- 介绍
stanford NLP 拿过全球分词第一名,用Java写的,有python接口
jieba只支持中文分词
- 安装:
下载
https://stanfordnlp.github.io/CoreNLP/download.html
解压后
然后再下个中文模型的jar包:
stanford-chinesecorenlp-2018-02-27-models.jar
放到解压后的目录下
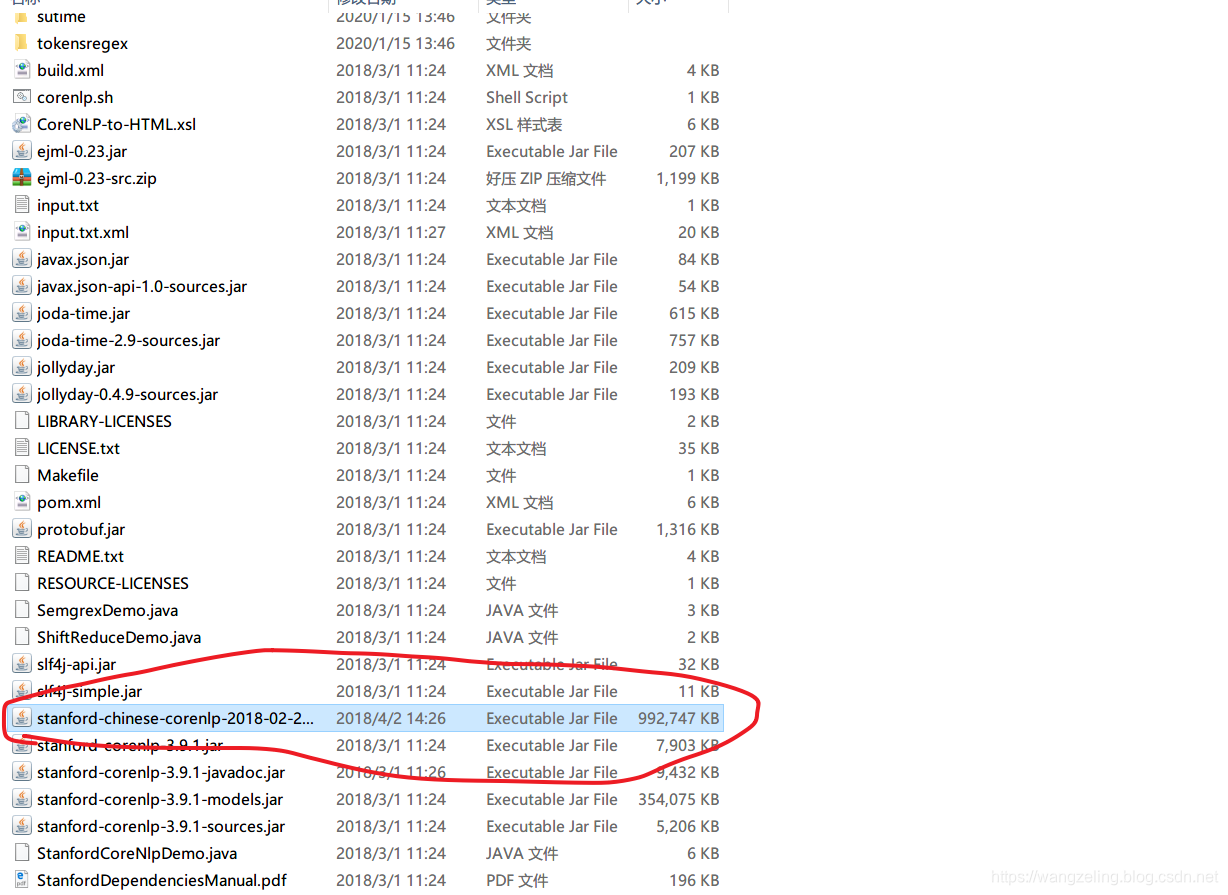
- 简单使用:
from stanfordcorenlp import StanfordCoreNLP
path=r'D:\MyNLPLearningProject\stanford_NLP\stanford-corenlp-full-2018-10-05'
nlp = StanfordCoreNLP(path, lang='zh')
fin=open(r'D:\MyNLPLearningProject\stanford_NLP\news.txt','r',encoding='utf8')
for line in fin:
line=line.strip()
if len(line)<1:
continue
list01=[each[0]+"/"+each[1] for each in nlp.ner(line) if len(each)==2 ]
list02=[each[0]+"/"+each[1] for each in nlp.pos_tag(line) if len(each)==2 ]
print(list01)
print(list02)
