文章目录
es中字符串类型text(全文本)
导语
从本小节开始我们开始学习es中常用的元数据类型和字段映射,学习和理解它们可以有助于理解es及其工作机制。
其主要分为两大类。
其一,元字段,元字段用于ES对每个文档自带的元数据结构,包括 _index,_type, _id,和_source等等构成。针对这一类,着重讲解它们所代表的意思和一些使用。
其二,就是字段类型(也叫属性),其包括的类型比较多,如下图所示,这部分也是我们开发最常使用的使用,尤其string,数组,对象,集合等等都是很常用,所以也是我们重点关注的知识点。
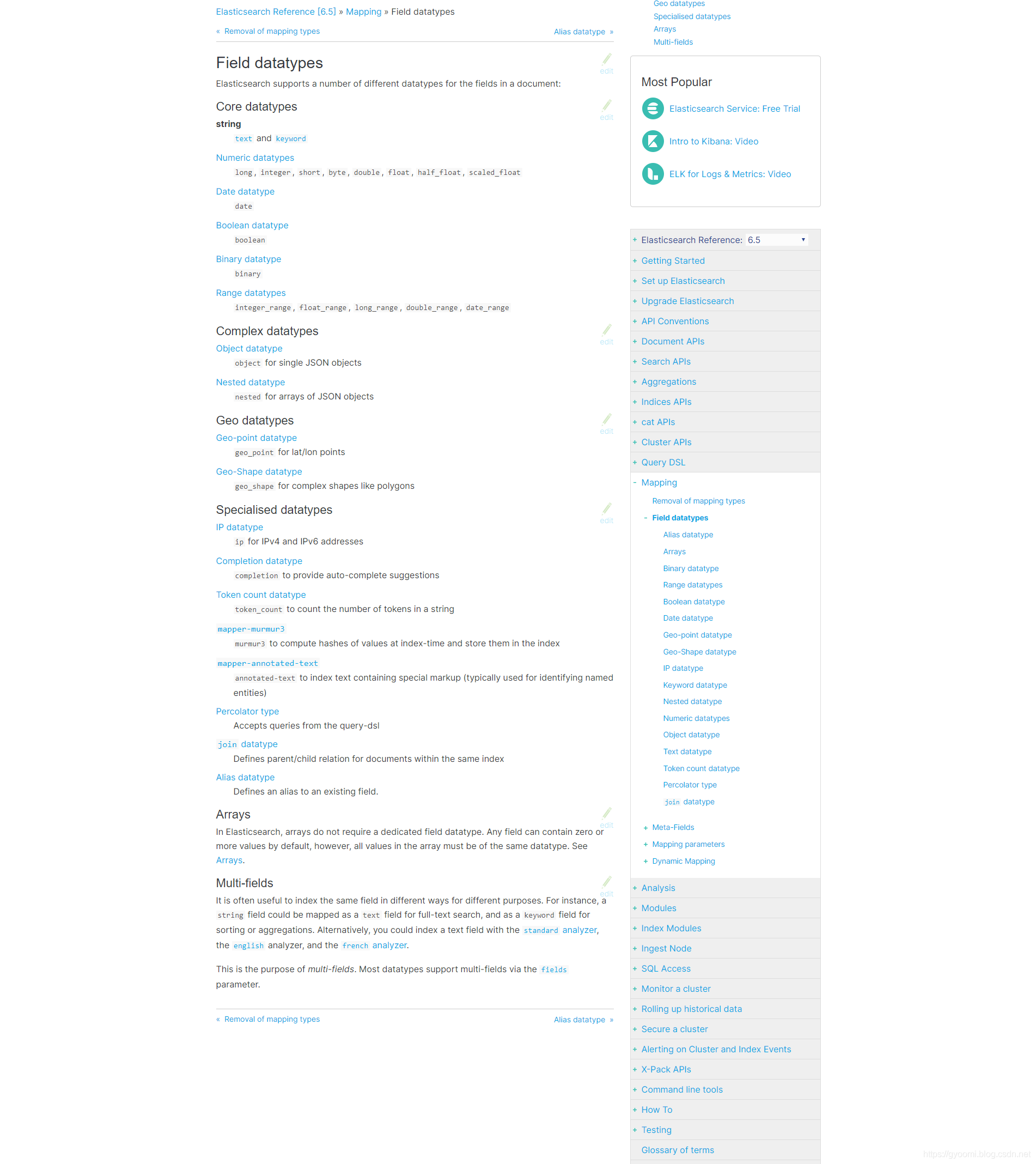
分类
字符串包括text和keyword两种类型。
全文本(text)
全文本。通常用于基于文本的相关性搜索。全文本字段可以分词,即在索引执行之前通过一个分词器将字符串转换为单词列表。分词操作使得es可以在全文本字段上搜索单词。全文本字段不用于排序,很少用于聚合等操作。
示例代码
#创建索引
PUT example2
#添加映射
PUT example2/docs/_mapping
{
"properties": {
"name":{
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart",
"index":"true",
"store":"true"
},
"headImg":{
"type":"text",
"index":"false",
"store":"true"
},
"descripton":{
"type":"text",
"index":"false",
"store":"false"
}
}
}
#查询映射
GET example2/docs/_mapping
下面我们来解释上面那一段话。
-
通过
analyzer属性指定分词器。上边指定了name字段的analyzer是指在索引使用ik_max_word,搜索时使用ik_smart。对于ik分词器建议是索引时使用ik_max_word将搜索内容进行细粒度分词,搜索时使用ik_smart提高搜索精确性。 -
通过
index属性指定是否索引。默认为index=true,即要进行索引,只有进行索引才可以从索引库搜索到。但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将index设置为false。 -
通过
store属性来决定是否在source之外存储。默认store=false,每个文档索引后会在 ES中保存一份原始文档,存放在"_source"中,一般情况下不需要设置store为true,因为在_source中已经有一份原始文档了。 -
通过
fields属性,可以对同一个字段进行多种策略的索引。通常为一个字段可以设置一个全文本字段,一个精确的keyword字段类型。示例如下。示例
#添加映射
PUT example2/docs/_mapping
{
"properties": {
"name":{
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart",
"index":"true",
"store":"true",
"fields": {
"noAnalyzerName": {
"type": "keyword"
},
"analyzerName": {
"type": "text",
"analyzer":"ik_max_word",
}
}
},
"headImg":{
"type":"text",
"index":"false",
"store":"true"
}
}
}
例如上述的name的配置的2种索引的策略。
