一、选择排序
原理:首先在未排序序列中找到最小(最大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到已排序序列的末尾,以此类推,直到所有元素排序完毕。
过程和演示如下:


实现:
def selection_sort(li):
'''选择排序'''
n = len(li)
#选择次数
for i in range(n - 1):
#记录最小值的位置
min_index = i
#从min_index位置到末尾找到最小值对应的下标,与min_index交换
for j in range(min_index,n):
if li[j] < li[min_index]:
min_index = j
#交换
li[i],li[min_index] = li[min_index],li[i]
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
selection_sort(li)
print(li)
进行测试,结果为[17, 20, 26, 31, 44, 54, 55, 77, 93]。
算法分析:
1.选择排序的主要优点与数据移动有关。如果某个元素位于正确的最终位置上,则它不会被移动。选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对n个元素的表进行排序总共进行至多**(n-1)**次交换。在所有的完全依靠交换去移动元素的排序方法中,选择排序属于非常好的一种。
2.选择排序是不稳定的。选择排序是给每个位置选择当前元素最小的,比如给第一个位置选择最小的,在剩余元素里面给第二个元素选择第二小的,依次类推,直到第n-1个元素,第n个元素不用选择了,因为只剩下它一个最大的元素了。那么,在一趟选择,如果当前元素比一个元素小,而该小的元素又出现在一个和当前元素相等 的元素后面,那么交换后稳定性就被破坏了。举个例子,序列5 8 5 2 9,第一遍选择第1个元素5会和2交换,那么原序列中2个5的相对前后顺序就被破坏了,所以选择排序不是一个稳定的排序算法。
二、插入排序:
插入排序(Insertion Sort),是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
实现原理:
首先,我们将数组中的数据分为两个区间,已排序区间和未排序区间。初始已排序区间只有一个元素,就是数组的第一个元素。插入算法的核心思想是取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。重复这个过程,直到未排序区间中元素为空,算法结束。
如下图所示,要排序的数据是 4,5,6,1,3,2,其中左侧为已排序区间,右侧是未排序区间。

