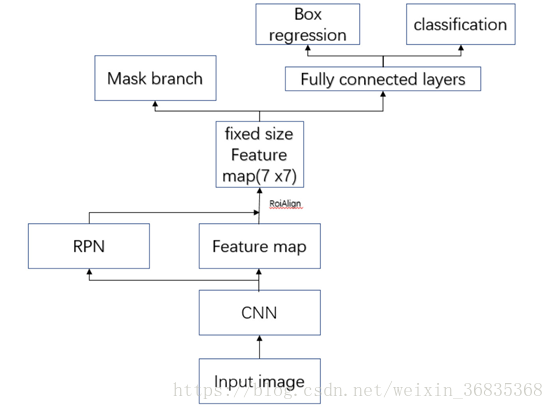
Mask R-CNN 采用和 Faster R-CNN 相同的两个阶段,具有相同的第一层(即 RPN),第二阶段,除了预测种类和 bbox 回归,并且并行的对每个 RoI 预测了对应的二值掩膜(binary mask)。
Mask R-CNN详细改进
RoIAlign
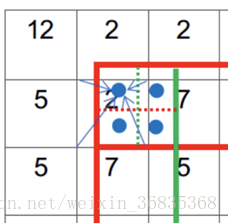
Faster R-CNN 采用的 RoIPooling,这样的操作可能导致 feature map 在原图的对应位置与真实位置有所偏差。如下图:
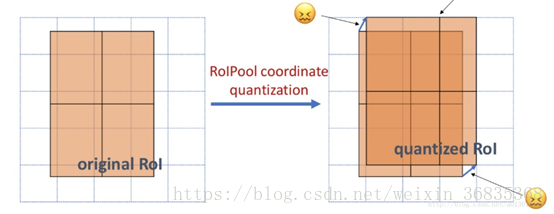
而通过引入 RoIAlign 很大程度上解决了仅通过 Pooling 直接采样带来的 Misalignment 对齐问题。
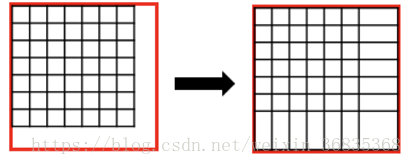
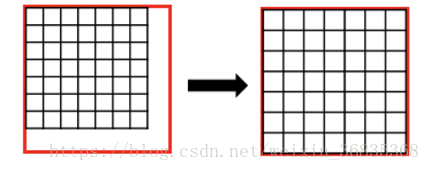
RoIPooling 会对区域进行拉伸,导致区域形变。RoIAlign 可以避免形变问题。具体方式是先通过双线性插值到 14 x 14,其次进行双线性插值得到蓝点的值,最后再通过 max Pooling 或 average pool 到 7 x 7。
多任务损失函数
Mask R-CNN 的损失函数可表示为:
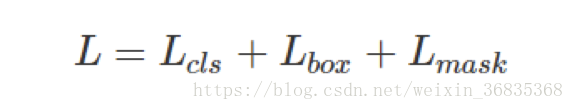
其中 和
与Faster R-CNN中的相似,所以我们具体看
损失函数。
掩膜分支针对每个 RoI 产生一个 K x M xM 的输出,即 K 个 M x M 的二值的掩膜输出。其中K为分类物体的类别数目。依据预测类别输出,只输出该类对应的二值掩膜,掩膜分支的损失计算如下示意图:
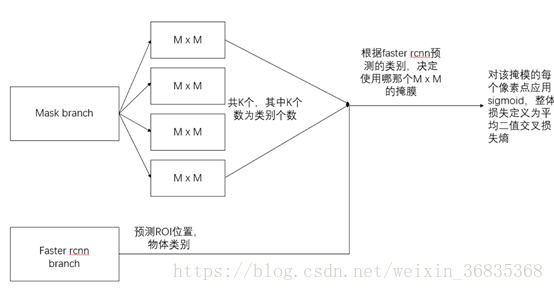
图 16
1. mask branch 预测 K 个种类的 M x M 二值掩膜输出。
2. 依据种类预测分支(Faster R-CNN 部分)预测结果:当前 RoI 的物体种类为 i。
3 RoI 的平均二值交叉损失熵(对每个像素点应用 Sigmoid 函数)即为损失 。
此外作者发现使用 Sigmoid 优于 Softmax ,Sigmoid 可以避免类间竞争。
算法效果
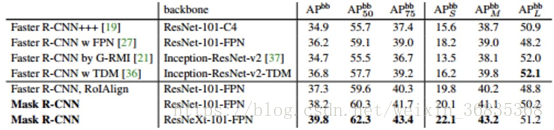
图 17
体现了在 COCO 数据集上的表现效果。