一、冒泡排序
思路:首先将第一个记录的关键字和第二个记录的关键字进行比较,若为逆序,则将两记录交换,然后比较第二个记录和第三个记录的关键字,依次类推,直到第n-1个记录和第n个记录的关键字比较完毕为止。此过程为第一趟冒泡排序,结果使得最大的关键字被放置到最后一个记录的位置上。

图一 冒泡排序示例
代码:
void BubbleSort(int *arr)
{
int len = arr.length;
int i = 0;
int j = 0;
for(i=0; i<len-1; ++i)
{
for(j=0; j<len-1-i; ++j)
{
if(arr[j] > arr[j+1])
{
int tmp = arr[j+1];
arr[j+1] = arr[j];
arr[j] = tmp;
}
}
}
return arr;
}其中时间复杂度为O(),空间复杂度为O(n),稳定性是不稳定的。
稳定:如果a原本在b的前面,而a=b, 排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,a=b, 排序之后a有可能在b的后面。
时间复杂度:对排序数据的总的操作次数。
空间复杂度:指算法在计算机内执行时所需存储空间的度量。
二、选择排序
参考本人另一条博客内容,相关链接为https://blog.csdn.net/qq_41026740/article/details/79706790
三、直接插入排序
思路:以第二个数据开始,插入到数据前已排序好的数据序列中,并使其依旧有序。(示例:扑克调牌)

图二 直接插入排序示例
代码:
void InsertSort(int *arr, int len)
{
int tmp = 0; //tmp保存每次插入的数据
for(int i=1; i<len; ++i)
{
tmp = arr[i];
for(int j=i-1; j>=0; --j)
{
if(arr[j] > tmp)
{
arr[j+1] = arr[j];
}
else
{
break;
}
}
arr[j+1] = tmp;
}
}时间复杂度最坏为O(), 最好为O(n); 空间复杂度为O(1), 稳定性是稳定的。
四、希尔排序
思路:先跨越式分组,使用直接插入排序,使每组数据有序,随着分的组越来越详细,整个数据变得越来越有序,直到分组成员只有1个时,排序完成。
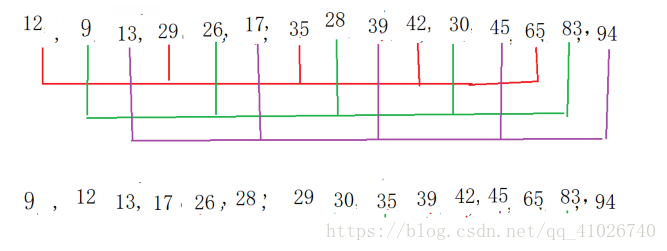
图三 希尔排序示例
代码:
function shellSort(arr) {
var len = arr.length,
temp,
gap = 1;
while (gap < len / 3) { // 动态定义间隔序列
gap = gap * 3 + 1;
}
for (gap; gap > 0; gap = Math.floor(gap / 3)) {
for (var i = gap; i < len; i++) {
temp = arr[i];
for (var j = i-gap; j > 0 && arr[j]> temp; j-=gap) {
arr[j + gap] = arr[j];
}
arr[j + gap] = temp;
}
}
return arr;
}五、快速排序
思路:每选取一个数(待排列数据的第一个数据)作为比较的基准,然后从后往前找比基准小的,将其放在前面空缺位置,其次从前往后找比基准大的数据放在后面空缺位置,直到 i 和 j 相遇。将基准放入 i 位置,基准前的数据都比基准小,基准后的数据都比基准大,然后递归分别处理左半边和右半边。