动态演示如下,

实现:
方法一:
def insert_sort_1(li):
n = len(li)
#从第二个位置,即下标为1的位置开始向前插入
for i in range(1,n):
#从第i个元素,向前比较,如果小于前一个元素,则交换
for j in range(i,0,-1):
if li[j] < li[j-1]:
#交换
li[j],li[j-1] = li[j-1],li[j]
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
insert_sort_1(li)
print(li)
进行测试,结果为[17, 20, 26, 31, 44, 54, 55, 77, 93]。
方法二:
def insert_sort_2(li):
n = len(li)
#从第二个位置,即下标为1的位置开始向前插入
for i in range(1,n):
j = i
#从第i个元素,向前比较,如果小于前一个元素,则交换
while j > 0:
if li[j] < li[j-1]:
#交换
li[j],li[j-1] = li[j-1],li[j]
j -= 1
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
insert_sort_2(li)
print(li)
结果与方法一相同。
算法分析:
从代码中可以看出一共遍历了n-1 + n-2 + … + 2 + 1 = n * (n-1) / 2 = 0.5 * n ^ 2 - 0.5 * n,那么时间复杂度是O(N2);
因为在有序部分元素和待插入元素相等的时候,可以将待插入的元素放在前面,所以插入排序是稳定的。
是稳定的。
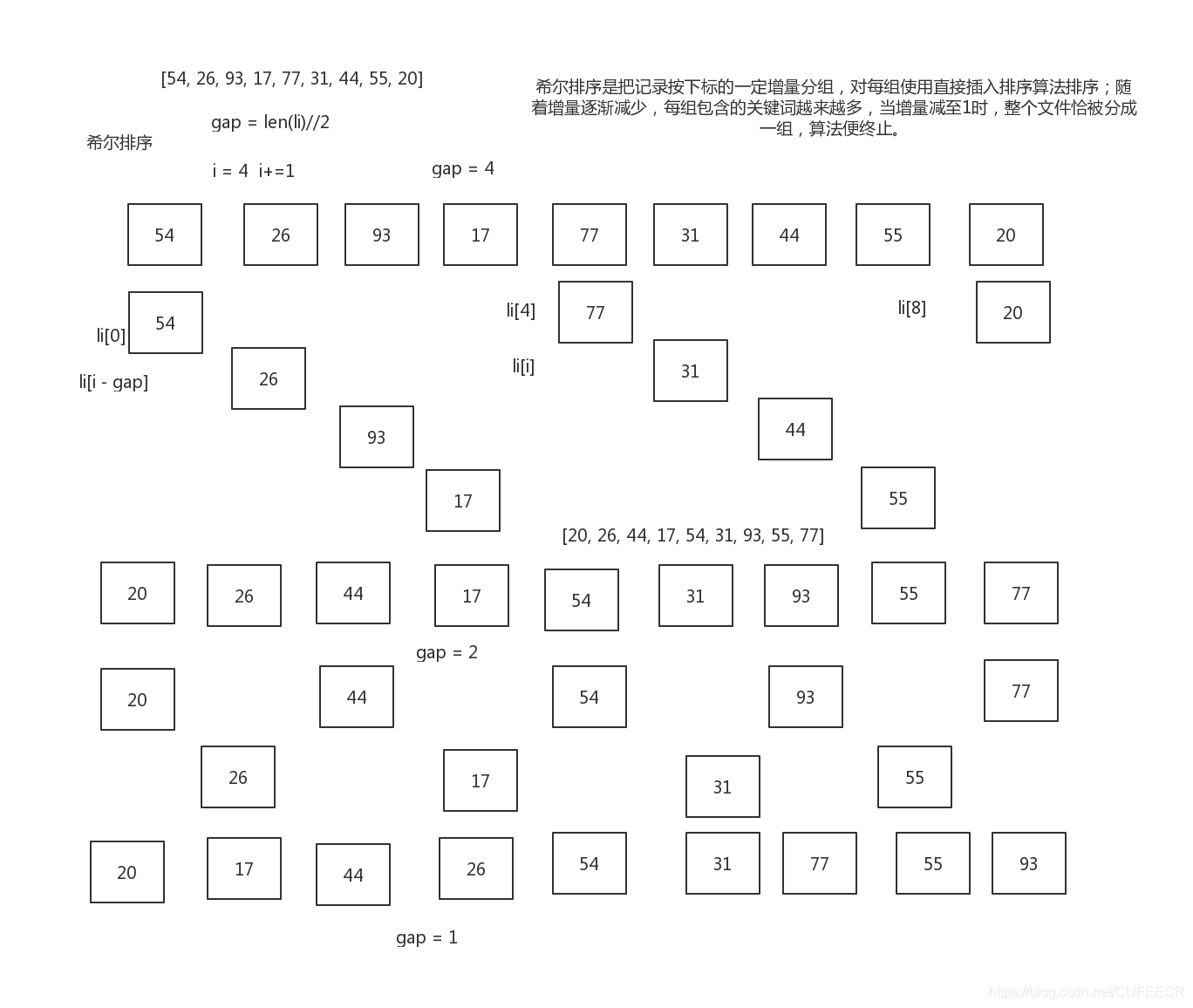
三、希尔排序
是插入排序的一种,也称缩小增量排序,是直接排序算法的一种更高效的改进版本。
希尔排序是非稳定排序算法。
希尔排序(Shell Sort)是插入排序的一种,也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序通过将比较的全部元素分为几个区域来提升插入排序的性能。这样可以让一个元素可以一次性地朝最终位置前进一大步。然后算法再取越来越小的步长进行排序,算法的最后一步就是普通的插入排序,但是到了这步,需排序的数据几乎是已排好的了(此时插入排序较快)。
希尔排序的实质就是分组的插入排序。
工作原理:
将需要排序的序列划分为若干个较小的序列,对这些序列进行直接插入排序,每次排序后用更短的步长、更长的序列循环进行,通过这样的操作可使需要排序的数列基本有序,最后再使用一次直接插入排序。
在希尔排序中首先要解决的是怎样划分序列,对于子序列的构成不是简单地分段,而是采取将相隔某个增量的数据组成一个序列。一般选择增量的规则是:取上一个增量的一半作为此次子序列划分的增量,一般初始值元素的总数量。
对于序列[54, 26, 93, 17, 77, 31, 44, 55, 20],其排序过程大致如下图,
实现:
方法一,
def shell_sort_1(li):
# 初始步长
n = len(li)
gap = n // 2
# 按补偿进行插入排序
while gap > 0:
for i in range(gap,n,gap):
# 插入排序
while i >= gap:
if li[i-gap] > li[i]:
li[i - gap], li[i] = li[i],li[i-gap]
i -= gap
# 得到新的步长
gap = gap // 2
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
shell_sort_1(li)
print(li)
打印结果为[17, 20, 26, 31, 44, 54, 55, 77, 93]。
方法二:
def shell_sort_2(li):
#初始步长
n = len(li)
gap = n // 2
while gap > 0:
#按补偿进行插入排序
for i in range(gap,n,gap):
#插入排序
while i >= gap and li[i - gap] > li[i]:
li[i - gap], li[i] = li[i], li[i - gap]
i -= gap
gap = gap // 2
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
shell_sort_2(li)
print(li)
结果与方法一相同。
方法三:
def shell_sort_3(li):
# 初始步长
n = len(li)
gap = n // 2
# 按补偿进行插入排序
while gap > 0:
for i in range(n-1,gap-1,-1):
j = i
while j >= gap:
# 插入排序
if li[j - gap] > li[j]:
li[j - gap],li[j] = li[j],li[j - gap]
j -= gap
# 得到新的步长
gap = gap // 2
if __name__ == '__main__':
li = [54, 26, 93, 17, 77, 31, 44, 55, 20]
shell_sort_3(li)
print(li)
结果与前两种方法相同,实现希尔排序的方式还有很多,个人比较喜欢第三种,因为很接近希尔排序的定义,方便理解。
算法分析:
1.希尔排序是按照不同步长对元素进行插入排序,当刚开始元素很无序的时候,步长最大,所以插入排序的元素个数很少,速度很快;当元素基本有序了,步长很小,插入排序对于有序的序列效率很高;
2.由于多次插入排序,一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以,希尔排序是不稳定的。
3.最坏时间复杂度为O(n^2)。


大家也可以关注我的公众号:Python极客社区,在我的公众号里,经常会分享很多Python的文章,而且也分享了很多工具、学习资源等。另外回复“电子书”还可以获取十本我精心收集的Python电子书。
