平滑方法:
1. Add-1 smoothing
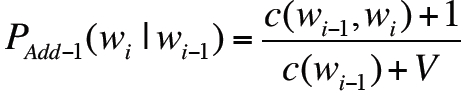
2. Add-k smoothing

设m=1/V,则有
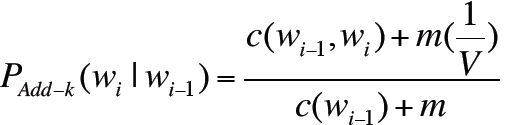
从而每一项可以跟词汇表的大小相关
3. Unigram prior smoothing
将上式中的1/v换成unigram概率P(wi),则有:
![]()
其是插值的一种变体,其将某种unigram概率加入到bigram的计算中。
4. Good-Turing Smoothing
大部分平滑算法比如Good-Turing、Kneser-Ney、Witten-Bell采用的主要思想是用之前已知的数据的计数来预测未知的数据的计数,旨在将未知的0值用其他数值替代。
下面是具体方法:
![]()
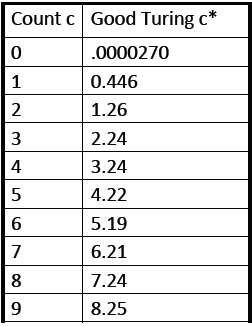
表示频率c出现的次数,然后将其应用到Good-Turing平滑算法中,如下:
假设你在钓鱼,然后抓到了:
![]()
1)下一条鱼是trout的概率是多少?
答:1/18
2)下一条鱼是新的品种的概率是多少?
答:3/18,因为N1=3
3)下一条鱼是trout的概率是多少
答:小于1/18,因为还有一部分概率3/18是留给新的品质的鱼的。具体数值使用Good Turing方法计算。
MLE:最大似然概率
具体方法:
设有一个大小为c的训练集,然后从c个词中抽取一个词作为留存数据,则原数据集大小变为c-1,然后在原训练集中抽取另一词作为留存数据,迭代重复抽取过程,重复c次,则得到c个c-1大小的训练集和大小为1的留存数据集,如下:
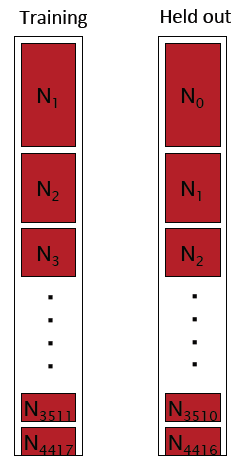
如此,假设每个留存数据在原训练集中出现r次,则抽取之后该留存数据在对应现数据集中出现r-1次,则原Nr即计数为r的词的频次需要减一,而Nr-1即计数为r-1的词的频次需要加1,从而有以上对应内容,即现对应Nr-1的内容为原Nr的内容。
那么
1)有多少比例的留存数据在训练集中是不可见的:N1/C
2)有多少比例的留存书籍在训练集中出现了k次:![]()
所以我们预计会出现![]() 个词,其出现频次在训练集中为k。
个词,其出现频次在训练集中为k。
又因为在训练数据集中出现k次的词一共有Nk个,所以每个词出现的概率为:![]()
或者写作:![]()
但是有一个问题,可能Nk+1与Nk的值差的非常大,那么以上计算方法就容易不准确。
实际上语料库中Nk的分布可能如下所示:
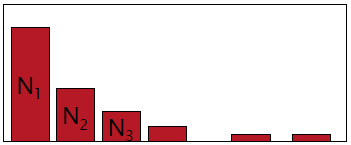
可能出现频次非常大的N4417中只有一个“the”这个词。
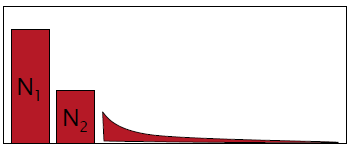
所以在Simple Good-Turing中在计数是除了最开始的几项,后续的采用合适的拟合曲线来表征,如下:
5. Kneser-Ney Smoothing
上述Good-Turing Smoothing方法中,对于每一项的计数做了一下调整:
![]() ,从而有:
,从而有:
可以发现每一项的新值其实差不多为![]()
即差值是固定的,那么我们可以直接应用这种固定的差值(也称之为折扣),称之为absolute discounting绝对折扣法。
· Absolute Discounting Interpolation

d是一个固定的数值,即折扣。但是关键在于应用unigram的项是否恰当,所以有:
· Kneser-Ney 概率forunigram
当我们要预测下一个词的时候,比如:I cant see withon my reading ______
实际上应该是glasses,但是如果单单按照unigram频次的话,Francisco更有可能,因为其频次更高。然后Fancisco一般是紧随着San出现的,所以unigram只有在我们不知道bigram的时候才有用.
所以我们不应该只简单地问P(w):"是w这个词的可能性是多少",而是应该问![]() :“w能组成一种新的‘延续’的可能性是多少”,那么如何计算这个概率呢?
:“w能组成一种新的‘延续’的可能性是多少”,那么如何计算这个概率呢?
· 对于每个词,计算它紧跟着另一个词所组成的不同的bigram类型的数目
· 每个第一次出现的bigram即是一种新的‘延续’,其概率与能跟w组成bigram的词的集合大小成比例:
![]()
再用整体bigram类型数目![]() 做正则化:
做正则化:

在Kneser-Ney Smoothing中写作:
与w组成bigram的前驱单词数目=![]()
用所有bigram数目做正则化,则有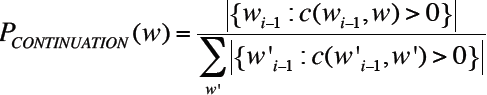
结合以上absolute discounting和Kneser-Ney 概率forunigram,则有:
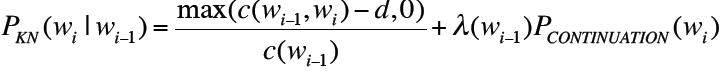
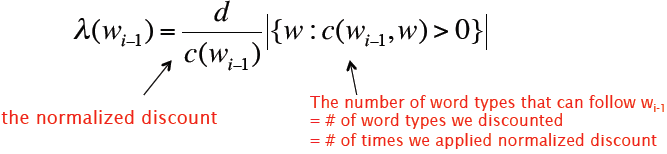
以上是Kneser-Ney Smoothing对于bigram的计算方式,以下则是对通用N-gram的计算方法:
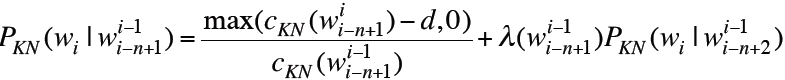
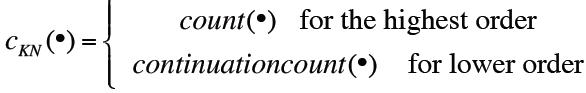
![]()