句法分析
句法分析是机器翻译的核心数据结构,是对语言进行深层次理解的基石。
句法分析简介
1.主要任务
识别句子中所包含的句法成分以及这些成分之间的关系,一般以句法树来表示句法分析的结果。
2.主要难点
歧义
搜索空间
3.句法分析分类
完全句法分析:企图获取整个句子的句法结构
部分句法分析:只关注局部的一些成分
4.相关方法
基于规则
存在着语法规则覆盖有限、系统可迁移差等缺陷
基于统计(主流)
数据集与评测方法
数据集
与别的语言处理所需要的数据集不同,句法分析需要的是一种树形的标注结构,又称为树库,如下图所示:
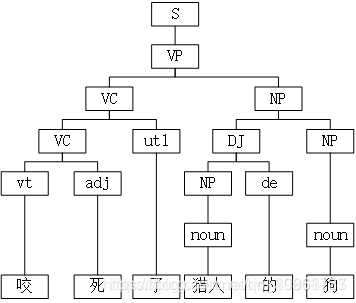
最常使用的树库为美国宾夕法尼亚大学的英文宾州树库PTB,中文树库则包括CTB、TCT和台湾中研院树库。
评测方法
主要任务是评测句法分析生成的树结构与手工标记的树结构之间的相似性程度。
1.满意度:测试句法分析器是否适合或胜任某个特定的自然语言处理任务
2.效率:运行时间
主流的评测方法是PARSEVAL评测体系,主要考察准确率、召回率、交叉括号数。其中交叉括号表示分析得到的某一个短语的覆盖范围与标准句法分析结果的某个短语的覆盖范围存在交叉又不包含的关系,即构成一个交叉括号。
句法分析的常用方法
基于PCFG的句法分析
PCFG基于概率的短语结构分析方法,是一种上下文无关文法的扩展
PCFG处理的问题
1.计算分析树的概率值
2.若一个句子有多个分析树,依据概率进行排序
3.可用来进行句法排歧
PCFG五元组表示(X,V,S,R,P)(X,V,S,R,P)
1.XX是一个有限词汇的集合(词典),其元素称为词汇或终结符
2.VV是一个有限标注的集合,称为非终结符
3.SS包含于VV,称为文法的开始符号
4.RR是有序对(α,β)(α,β)的集合,也就是产生的规则集
5.PP表示每个产生规则的统计概率
PCFG运算表示
1.形式:A→α,PA→α,P
2.约束:∑αP(A→α)
基于最大间隔马尔可夫网络的句法分析
基于最大间隔马尔可夫网络的句法分析是一种判别式的句法分析方法,通过丰富特征来消除歧义。
判别函数:
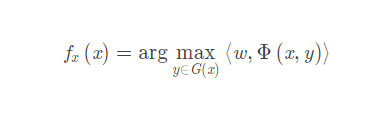
其中Φ(x,y)Φ(x,y)表示与xx相对应的句法树yy的特征向量,ww表示特征权重
基于CRF的句法分析
将句法分析作为序列标注问题来解决,可以使用CRF模型
也是判别式方法,需要融合大量特征
与PCFG的区别
1.概率计算方法和概率归一化方法不同
2.CRF模型最大化的是句法树的条件概率而非联合概率
基于移进-归约的句法分析模型
移进-规约法是一种自下而上的方法,操作的基本数据结构是堆栈。
主要操作(SS表示句法树的根节点)
1.移进:从句子左端将一个终结符移至栈顶
2.归约:根据规则,将栈顶的若干字符替换为一个字符
3.接收:句子中所有词都已入栈,且栈中只剩下一个符号SS,则分析成功
4.拒绝:句子中所有词都已入栈,且栈中并非只有一个符号SS,也无法进行任何归约操作,则分析失败
使用Stanford Parser的PCFG算法实现句法分析
Stanford Parser
Stanford Parser是基于Java的,所以需要jdk环境
Stanford Parser是封装在nltk库中实现的,所以要先安装nltk
需要下载Stanford Parser的jar包:https://nlp.stanford.edu/software/lex-parser.shtml#Download
我的百度云地址:链接:https://pan.baidu.com/s/1YkKZytQ84UqPKGQh4m77Ug
提取码:9u1o
需要三个文件:
stanford-parser-4.0.0-models.jar
stanford-parser.jar
chinesePCFG.ser.gz(中文句法分析)
注意:如果是英文句法分析,需要englishPCFG.ser.gz,而不是chinesePCFG.ser.gz
获取上述三个文件:解压刚下载的压缩包(stanford-parser-4.0.0.zip),从中找到stanford-parser-4.0.0-models.jar和stanford-parser.jar文件。再将stanford-parser-4.0.0-models.jar文件解压,chinesePCFG.ser.gz文件就藏在stanford-parser-4.0.0-models.jar文件中,一直单击\edu\stanford\nlp\models\lexparser,就可以找到chinesePCFG.ser.gz文件。
简单示例
我们对“他骑自行车去了菜市场”进行句法分析。
分词
这里我们采用Jieba分词,代码如下:
######Jieba分词######
import jieba
string='我爱NLP'
seg_list=jieba.cut(string,cut_all=False,HMM=True)
seg_str=' '.join(seg_list)
print(seg_str)
结果如下所示:
我 爱 NLP
PCFG句法分析
下面进行句法分析,代码如下所示:
######PCFG句法分析######
from nltk.parse import stanford
import os
root='file/stanford-parser-4.0.0/'
parser_path=root+'stanford-parser.jar'
model_path=root+'stanford-parser-4.0.0-models.jar'
# 指定JDK路径
if not os.environ.get('JAVA_HOME'):
JAVA_HOME = 'C:\Program Files\Java\jdk1.8.0_45'
os.environ['JAVA_HOME'] = JAVA_HOME
##PCFG模型路径
pcfg_path='file/stanford-parser-4.0.0/edu/stanford/nlp/models/lexparser/chinesePCFG.ser.gz'
parser=stanford.StanfordParser(path_to_jar=parser_path,path_to_models_jar=model_path,model_path=pcfg_path)
sentence=parser.raw_parse(seg_str)
for line in sentence:
print(line)
line.draw()
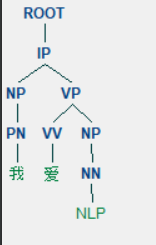
ROOT:要处理文本的语句
IP:简单从句
NP:名词短语
VP:动词短语
PN:代词
VV:动词
NN:常用名词